hadoop 运行mahout 问题总结
2017-05-29 17:10
183 查看
完成Hadoop上的搭建,开始运行几个小的测试,毕竟第一次,遇到了一些小问题。
首先,是参考资料中的 验证安装是否成功的步骤。
将下载数据 synthetic_control.data 上传到HDFS中,命令如下
(1) hadoop fs -mkdir testdata(注意,此命令的文件夹路径必须是如上,不可是/testdata 等其他形式)
(2) hadoop fs -put synthetic_control.data(注意,如果数据不是当前文件夹下,应该添加相对或者绝对路径) testdata/
(3) hadoop fs -ls testdata (查看是否上传成功)
数据上传成功之后,开始运行测试聚类程序,命令如下
(4) hadoop jar mahout-distribution-0.9/mahout-examples-0.9-job.jar
(注意路径) org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
运行完成之后,查看结果
hadoop fs -ls output(注意路径)
完成。
其次,在运行数据序列化时遇到问题,就是将HDFS中数据转成Mahout可以识别额输入格式。
会提示,Exception in thread "main" Java.lang.NoClassDefFoundError:
org/apache/mahout/common/AbstractJob 错误!!!!
这是因为没有将mahout中的jar文件进行相关的导入。网上找的一些解决方法,如下
要想让mapreduce程序引用第三方jar文件, 可以采用如下方式:
1。通过命令行参数传递jar文件, 如-libjars等;
2。直接在conf中设置, 如conf.set(“tmpjars”,*.jar), jar文件用逗号隔开;
3。利用分布式缓存, 如DistributedCache.addArchiveToClassPath(path, job), 此处的path必须是hdfs, 即自己讲jar上传到hdfs上, 然后将路径加入到分布式缓存中;第三方jar文件和自己的程序打包到一个jar文件中, 程序通过job.getJar()将获得整个文件并将其传至hdfs上. (很笨重)
4。在每台机器的$HADOOP_HOME/lib目录中加入jar文件. (不推荐)
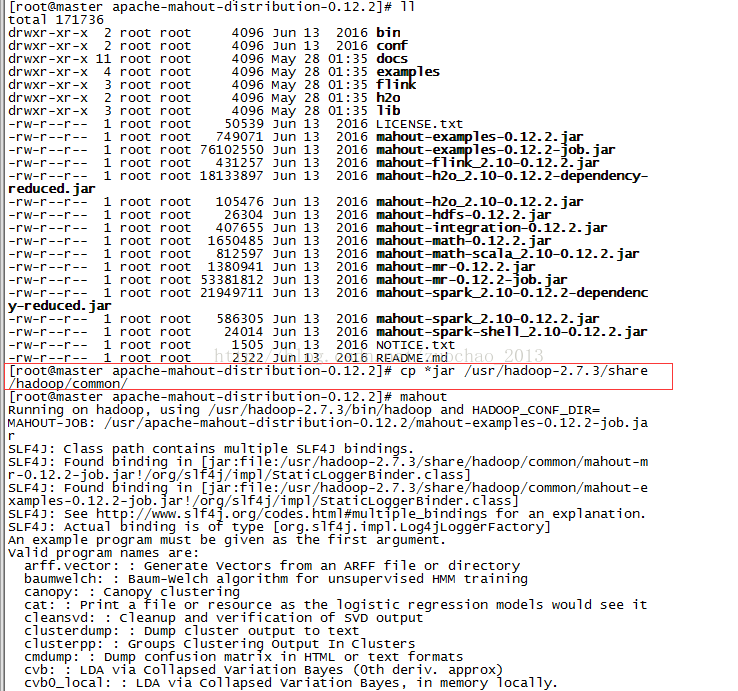
前三种没有研究和验证,使用的第四种,但是这里注意,hadoop老的版本放入lib文件夹下可以,我使用的是hadoop-2.5.2,需要将jar文件放到$HADOOP_HOME/share/hadoop/common 或者其他文件夹中。
完成之后,就可以正常执行了。
解决办法:
首先,是参考资料中的 验证安装是否成功的步骤。
将下载数据 synthetic_control.data 上传到HDFS中,命令如下
(1) hadoop fs -mkdir testdata(注意,此命令的文件夹路径必须是如上,不可是/testdata 等其他形式)
(2) hadoop fs -put synthetic_control.data(注意,如果数据不是当前文件夹下,应该添加相对或者绝对路径) testdata/
(3) hadoop fs -ls testdata (查看是否上传成功)
数据上传成功之后,开始运行测试聚类程序,命令如下
(4) hadoop jar mahout-distribution-0.9/mahout-examples-0.9-job.jar
(注意路径) org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
运行完成之后,查看结果
hadoop fs -ls output(注意路径)
完成。
其次,在运行数据序列化时遇到问题,就是将HDFS中数据转成Mahout可以识别额输入格式。
会提示,Exception in thread "main" Java.lang.NoClassDefFoundError:
org/apache/mahout/common/AbstractJob 错误!!!!
这是因为没有将mahout中的jar文件进行相关的导入。网上找的一些解决方法,如下
要想让mapreduce程序引用第三方jar文件, 可以采用如下方式:
1。通过命令行参数传递jar文件, 如-libjars等;
2。直接在conf中设置, 如conf.set(“tmpjars”,*.jar), jar文件用逗号隔开;
3。利用分布式缓存, 如DistributedCache.addArchiveToClassPath(path, job), 此处的path必须是hdfs, 即自己讲jar上传到hdfs上, 然后将路径加入到分布式缓存中;第三方jar文件和自己的程序打包到一个jar文件中, 程序通过job.getJar()将获得整个文件并将其传至hdfs上. (很笨重)
4。在每台机器的$HADOOP_HOME/lib目录中加入jar文件. (不推荐)
前三种没有研究和验证,使用的第四种,但是这里注意,hadoop老的版本放入lib文件夹下可以,我使用的是hadoop-2.5.2,需要将jar文件放到$HADOOP_HOME/share/hadoop/common 或者其他文件夹中。
完成之后,就可以正常执行了。
解决办法:

相关文章推荐
- hadoop运行mahout问题解决方法
- hadoop3.0.0运行mapreduce(wordcount)过程及问题总结
- hadoop 运行mahout 问题小结(一)
- hadoop开发运行环境配置及相关问题总结
- hadoop 运行mahout 问题小结(二)
- ubuntu14.01 下hadoop-2.7.1 运行java程序问题总结
- hadoop下编译运行mahout示例的问题解决方案
- Hadoop学习笔记2:eclipse运行Mapreduce程序问题总结
- 关于运行Drupal 7的Nginx+PHP系统设置的一些问题解决方案总结
- VC运行库版本不同导致链接.LIB静态库时发生重复定义问题的一个案例分析和总结
- 关于运行地址和加载地址的几个很多初学者模糊不清的问题我在这里总结一下
- Hadoop学习总结之五:Hadoop的运行痕迹
- VC运行库版本不同导致链接.LIB静态库时发生重复定义问题的一个案例分析和总结
- 转:VC运行库版本不同导致链接.LIB静态库时发生重复定义问题的一个案例分析和总结
- hadoop 单机、伪分布式及集群下的运行测试总结
- 转:VC运行库版本不同导致链接.LIB静态库时发生重复定义问题的一个案例分析和总结
- 【总结】关于运行脚本问题
- cgywin下 hadoop运行 问题
- Hadoop 学习总结之五:Hadoop的运行痕迹
- Hadoop下运行WordCount的命令总结(亲身体验)