快速排序算法原理及实现(单轴快速排序、三向切分快速排序、双轴快速排序)
2017-06-02 10:39
357 查看
转自:http://www.cnblogs.com/nullzx/p/5880191.html
1. 单轴快速排序的基本原理
快速排序的基本思想就是从一个数组中任意挑选一个元素(通常来说会选择最左边的元素)作为中轴元素,将剩下的元素以中轴元素作为比较的标准,将小于等于中轴元素的放到中轴元素的左边,将大于中轴元素的放到中轴元素的右边,然后以当前中轴元素的位置为界,将左半部分子数组和右半部分子数组看成两个新的数组,重复上述操作,直到子数组的元素个数小于等于1(因为一个元素的数组必定是有序的)。以下的代码中会常常使用交换数组中两个元素值的Swap方法,其代码如下
2. 快速排序中元素切分的方式
快速排序中最重要的就是步骤就是将小于等于中轴元素的放到中轴元素的左边,将大于中轴元素的放到中轴元素的右边,我们暂时把这个步骤定义为切分。而剩下的步骤就是进行递归而已,递归的边界条件为数组的元素个数小于等于1。以首元素作为中轴,看看常见的切分方式。
2.1 从两端扫描交换的方式
基本思想,使用两个变量i和j,i指向首元素的元素下一个元素(最左边的首元素为中轴元素),j指向最后一个元素,我们从前往后找,直到找到一个比中轴元素大的,然后从后往前找,直到找到一个比中轴元素小的,然后交换这两个元素,直到这两个变量交错(i > j)(注意不是相遇 i == j,因为相遇的元素还未和中轴元素比较)。最后对左半数组和右半数组重复上述操作。
2.2 两端扫描,一端挖坑,另一端填补
基本思想,使用两个变量i和j,i指向最左边的元素,j指向最右边的元素,我们将首元素作为中轴,将首元素复制到变量pivot中,这时我们可以将首元素i所在的位置看成一个坑,我们从j的位置从右向左扫描,找一个小于等于中轴的元素A[j],来填补A[i]这个坑,填补完成后,拿去填坑的元素所在的位置j又可以看做一个坑,这时我们在以i的位置从前往后找一个大于中轴的元素来填补A[j]这个新的坑,如此往复,直到i和j相遇(i== j,此时i和j指向同一个坑)。最后我们将中轴元素放到这个坑中。最后对左半数组和右半数组重复上述操作。
2.3 单端扫描方式
j从左向右扫描,A[1,i]表示小于等于pivot的部分,A[i+1,j-1]表示大于pivot的部分,A[j, R]表示未知元素
初始化时,选取最左边的元素作为中轴元素,A[1,i]表示小于等于pivot的部分,i指向中轴元素(i < 1),表示小于等于pivot的元素个数为0,j以后的都是未知元素(即不知道比pivot大,还是比中轴元素小),j初始化指向第一个未知元素。

当A[j]大于pivot时,j继续向前,此时大于pivot的部分就增加一个元素

上图中假设对A[j]与pivot比较后发现A[j]大于pivot时,j的变化
当A[j]小于等于pivot时,我们注意注意i的位置,i的下一个就是大于pivot的元素,我们将i增加1然后交换A[i]和A[j],交换后小于等于pivot的部分增加1,j增加1,继续扫描下一个。而i的下一个元素仍然大于pivot,又回到了先前的状态。
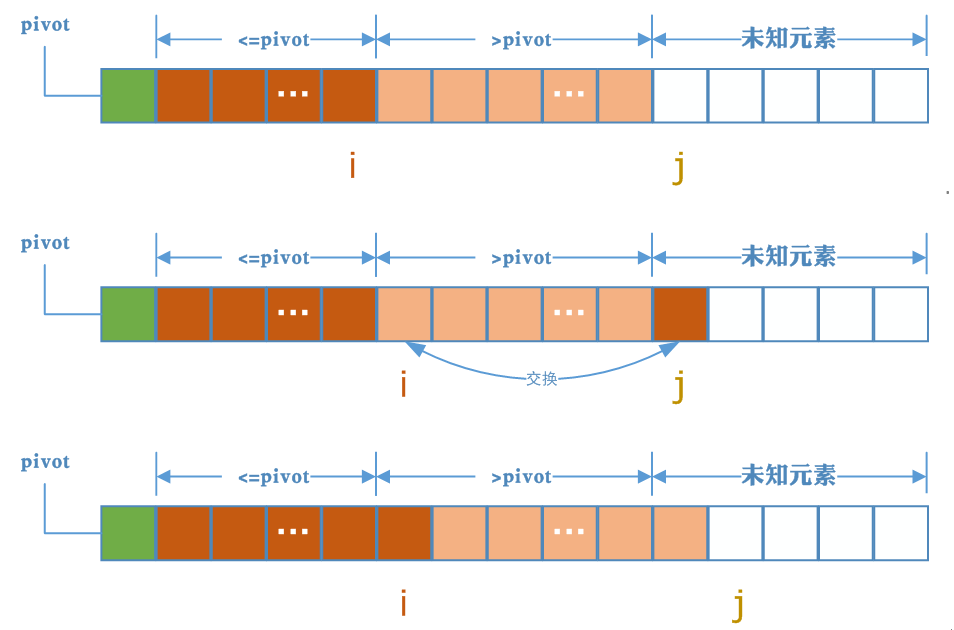
上图中假设对A[j]与pivot比较后发现A[j] <= pivot时,i,j的变化
3. 三向切分的快速排序
三向切分快速排序的基本思想,用i,j,k三个将数组切分成四部分,a[L, i-1]表示小于pivot的部分,a[i, k-1]表示等于pivot的部分,a[j+1]表示大于pivot的部分,而a[k, j]表示未判定的元素(即不知道比pivot大,还是比中轴元素小)。我们要注意a[i]始终位于等于pivot部分的第一个元素,a[i]的左边是小于pivot的部分。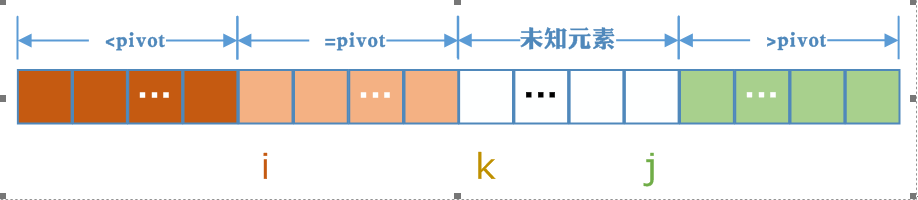
我们选取最左边的元素作为中轴元素,初始化时,i = L,k = L+1,j=R(L表示最左边元素的索引,R表示最右边元素的索引)

通过上一段的表述可知,初始化时<pivot部分的元素个数为0,等于pivot部分元素的个数为1,大于pivot部分的元素个数为0,这显然符合目前我们对所掌握的情况。k自左向右扫描直到k与j错过为止(k > j)。我们扫描的目的就是逐个减少未知元素,并将每个元素按照和pivot的大小关系放到不同的区间上去。
在k的扫描过程中我们可以对a[k]分为三种情况讨论
(1)a[k] < pivot 交换a[i]和a[k],然后i和k都自增1,k继续扫描
(2)a[k] = pivot k自增1,k接着继续扫描
(3)a[k] > pivot 这个时候显然a[k]应该放到最右端,大于pivot的部分。但是我们不能直接将a[k]与a[j]交换,因为目前a[j]和pivot的关系未知,所以我们这个时候应该从j的位置自右向左扫描。而a[j]与pivot的关系可以继续分为三种情况讨论
3.1)a[j] > pivot j自减1,j接着继续扫描
3.2)a[j] == pivot 交换a[k]和a[j],k自增1,j自减1,k继续扫描(注意此时j的扫描就结束了)
3.3)a[j] < pivot: 此时我们注意到a[j] < pivot, a[k] > pivot, a[i] == pivot,那么我们只需要将a[j]放到a[i]上,a[k]放到a[j]上,而a[i]放到a[k]上。然后i和k自增1,j自减1,k继续扫描(注意此时j的扫描就结束了)
注意,当扫描结束时,i和j的表示了=等于pivot部分的起始位置和结束位置。我们只需要对小于pivot的部分以及大于pivot的部分重复上述操作即可。

4. 双轴快速排序
双轴快速排序算法思路和三向切分快速排序算法的思路基本一致,双轴快速排序算法使用两个轴,通常选取最左边的元素作为pivot1和最右边的元素作pivot2。首先要比较这两个轴的大小,如果pivot1 > pivot2,则交换最左边的元素和最右边的元素,已保证pivot1 <= pivot2。双轴快速排序同样使用i,j,k三个变量将数组分成四部分
A[L+1, i]是小于pivot1的部分,A[i+1, k-1]是大于等于pivot1且小于等于pivot2的部分,A[j, R]是大于pivot2的部分,而A[k, j-1]是未知部分。和三向切分的快速排序算法一样,初始化i = L,k = L+1,j=R,k自左向右扫描直到k与j相交为止(k == j)。我们扫描的目的就是逐个减少未知元素,并将每个元素按照和pivot1和pivot2的大小关系放到不同的区间上去。
在k的扫描过程中我们可以对a[k]分为三种情况讨论(注意我们始终保持最左边和最右边的元素,即双轴,不发生交换)
(1)a[k] < pivot1 i先自增,交换a[i]和a[k],k自增1,k接着继续扫描
(2)a[k] >= pivot1 && a[k] <= pivot2 k自增1,k接着继续扫描
(3)a[k] > pivot2: 这个时候显然a[k]应该放到最右端大于pivot2的部分。但此时,我们不能直接将a[k]与j的下一个位置a[--j]交换(可以认为A[j]与pivot1和pivot2的大小关系在上一次j自右向左的扫描过程中就已经确定了,这样做主要是j首次扫描时避免pivot2参与其中),因为目前a[--j]和pivot1以及pivot2的关系未知,所以我们这个时候应该从j的下一个位置(--j)自右向左扫描。而a[--j]与pivot1和pivot2的关系可以继续分为三种情况讨论
3.1)a[--j] > pivot2 j接着继续扫描
3.2)a[--j] >= pivot1且a[j] <= pivot2 交换a[k]和a[j],k自增1,k继续扫描(注意此时j的扫描就结束了)
3.3) a[--j] < pivot1 先将i自增1,此时我们注意到a[j] < pivot1, a[k] > pivot2, pivot1 <= a[i] <=pivot2,那么我们只需要将a[j]放到a[i]上,a[k]放到a[j]上,而a[i]放到a[k]上。k自增1,然后k继续扫描(此时j的扫描就结束了)
注意
1. pivot1和pivot2在始终不参与k,j扫描过程。
2. 扫描结束时,A[i]表示了小于pivot1部分的最后一个元素,A[j]表示了大于pivot2的第一个元素,这时我们只需要交换pivot1(即A[L])和A[i],交换pivot2(即A[R])与A[j],同时我们可以确定A[i]和A[j]所在的位置在后续的排序过程中不会发生变化(这一步非常重要,否则可能引起无限递归导致的栈溢出),最后我们只需要对A[L, i-1],A[i+1,
j-1],A[j+1, R]这三个部分继续递归上述操作即可。

5. 参考文章
[1] 算法(第四版)RobertSedgewick[2] http://www.jianshu.com/p/6d26d525bb96

相关文章推荐
- 快速排序算法原理及实现(单轴快速排序、三向切分快速排序、双轴快速排序)
- 快速排序算法原理及实现(单轴快速排序、三向切分快速排序、双轴快速排序)
- 快速排序算法原理及实现(单轴快速排序、三向切分快速排序、双轴快速排序)
- 快速排序算法原理及实现(单轴快速排序、三向切分快速排序、双轴快速排序)
- [快速排序]转-快速排序的实现
- 算法代码实现之三向切分快速排序,C/C++实现
- 快速排序原理及Java实现
- 快速排序 的原理及其java实现(递归与非递归)
- 快速排序的原理及java代码实现
- C快速排序-思想、原理与实现-简笔
- 快速排序原理及Java实现
- 算法代码实现之三向切分快速排序,Golang(Go语言)实现
- 快速排序的两种实现方式,主要是Partition函数的实现原理不一样
- 快速排序及三向切分快速排序
- STL sort 函数实现详解 作者:fengcc 原创作品 转载请注明出处 前几天阿里电话一面,被问到STL中sort函数的实现。以前没有仔细探究过,听人说是快速排序,于是回答说用快速排序实现的
- 快速排序 原理与实现
- 算法代码实现之三向切分快速排序,Java实现
- 快速排序的算法思想及Python版快速排序的实现示例
- JavaSE第三十五讲:冒泡排序、交换排序及快速排序原理与实现
- 交换排序—快速排序(Quick Sort)原理以及Java实现