【深度学习-CNN】CNN中的参数与计算量
2017-05-26 09:54
176 查看
一个卷积神经网络的基本构成一般有卷积层(convolutional layer)、池化层(pooling layer)、全连接层(fully connection layer)。本文以caffe中的LeNet-5为例,分析卷积层和全连接层的参数数量和计算量情况。
卷积层的基本原理就是图像的二维卷积,即将一个二维卷积模板先翻转(旋转180°),再以步长stride进行滑动,滑动一次则进行一次模板内的对应相乘求和作为卷积后的值。在CNN的卷积层中,首先是卷积层维度提升到三维、四维,与二维图分别进行卷积,然后合并,这里的卷积一般是相关操作,即不做翻转。具体如下图所示:
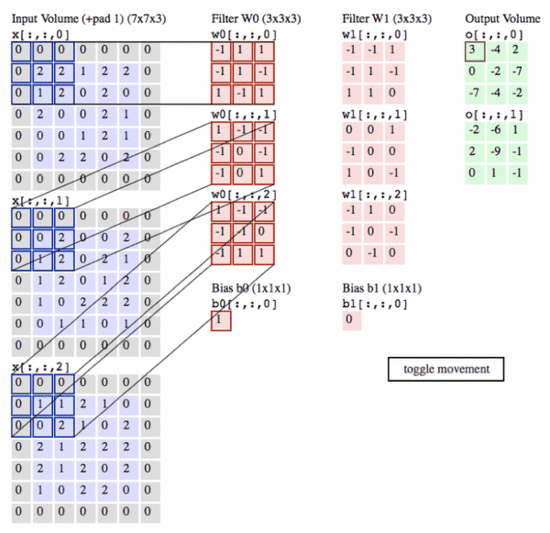
.
上图中左边的一幅输入图的三个通道,中间是卷积层,尺寸为3*3*3*2,这里就是三维卷积,得到的特征图还是一个通道,有两个三维卷积得到两个featuremap。
我们以caffe中的LeNet-5的lenet.prototxt为例。
layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 64 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
可以看到整个CNN的输入是28×28的灰度图,batchsize是64。第一个卷积层是5×5×20的尺寸,即卷积核为5×5,有20个。第一个卷积层之后有一个max pooling 层。下面我们来看一下日志文件。
I0405 18:22:46.263157 13500 db_lmdb.cpp:40] Opened lmdb ./mnist_train_lmdb
I0405 18:22:46.366945 13112 data_layer.cpp:41] output data size: 64,1,28,28
I0405 18:22:46.369945 13112 net.cpp:150] Setting up mnist
I0405 18:22:46.369945 13112 net.cpp:157] Top shape: 64 1 28 28 (50176)
I0405 18:22:46.369945 13112 net.cpp:157] Top shape: 64 (64)
I0405 18:22:46.369945 13112 net.cpp:165] Memory required for data: 200960
I0405 18:22:46.369945 13112 layer_factory.hpp:77] Creating layer conv1
I0405 18:22:46.369945 13112 net.cpp:100] Creating Layer conv1
I0405 18:22:46.369945 13112 net.cpp:444] conv1 <- data
I0405 18:22:46.369945 13112 net.cpp:418] conv1 -> conv1
I0405 18:22:46.372946 11592 common.cpp:36] System entropy source not available, using fallback algorithm to generate seed instead.
I0405 18:22:48.350821 13112 net.cpp:150] Setting up conv1
I0405 18:22:48.351820 13112 net.cpp:157] Top shape: 64 20 24 24 (737280)
I0405 18:22:48.351820 13112 net.cpp:165] Memory required for data: 3150080
I0405 18:22:48.351820 13112 layer_factory.hpp:77] Creating layer pool1
I0405 18:22:48.351820 13112 net.cpp:100] Creating Layer pool1
I0405 18:22:48.351820 13112 net.cpp:444] pool1 <- conv1
I0405 18:22:48.351820 13112 net.cpp:418] pool1 -> pool1
I0405 18:22:48.351820 13112 net.cpp:150] Setting up pool1
I0405 18:22:48.351820 13112 net.cpp:157] Top shape: 64 20 12 12 (184320)
I0405 18:22:48.351820 13112 net.cpp:165] Memory required for data: 3887360输入为28×28的单通道图,经过一层卷积以后输出为24×24×20,因为边界处理
4000
所以卷积完尺寸为28-5+1 = 24。卷积核的数量为20,所以conv-1的尺寸如上。再经过一层pooling层尺寸为12×12×20。则单样本前向传播计算量为:5×5×24×24×20 = 288 000,实际计算量还应乘以batchsize = 64。卷积层参数数量为:5×5×20
= 500。计算量和参数比为:288000/500 = 576.
下面看一下全连接层的情况。
I0405 18:22:48.366821 13112 net.cpp:157] Top shape: 64 50 4 4 (51200)
I0405 18:22:48.366821 13112 net.cpp:165] Memory required for data: 4911360
I0405 18:22:48.366821 13112 layer_factory.hpp:77] Creating layer ip1
I0405 18:22:48.367826 13112 net.cpp:100] Creating Layer ip1
I0405 18:22:48.367826 13112 net.cpp:444] ip1 <- pool2
I0405 18:22:48.367826 13112 net.cpp:418] ip1 -> ip1
I0405 18:22:48.375823 13112 net.cpp:150] Setting up ip1
I0405 18:22:48.375823 13112 net.cpp:157] Top shape: 64 500 (32000)
I0405 18:22:48.375823 13112 net.cpp:165] Memory required for data: 5039360
I0405 18:22:48.375823 13112 layer_factory.hpp:77] Creating layer relu1
I0405 18:22:48.375823 13112 net.cpp:100] Creating Layer relu1
I0405 18:22:48.375823 13112 net.cpp:444] relu1 <- ip1
I0405 18:22:48.375823 13112 net.cpp:405] relu1 -> ip1 (in-place)
I0405 18:22:48.376822 13112 net.cpp:150] Setting up relu1
I0405 18:22:48.376822 13112 net.cpp:157] Top shape: 64 500 (32000)
I0405 18:22:48.376822 13112 net.cpp:165] Memory required for data: 5167360上图是全连接层部分的日志文件,卷积部分得到的featuremap为4×4×50,全连接部分是将featuremap展开成一维向量再与全连接相连。所以单样本前向传播计算量为:4×4×50×500 = 400 000,参数数量为4×4×50×500 = 400 000。在全连接中计算量和参数比始终为1,就是源于全连接的特性。
conv-1的计算量是ip1的0.72,而参数是0.00125。
也就是说卷积层主要是大大减少了连接参数,所以在CNN网络中一般卷积层参数量占比小,计算量占比大,而全连接中参数量占比大,计算量占比小。大致卷积层的计算量是全连接的20%。
所以我们需要减少网络参数、权值裁剪时主要针对全连接层;进行计算优化时,重点放在卷积层。
卷积层的优化方法:
从VGG, GoogleNet,ResNet的演变,很有可能是因为卷积核趋近与最小的3*3与1*1。
所以未来CNN的发展可能是fully 1*1 convolutional layer network?
即1×1 network + Spatial Contexts + Cross-layer contexts。
卷积层的基本原理就是图像的二维卷积,即将一个二维卷积模板先翻转(旋转180°),再以步长stride进行滑动,滑动一次则进行一次模板内的对应相乘求和作为卷积后的值。在CNN的卷积层中,首先是卷积层维度提升到三维、四维,与二维图分别进行卷积,然后合并,这里的卷积一般是相关操作,即不做翻转。具体如下图所示:
.
上图中左边的一幅输入图的三个通道,中间是卷积层,尺寸为3*3*3*2,这里就是三维卷积,得到的特征图还是一个通道,有两个三维卷积得到两个featuremap。
我们以caffe中的LeNet-5的lenet.prototxt为例。
一、卷积层
name: "LeNet"layer {
name: "data"
type: "Input"
top: "data"
input_param { shape: { dim: 64 dim: 1 dim: 28 dim: 28 } }
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
可以看到整个CNN的输入是28×28的灰度图,batchsize是64。第一个卷积层是5×5×20的尺寸,即卷积核为5×5,有20个。第一个卷积层之后有一个max pooling 层。下面我们来看一下日志文件。
I0405 18:22:46.263157 13500 db_lmdb.cpp:40] Opened lmdb ./mnist_train_lmdb
I0405 18:22:46.366945 13112 data_layer.cpp:41] output data size: 64,1,28,28
I0405 18:22:46.369945 13112 net.cpp:150] Setting up mnist
I0405 18:22:46.369945 13112 net.cpp:157] Top shape: 64 1 28 28 (50176)
I0405 18:22:46.369945 13112 net.cpp:157] Top shape: 64 (64)
I0405 18:22:46.369945 13112 net.cpp:165] Memory required for data: 200960
I0405 18:22:46.369945 13112 layer_factory.hpp:77] Creating layer conv1
I0405 18:22:46.369945 13112 net.cpp:100] Creating Layer conv1
I0405 18:22:46.369945 13112 net.cpp:444] conv1 <- data
I0405 18:22:46.369945 13112 net.cpp:418] conv1 -> conv1
I0405 18:22:46.372946 11592 common.cpp:36] System entropy source not available, using fallback algorithm to generate seed instead.
I0405 18:22:48.350821 13112 net.cpp:150] Setting up conv1
I0405 18:22:48.351820 13112 net.cpp:157] Top shape: 64 20 24 24 (737280)
I0405 18:22:48.351820 13112 net.cpp:165] Memory required for data: 3150080
I0405 18:22:48.351820 13112 layer_factory.hpp:77] Creating layer pool1
I0405 18:22:48.351820 13112 net.cpp:100] Creating Layer pool1
I0405 18:22:48.351820 13112 net.cpp:444] pool1 <- conv1
I0405 18:22:48.351820 13112 net.cpp:418] pool1 -> pool1
I0405 18:22:48.351820 13112 net.cpp:150] Setting up pool1
I0405 18:22:48.351820 13112 net.cpp:157] Top shape: 64 20 12 12 (184320)
I0405 18:22:48.351820 13112 net.cpp:165] Memory required for data: 3887360输入为28×28的单通道图,经过一层卷积以后输出为24×24×20,因为边界处理
4000
所以卷积完尺寸为28-5+1 = 24。卷积核的数量为20,所以conv-1的尺寸如上。再经过一层pooling层尺寸为12×12×20。则单样本前向传播计算量为:5×5×24×24×20 = 288 000,实际计算量还应乘以batchsize = 64。卷积层参数数量为:5×5×20
= 500。计算量和参数比为:288000/500 = 576.
下面看一下全连接层的情况。
二、全连接层
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}第一个全连接层的输出元素个数500。I0405 18:22:48.366821 13112 net.cpp:157] Top shape: 64 50 4 4 (51200)
I0405 18:22:48.366821 13112 net.cpp:165] Memory required for data: 4911360
I0405 18:22:48.366821 13112 layer_factory.hpp:77] Creating layer ip1
I0405 18:22:48.367826 13112 net.cpp:100] Creating Layer ip1
I0405 18:22:48.367826 13112 net.cpp:444] ip1 <- pool2
I0405 18:22:48.367826 13112 net.cpp:418] ip1 -> ip1
I0405 18:22:48.375823 13112 net.cpp:150] Setting up ip1
I0405 18:22:48.375823 13112 net.cpp:157] Top shape: 64 500 (32000)
I0405 18:22:48.375823 13112 net.cpp:165] Memory required for data: 5039360
I0405 18:22:48.375823 13112 layer_factory.hpp:77] Creating layer relu1
I0405 18:22:48.375823 13112 net.cpp:100] Creating Layer relu1
I0405 18:22:48.375823 13112 net.cpp:444] relu1 <- ip1
I0405 18:22:48.375823 13112 net.cpp:405] relu1 -> ip1 (in-place)
I0405 18:22:48.376822 13112 net.cpp:150] Setting up relu1
I0405 18:22:48.376822 13112 net.cpp:157] Top shape: 64 500 (32000)
I0405 18:22:48.376822 13112 net.cpp:165] Memory required for data: 5167360上图是全连接层部分的日志文件,卷积部分得到的featuremap为4×4×50,全连接部分是将featuremap展开成一维向量再与全连接相连。所以单样本前向传播计算量为:4×4×50×500 = 400 000,参数数量为4×4×50×500 = 400 000。在全连接中计算量和参数比始终为1,就是源于全连接的特性。
三、分析对比
conv-1的计算量参数比为576,ip1的计算量参数比为1。conv-1的计算量是ip1的0.72,而参数是0.00125。
也就是说卷积层主要是大大减少了连接参数,所以在CNN网络中一般卷积层参数量占比小,计算量占比大,而全连接中参数量占比大,计算量占比小。大致卷积层的计算量是全连接的20%。
所以我们需要减少网络参数、权值裁剪时主要针对全连接层;进行计算优化时,重点放在卷积层。
卷积层的优化方法:
1. Low rank(低秩):(单层到多层)SVD分解fc层和卷积核,tensor展开。
2. Pruning(剪枝):去掉某些神经元连接训练找到重要的连接。
3. Quantization(量化)权值量化,霍夫曼编码,codebook编码,hashed-net,PQ-CNN。
4. Fixed-point/binary net,BNN。
CNN的发展方向:1.小--模型有效且参数少
代表方法:NIN(network in network)2.快--运行速度快
matrix decomposition、pruning、硬件提升3.准--与大模型有相当的准确率
cross-layer regularization、micro-structures从VGG, GoogleNet,ResNet的演变,很有可能是因为卷积核趋近与最小的3*3与1*1。
所以未来CNN的发展可能是fully 1*1 convolutional layer network?
即1×1 network + Spatial Contexts + Cross-layer contexts。

相关文章推荐
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 【深度学习-CNN】CNN中的参数与计算量
- 深度学习 14. 深度学习调参,CNN参数调参,各个参数理解和说明以及调整的要领。underfitting和overfitting的理解,过拟合的解释。
- MXNET:深度学习计算-模型参数
- MATLAB深度学习CNN包计算次数统计
- 深度学习 14. 深度学习调参,CNN参数调参,各个参数理解和说明以及调整的要领。underfitting和overfitting的理解,过拟合的解释。
- MATLAB深度学习CNN包的代码详解补充及各变量参数说明
- 深度学习Matlab工具箱代码注释——cnnsetup.m
- [caffe]深度学习之CNN检测object detection方法摘要介绍
- 参数服务器在分布式深度学习的应用
- 京东DNN实验室:大数据、深度学习与计算平台的实践
- 深度学习(DL)与卷积神经网络(CNN)学习笔记随笔-02-基于Python的卷积运算