图像处理基础知识系列之二:核概率密度估计简介
2017-05-28 15:23
459 查看
核概率密度估计简介
核密度估计(Kernel density estimation),是一种用于估计概率密度函数的非参数方法,为独立同分布F的n个样本点,设其概率迷度函数为f,核密度估计为以下: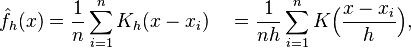
公式(1)
以上解释虽然仅仅几行,但看起来还是不是那么容易理解,这里主要想通过另外一种方式对核概率密度函数有一个直观的初步解释,严谨性与逻辑性不作要求,如若你对核概率密度估计已经有了一定的理解,而想深入探究起本质,请移步: http://blog.csdn.net/yuanxing14/article/details/41948485(核概率估计维基翻译版),https://www.zhihu.com/question/27301358/answer/105267357?from=profile_answer_card(核概率估计知乎版)。
以上文章讲的比较清楚,条例公式较全,本文中也要多处引用。
一、概率密度函数
在数学中,连续型随机变量的概率密度函数(在不至于混淆时可以简称为密度函数)是一个描述这个随机变量的输出值,在某个确定的取值点附近的可能性的函数。probabilitydensity function,简称PDF。直观地印象就是下图所示,这是x,y都是连续的区间:
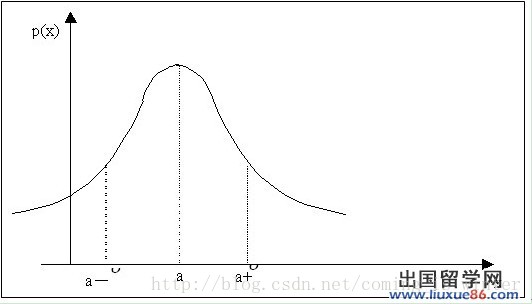
图1
二、直方图
直方图(Histogram)又称质量分布图。是一种统计报告图,由一系列高度不等的纵向条纹或线段表示数据分布的情况。一般用横轴表示数据类型,纵轴表示分布情况。如图所示:
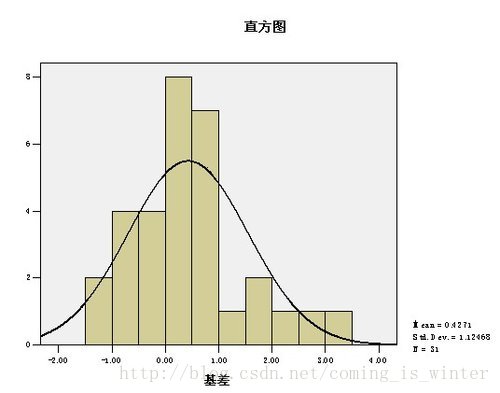
图2
这里可以把平常的直方图扩展一下,引入直方图概率密度估计的概念。
参数估计:在已知系统模型结构时,用系统的输入和输出数据计算系统模型参数的过程。
就是平时我们画直方图的时候都是完整版,两个坐标轴的参数都是齐整的。如果x,y的取值我们不是完全知道,最终的直方图也是不完整的,我们只有利用现有条件画出相对完整的图形。
举个例子。离散的集合中x={1,3,4,7,9,11},y={1,1,2,2,1,3},对应的直方图可以画出来,这里又引出了组数与组距的概念,即是直方图中小矩形的宽度(组距)的确定,这里我们设为参数bin,bin=1时对应的完整直方图如下图所示:
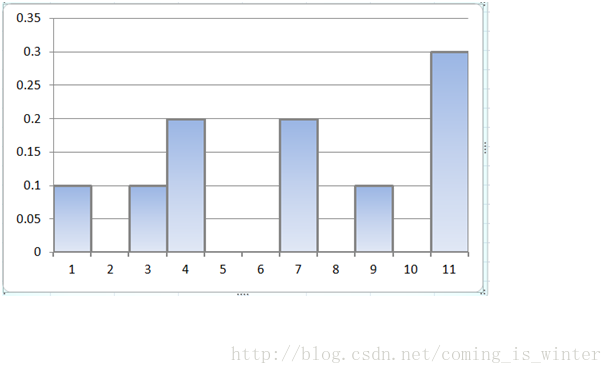
图3
bin=2时的完整直方图如下图所示:
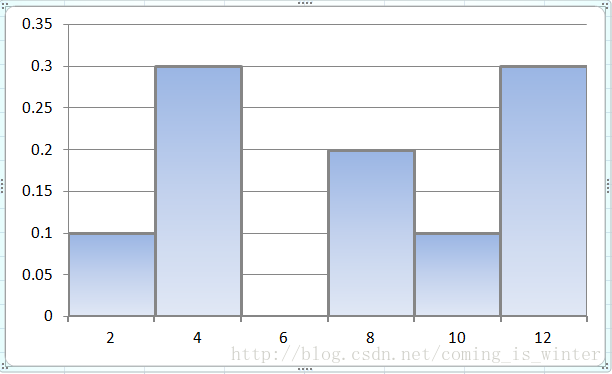
图4
这里我们有一种情况x,y的取值获取不完整,对于概率密度我们只能进行估计,譬如,我们只知道x={1,3,4,9,11},y={1,1,2,1,3},而x=7时的直方图对应项我们直观得不到,对应的直方图概率密度估计bin=1时如下图所示:
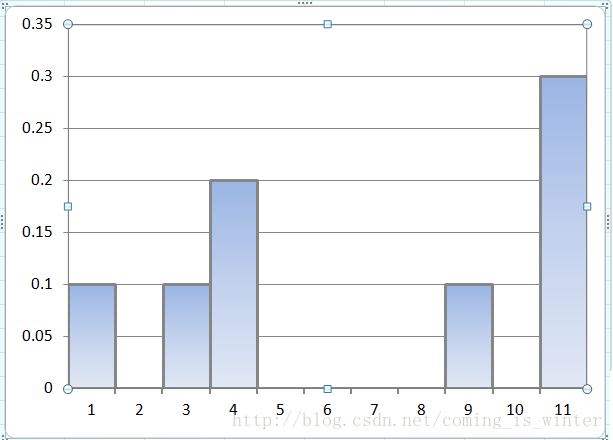
图5
对应的直方图概率密度估计bin=2时如下图所示:
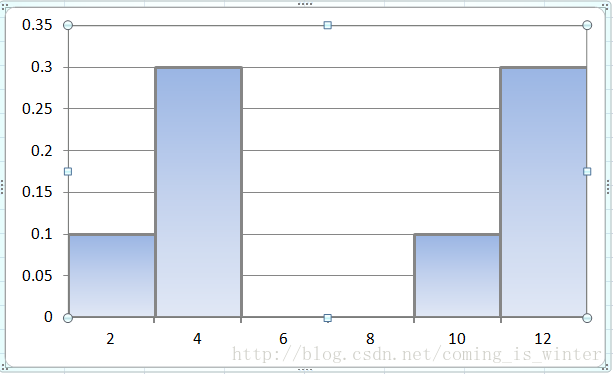
图6
这里的不完整概率密度函数或者说概率密度估计就出来了,与完整的概率密度函数有一定区别,但已经是已获取信息下的最好结果了。
在这里提出一个问题,假设数据不完整性一致,就是x我们不知道的取值数量是一定的,最后的概率密度估计图形和什么有关系呢?和bin有关。bin不同,最后的对应着概率密度估计就不同,如图5和图6。这个bin组距参数对应着公式(1)中的h,,,而公式(1)中的n对应着直方图组数,(组距=bin=h,组数=n)具体关系讲解见附录1,这里记下就好。而怎样选择合适的h见附录2.
三、核概率密度估计
这句话的断句,一开始读的话容易读成 核概率 密度估计,所以就一直思考核概率是个什么东东,其实可以这么断句 核 概率密度估计,这里核的概念就是一个单位的意思,再回到我们的直方图中,直方图概率密度估计中的核是一个单位的bin*一个单位的高度(概率),,也就是一个单位的矩形框。。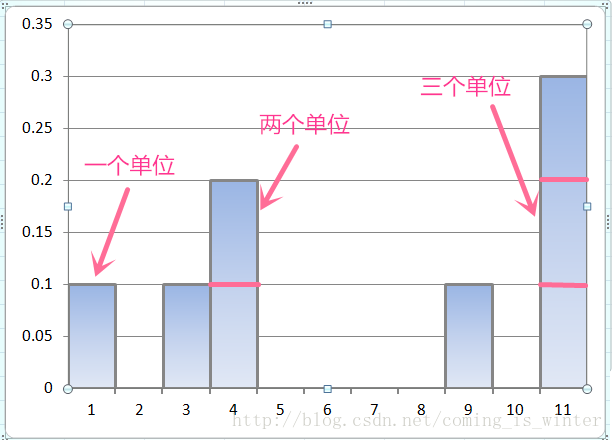
图7
如果函数由离散转变成连续,直方图转变成连续密度函数,核函数从矩形框转变成对应的连续函数,核函数的对应种类图8所示,h在直方图中表示组距,在对应核函数中表示各自参数,如在高斯正态函数中对应方差σ,,n为样本数量,见公式(1),而对应于直方图中的矩形拟合概率密度估计转变为用对应的核函数拟合核概率密度估计,原理相似,进行对应图像的叠加,得出已知条件下的最优图形,具体操作见图9。
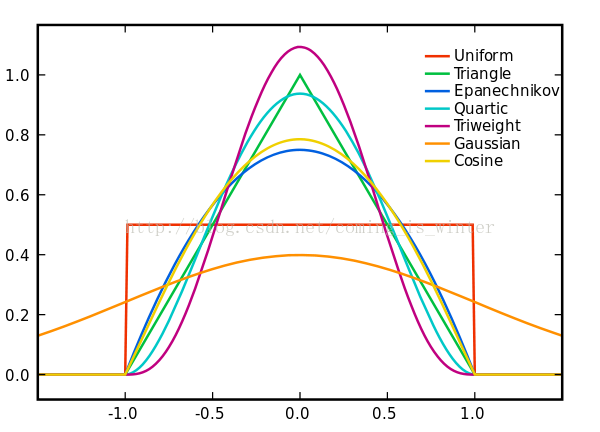
图8
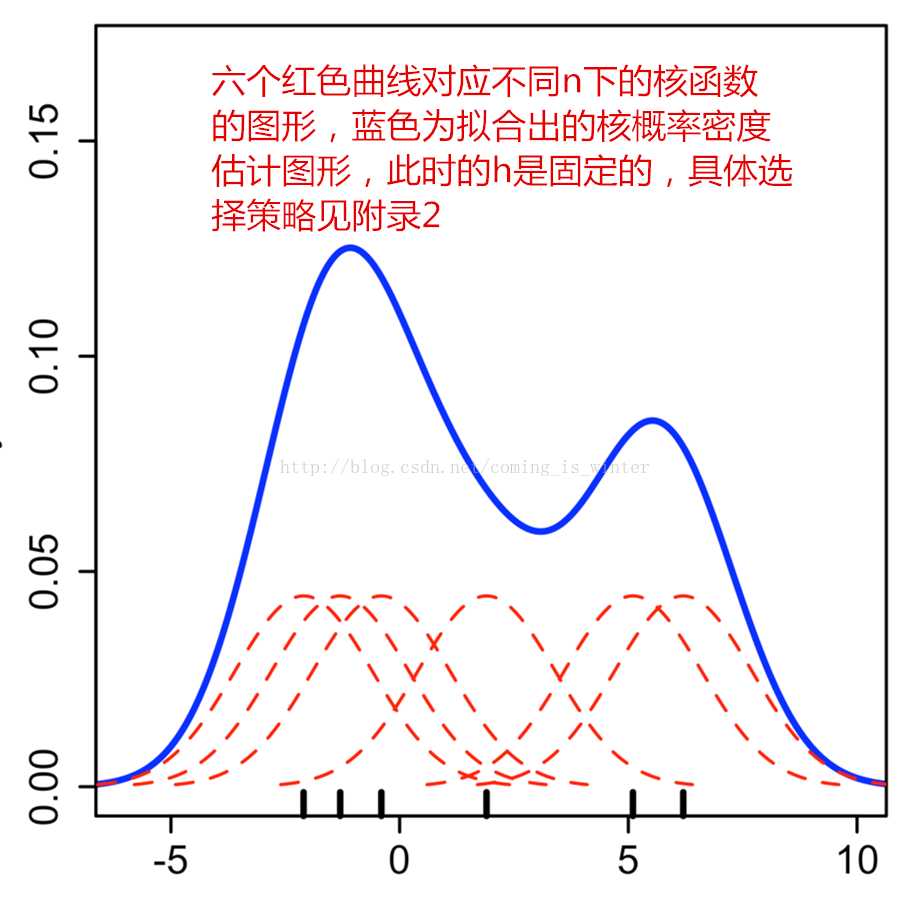
图9
四、附录
附录1:组距bin与h的关系:一个很自然的想法是,如果我们想知道X=x处的密度函数值,可以像直方图一样,选一个x附近的小区间,数一下在这个区间里面的点的个数,除以总个数,应该是一个比较好的估计。用数学语言来描述,如果你还记得导数的定义,密度函数可以写为:
我们把分布函数用上面的经验分布函数替代,那么上式分子上就是落在[x-h,x+h]区间的点的个数。我们可以把f(x)的估计写成:
作者:慧航
链接:https://www.zhihu.com/question/27301358/answer/105267357
附录2:h得选择策略:
不同的带宽得到的估计结果差别很大,那么如何选择h?显然是选择可以使误差最小的。下面用平均积分平方误差(mean intergrated squared error)的大小来衡量h的优劣。
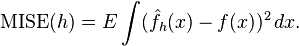
在weak assumptions下,MISE (h) =AMISE(h) + o(1/(nh) + h4) ,其中AMISE为渐进的MISE。而AMISE有,
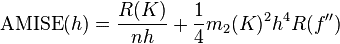
,
其中,
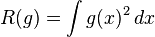
,
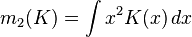
为了使MISE(h)最小,则转化为求极点问题,
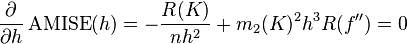
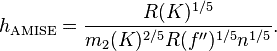
当核函数确定之后,h公式里的R、m、f''都可以确定下来,有(hAMISE ~ n−1/5),AMISE(h)
= O(n−4/5)。
如果带宽不是固定的,其变化取决于估计的位置(balloon estimator)或样本点(逐点估计pointwise estimator),由此可以产产生一个非常强大的方法称为自适应或可变带宽核密度估计。
参考文献:上已给出。

相关文章推荐
- 图像处理基础知识系列之四:最大似然和EM(期望最大化)算法简单梳理
- 图像处理基础知识系列之五:贝叶斯方法简单梳理
- 图像处理基础知识系列之一:边界跟踪之内边界跟踪算法解释
- 图像处理基础知识系列之三:霍夫变换简单梳理
- Kinect for windows 开发入门 六:图像处理基础知识
- PHP基础知识系列:错误处理与异常处理
- C#基础知识梳理系列十:异常处理 System.Exception
- 浅谈语音信号处理系列之二 语音信号处理的基础
- 图像处理之基础---图像的特征简介
- Java数字图像处理基础知识 - 必读
- 图像处理基础知识
- 图像处理基础知识
- LoadRunner性能测试实战读书笔记系列 之二 性能测试基础知识 占个位置
- 图像处理之基础---卷积模板简介
- Java数字图像处理基础知识 - 必读
- 图像处理的基础知识
- memcached系列之1:memcached基础知识简介(为什么要使用memcached做缓存服务器)
- memcached系列之1:memcached基础知识简介(为什么要使用memcached做缓存服务器)
- memcached系列之1:memcached基础知识简介(为什么要使用memcached做缓存服务器)
- 图像处理基础知识