Spark任务调度
2017-06-04 18:25
309 查看
不多说,直接上干货!
[b]Spark任务调度[/b]
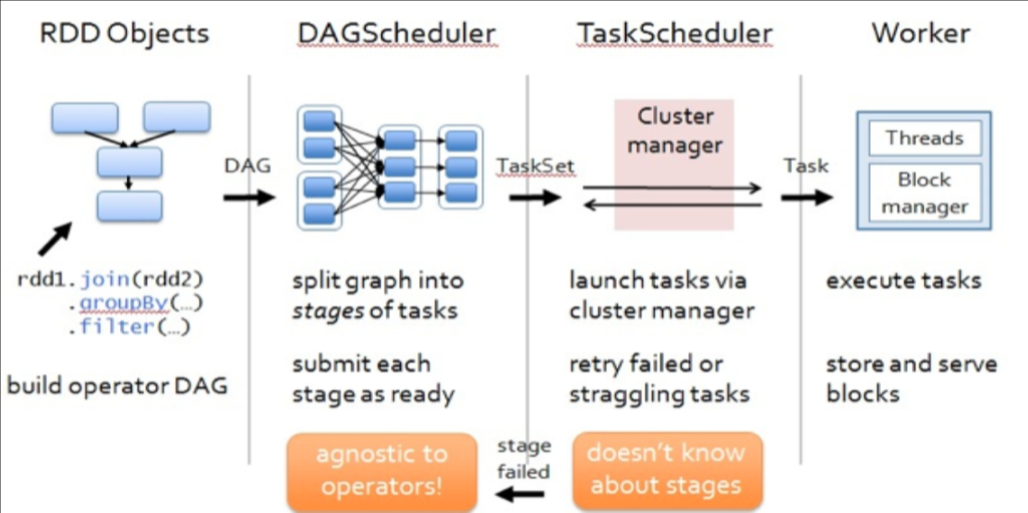
[b]DAGScheduler[/b]
构建Stage—碰到shuffle就split
记录哪个RDD 或者Stage 输出被物化
重新提交shuffle 输出丢失的stage
将Taskset 传给底层调度器
本地性策略--- preferredLocations(p)
[b]TaskScheduler[/b]
为每一个TaskSet 构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
数据本地性决定每个Task 最佳位置(process-local, node-local, rack-local and then and any
提交taskset( 一组task) 到集群运行并监控
推测执行,碰到straggle 任务放到别的节点上重试
出现shuffle 输出lost 要报告fetch failed 错误
[b]ScheduleBacked[/b]
实现与底层资源调度系统的交互(YARN,mesos等)
配合TaskScheduler实现具体任务执行所需的资源分配(核心接口receiveOffers)
详细过程
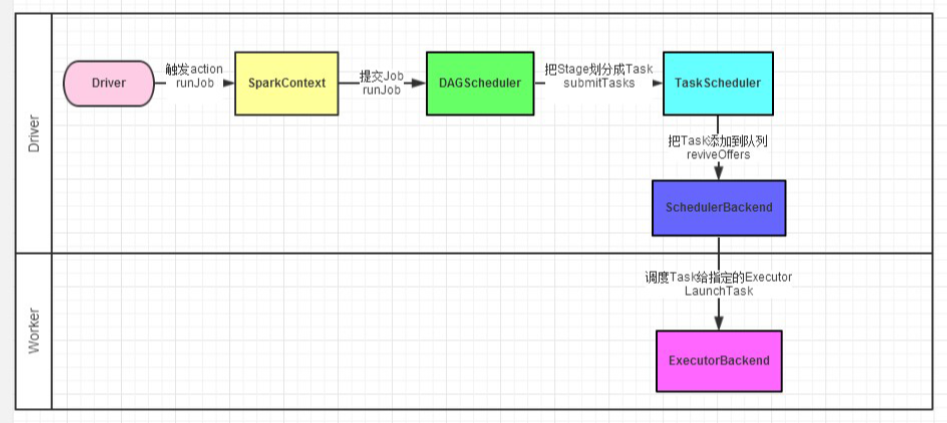

[b]Spark任务调度[/b]
[b]DAGScheduler[/b]
构建Stage—碰到shuffle就split
记录哪个RDD 或者Stage 输出被物化
重新提交shuffle 输出丢失的stage
将Taskset 传给底层调度器
本地性策略--- preferredLocations(p)
1.spark-cluster TaskScheduler 2.yarn-cluster YarnClusterScheduler 3.yarn-client YarnClientClusterScheduler
[b]TaskScheduler[/b]
为每一个TaskSet 构建一个TaskSetManager 实例管理这个TaskSet 的生命周期
数据本地性决定每个Task 最佳位置(process-local, node-local, rack-local and then and any
提交taskset( 一组task) 到集群运行并监控
推测执行,碰到straggle 任务放到别的节点上重试
出现shuffle 输出lost 要报告fetch failed 错误
[b]ScheduleBacked[/b]
实现与底层资源调度系统的交互(YARN,mesos等)
配合TaskScheduler实现具体任务执行所需的资源分配(核心接口receiveOffers)
详细过程
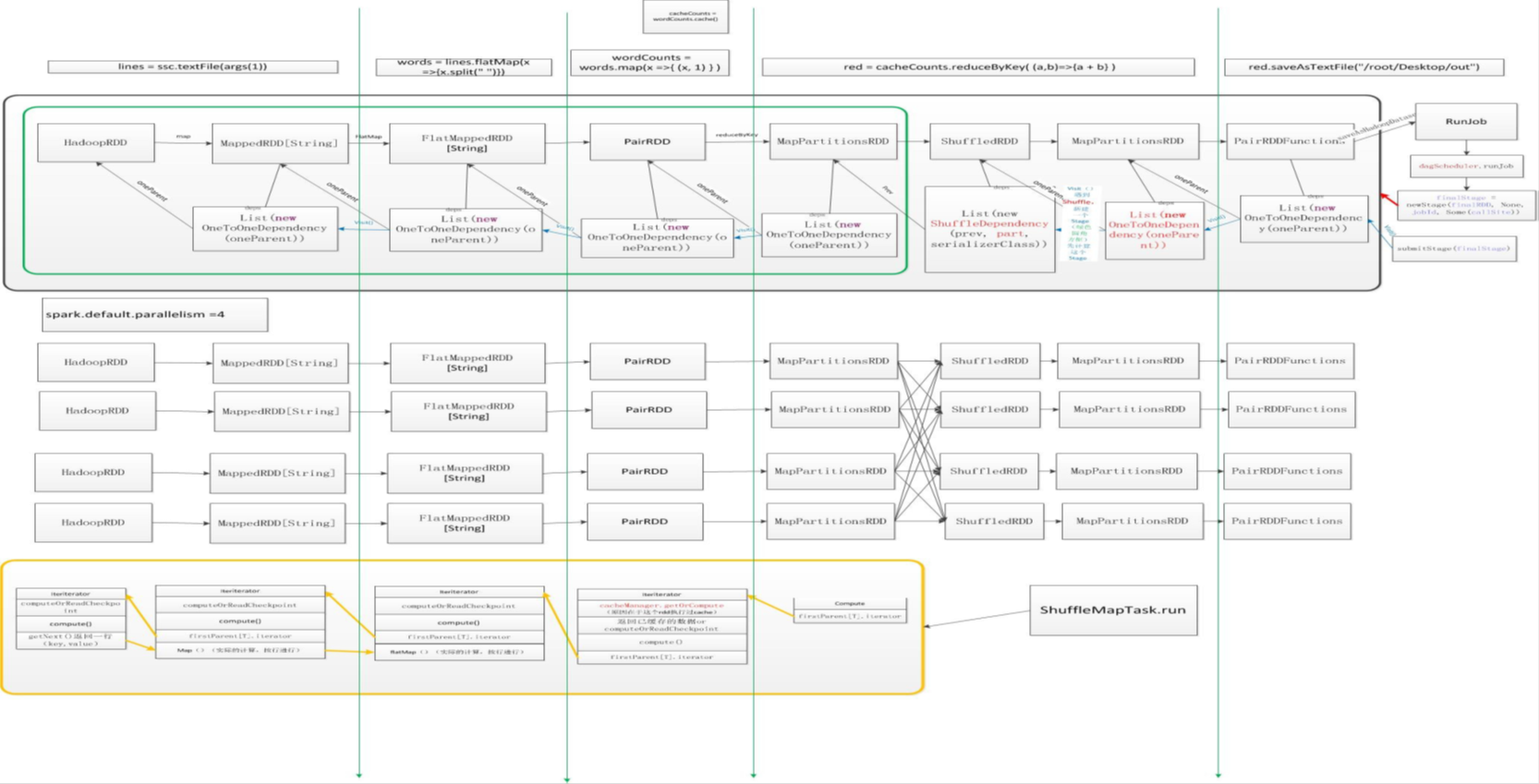
实例分析
val lines = ssc.textFile(args(1)) // 输入
val words = lines.flatMap(x =>x.split(" "))
words.cache() // 缓存
val wordCounts = words.map(x =>(x, 1) )
val red = wordCounts.reduceByKey( (a,b)=>{a + b} , 8)
red.saveAsTextFile(“/root/Desktop/out” , 8) // 行动

相关文章推荐
- Spark工作机制-调度与任务分配
- spark内核揭秘-04-spark任务调度系统个人理解
- Spark核心作业调度和任务调度之DAGScheduler源码
- spark源码之Job执行(2)任务调度taskscheduler
- Spark 资源调度及任务调度
- spark内核揭秘-04-spark任务调度系统个人理解
- [spark] 从spark-submit开始解析整个任务调度流程
- 深入Spark内核:任务调度(1)-基本流程
- Spark核心作业调度和任务调度之DAGScheduler源码
- spark源码之Job执行(2)任务调度taskscheduler
- Spark核心作业调度和任务调度之DAGScheduler源码
- spark源码之Job执行(2)任务调度taskscheduler
- Spark入门——3:Spark的任务调度
- Spark学习笔记 --- 任务调度的逻辑图
- spark2.2以后版本任务调度将增加黑名单机制
- Spark核心作业调度和任务调度之DAGScheduler源码
- spark源码之Job执行(2)任务调度taskscheduler
- Spark核心作业调度和任务调度之DAGScheduler源码
- Spark 任务调度概述
- spark源码之Job执行(2)任务调度taskscheduler