《数学之美》阅读笔记part1——第1章到第15章
2017-06-03 12:15
127 查看
第1章 文字和语言vs数字和信息
1 信息
用声音来传播信息是通信的一种方式,发出的声音对信息进行编码,声音在空气(信道)中传播到达人耳,人对听到的声音解码得出信息。2 文字和数字
罗塞塔石碑的启示:(1) 信息的冗余是信息安全的保障。
(2) 语言的数据,我们称之为语料,尤其是双语或者多语的对照语料对翻译至关重要,是我们从事机器翻译研究的基础。
数字的解码规则在中国是乘法,200万的写法是2×100×10000;在罗马的规则是加减法——小数字出现在大数字左边为减,右边为加。
3 文字和语言背后的数学
罗马体系的文字中,总体来说,常用字短,生僻字长。意型文字中,常用字笔画少,生僻字笔画多。这复合信息论中的最短编码原理。从字母到词的构词法是词的编码规则,语法是语言的编码和解码规则。
第2章 自然语言处理——从规则到统计
任何一种语言都是一种编码的方式,而语言的语法规则是编解码的算法。1 机器智能
自然语言处理的历史可以追溯到图灵提出图灵测试。1956年麦卡锡、明斯基、罗切斯特、香农等4人提议的达特茅斯夏季人工智能研究会议上提出人工智能的提法。
计算机并不理解自然语言,而是靠数学靠统计实现自然语言处理。
自然语言现象的语法规则能够涵盖的真实语句比例较低,且用计算机解析起来相当困难。计算机对自然语言进行语法分析的算法复杂度高,计算量大。因此采用规则的方法分析真实语句不可行。
2 从规则到统计
The pen is in the box. 和The box is in the pen.上世纪70年代,基于统计的方法的核心模型是通信系统加隐含马尔可夫模型。由于一个语法成分对另一个语法成分的修饰关系可以不是顺序的,而是中间间隔了很多短语的。只有出现了基于有向图的统计模型才能很好地解决复杂的语法分析。
第3章 统计语言模型
自然语言逐渐演变成一种上下文相关的信息表达和传递的方式,因此让计算机处理自然语言,一个基本的问题就是为自然语言这种上下文相关的特性建立数学模型,即统计语言模型。1 用数学的方法描述语言规律
统计模型出发点:一个句子是否合理,就看看它的可能性大小如何,可能性用概率来衡量。二元模型:马尔可夫假设,即假设任意一个词出现的概率只同它前面的一个词有关。用联合概率和边缘概率来算条件概率,使用大数定理。
2 延伸阅读:统计语言模型的工程诀窍
2.1 高阶语言模型
N元模型:N-1阶马尔可夫假设,即假设文本中的每个词和前面N-1个词有关,而与更前面的词无关。实际常用N=3,因为N元模型的大小(或者说空间复杂度)几乎是N的指数函数,即O(|V|N),这里的|V|是一种语言词典的词汇量,一般在几万到几十万个。而用N元模型的速度(或者说时间复杂度)也几乎是一个指数函数,即O(|V|N-1)。马尔可夫假设不能覆盖所有的语言现象,其局限性要用其他一些长程的依赖性来解决。
2.2 模型的训练、零概率问题和平滑方法
大数定理要求有足够的观测值。增加数据量仍会遇到零概率或统计量不足的问题。
若用直接的比值计算概率,大部分条件概率仍然是零,这种模型被称之为“不平滑”。
古德-图灵估计:从概率的总量中分配一个很小的比例给没有看见的事件。
Zipf定律
卡茨退避法和线性插值
2.3 语料的选取问题
选取和模型应用的领域相对应的训练语料。过滤能找到模式的、量比较大的噪音。第4章 谈谈分词
1 中文分词方法的演变
查词典——最少词数的分词理论——统计语言模型解决分词二义性(动态规划问题,用维特比算法快速地找到最佳分词)2 延伸阅读:如何衡量分词的结果
2.1 分词的一致性分词评价方式:和人工分词结果进行比较
当统计语言模型被广泛应用后,不同的分词器产生的结果的差异要远远小于不同人之间看法的差异。
中文分词问题已解决。
2.2 词的颗粒度和层次
在机器翻译中,一般颗粒度大翻译效果好。
由不同的应用自行决定切分的颗粒度:建立一个基本词表和一个复合词表,对两者各建立一个语言模型。
分词的不一致性分为错误和颗粒度不一致,错误分为越界型错误和覆盖型错误。
第5章 隐含马尔可夫模型
1 通信模型
如何根据接收端的观测信号来推测信号源发送的信息呢?从所有的源信息中找到最可能产生出观测信号的那一个信息。2 隐含马尔可夫模型
应用:语音识别、机器翻译、拼写纠错、手写体识别、图像处理、基因序列分4000
析等。
3 延伸阅读:隐含马尔可夫模型的训练
给定一个模型,如何计算某个特定的输出序列的概率——前向-后向算法给定一个模型和某个特定的输出序列,如何找到最可能产生这个输出序列的状态序列——维特比算法
给定足够量的观测数据,如何估计隐含马尔可夫模型的参数(转移概率和生成概率)——
有监督的训练方法:需要大量人工标注的数据
无监督的训练方法:鲍姆-韦尔奇算法
Baum-Welch Algorithm通过不断迭代估计出更好的模型参数,使输出的概率(目标函数)达到最大化,因此这个过程被称为期望值最大化(Expectation-Maximization),简称EM过程。EM过程保证算法一定能收敛到一个局部最优点,但一般不能保证找到全局最优点。
因此,在一些自然语言处理的应用,如词性标注中,这种无监督的算法训练出的模型比有监督的训练得到的模型效果较差,因为前者未必能收敛到全局最优点。但如果目标函数是凸函数(如信息熵),则只有一个最优点,此时EM过程可以找到最佳值。
第6章 信息的度量和作用
1 信息熵
信息熵H——对一个信息系统不确定性的量度,信息论的基础。冗余度
2信息的作用
信息——消除系统不确定性。条件熵
3互信息
互信息——度量两个随机事件“相关性”,即在了解了其中一个Y的前提下,对消除另一个X不确定性所提供的信息量。可将互信息应用在机器翻译中解决词义的二义性。
4延伸阅读
相对熵/交叉熵——衡量两个取值为正数的函数的相似性。完全相同的函数的相对熵等于零。相对熵越大,两个函数差异越大;反之越小。对于概率分布或者概率密度函数,如果取值均大于零,相对熵可以度量两个随机分布的差异性。
应用:看两个常用词是否同义;得出TF-IDF。
5小结
语言模型复杂度——在给定上下文的条件下,句子中每个位置平均可以选择的单词数量。一个模型的复杂度越小,每个位置的词就越确定,模型越好。第七章 贾里尼克和现代语言处理
提出统计语音识别的框架结构
BCJR算法
在约翰·霍普金斯大学建立CLSP(Centerfor Language and Speech Processing)实验室
第八章 简单之美——布尔代数和搜索引擎
1 布尔代数
布尔代数将我们对世界的认识从连续状态扩展到离散状态。2 索引
搜索引擎的索引的原理等价于布尔运算。第9章 图论和网络爬虫
离散数学包括数理逻辑、集合论、图论和近世代数1 图论
起源追溯至欧拉“七桥问题”。图的遍历算法:
广度优先搜索(BFS,尽可能“广”地访问与每个节点直接连接的其他节点)
深度优先搜索(DFS)
2 网络爬虫
散列表记录网页是否下载过的信息3延伸阅读:图论的两点补充说明
七桥问题定理:如果一个图能够从一个顶点出发,每条边不重复地遍历一遍回到这个顶点,那么每一顶点的度必须为偶数。
证明:假设能遍历图的每一条变各一次,则对每个顶点,从某边入从另一边出,进入和离开的顶点次数相同,即每顶点相连的边是成对出现的,所以度为偶数。
网络爬虫
先爬哪个网页后爬哪个的调度程序原理基本为BFS,但下完第一个网站再下第二个而不是先轮流下5%再回头下第二批,又像DFS。
调度系统是管理网络爬虫对网页遍历的优先级排序的子系统。
优先级队列
第10章 PageRank——Google的民主表决式网页排名技术
搜索结果的排名取决于:关于网页的质量信息以及这个查询与每个网页的相关性信息。1 PageRank算法的原理
PageRank 拉里佩奇和谢尔盖布林核心思想——“举手表决”,如果一个网友呗很多其他网页所链接,说明它受到普遍的承认和信赖,那么它的排名就高。
网页排名高的网站贡献的链接权重大。权重的计算为二维矩阵相乘问题,并用迭代的方法解决。
不需要任何人工干预。稀疏矩阵计算。
并行计算工具MapReduce由Google的迪恩和格麦瓦特发明,缩短了网页排名的更新周期。
2 延伸阅读:PageRank的计算方法
Bi=A·Bi-1由于网页之间链接的数量相比互联网的规模非常稀疏,因此计算网页的网页排名也需要对零概率或者小概率事件进行平滑处理。网页的排名是一个一维向量,对它的平滑处理只能利用一个小的常数α。
Bi=[a/N·I+(1-a)A]·Bi-1
其中N是互联网网页的数量,a是一个较小的常数,I是单位矩阵。
第11章 如何确定网页和查询的相关性
影响搜索引擎质量的因素:完备的索引;对网页质量的度量;用户偏好;确定一个网页和某个查询的相关性的方法。1 搜索关键词权重的科学度量TF-IDF
IDF即为每个词的权重,反映了一个词预测主题的能力。IDF的概念就是一个特定条件下关键词的概率分布的交叉熵。2延伸阅读:TF-IDF的信息论依据
一个词的信息量越多,TF-IDF值越大;同时关键词w命中的文献中w平均出现的次数越多,TF-IDF也越大。第12章 有限状态机和动态规划——地图与本地搜索的核心技术
智能手机的定位和导航功能的关键技术:利用卫星定位;地址的识别;根据用户输入的起点和终点,在地图上规划最短路线或者最快路线。1 地址分析和有限状态机
针对模糊匹配,提出了基于概率的有限状态机,基本等效于离散的马尔可夫链。2全球导航和动态规划
全球导航的关键算法是计算机科学图论中的动态规划的算法。3延伸阅读:有限状态传感器
加权的有限状态传感器WFST在语音识别和自然语言理解中起非常重要的作用。第13章 Google AK-47的设计者——阿米特·辛格博士
先找简单有效的解决方案,再进行优化,而不要一次到位。对改进方法都要能说清楚理由,说不清楚理由的改进,即使看上去有效也不要采用,因为这样将来可能是个隐患。
坚持分析不好的结果。
第14章 余弦定理和新闻的分类
1 新闻的特征向量
“算”新闻而不是读新闻如果把词典的大小限制在65535个词以内,在计算机中只要用两个字节就能表示一个词。
2 向量距离的度量
通过计算向量的夹角来判断对应的新闻主题的接近程度。余弦定理
自底向上不断合并的方法对新闻进行分类——Dynamic nonlocallanguage modeling via hierarhical topic-based adaptation
3 延伸阅读:计算向量余弦的技巧
大数据量时的余弦计算:分母部分(向量的长度)不需要重复计算
计算分子即两个向量内积时,只需考虑向量中的非零元素
可以删除虚词
位置的加权:
对标题和重要位置的词进行额外的加权,以提高文本分类的准确性。
第15章 矩阵运算和文本处理中的两个分类问题
1 文本和词汇的矩阵
奇异值分解SVD

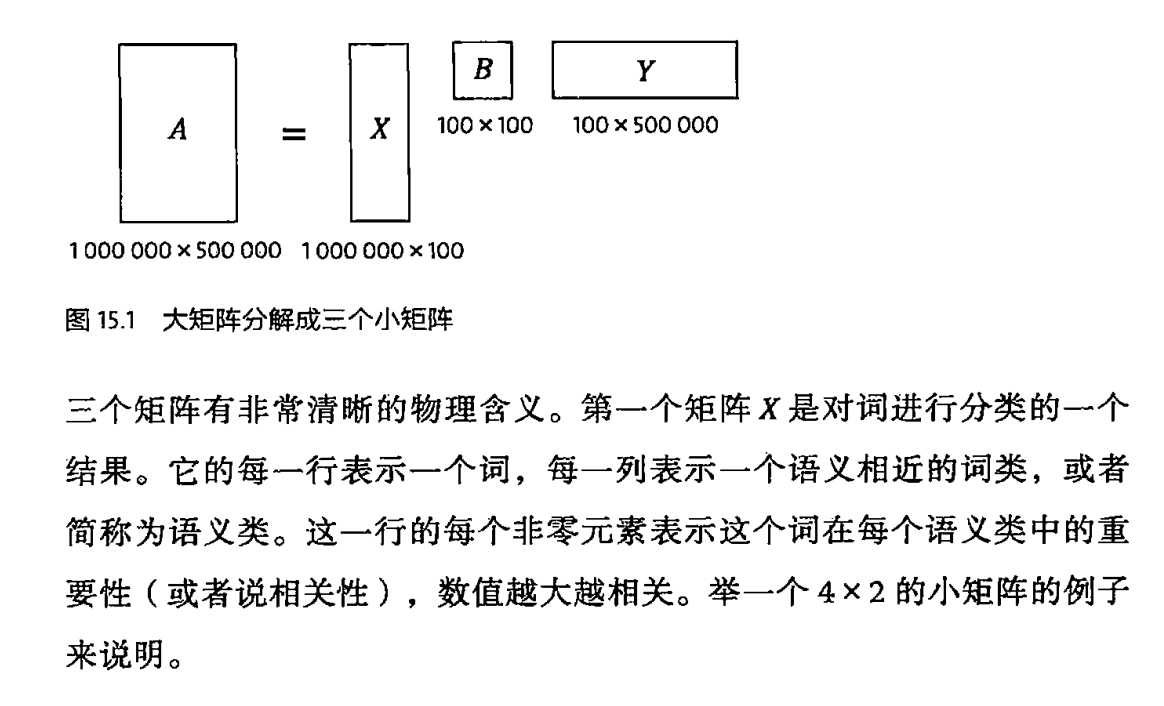




2 延伸阅读:奇异值分解的方法和应用场景

3 小结


相关文章推荐
- 《数学之美》总结(第1章~第3章)
- 《数学之美》读想--第1章
- 《数学之美》 第1章 文字和语言VS数字和信息&第2章:自然语言处理
- 《数学之美》(吴军 著)读书笔记:第1章 文字和语言 vs 数字和信息
- 《数学之美》(吴军 著)读书笔记:第1章 文字和语言 vs 数字和信息
- JAVA之第1章 对象入门
- 第1章. JBPM介绍
- 数学之美系列六 -- 图论和网络爬虫 (Web Crawlers)
- C++Primer 读书笔记 第1章 开始
- 第1章 从零开始——Oracle 9i基础
- 数字图像处理编程入门—第1章 Windows位图和调色板
- Google 科学家吴军写的《数学之美》系列文章
- 深入理解计算机系统-第1天-第1章
- jQuery in Action 第1章 《引荐 jQuery 》 引言
- 第1章 启动电子商务网站
- 第1章 欢迎进入软件构建的世界
- 《你必须知道的.NET》第1章学习笔记
- 真・恋姫†無双 蜀国剧情翻译第1章[2]
- 《AS3殿堂之路》之第15章 XML数据处理
- CCNA学习笔记---第1章:Internetworking