Spring Cloud应用进行服务追踪分析(Zipkin和spring cloud Sleuth)
2017-05-22 11:12
1111 查看
参考文章一:
摘要: 本文简单介绍了如何利用Zipkin对SpringCloud应用进行服务分析。在实际的应用场景中,Zipkin可以结合压力测试工具一起使用,分析系统在大压力下的可用性和性能。设想这么一种情况,如果你的微服务数量逐渐增大,服务间的依赖关系越来越复杂,怎么分析它们之间的调用关系及相互的影响?
服务追踪分析
一个由微服务构成的应用系统通过服务来划分问题域,通过REST请求服务API来连接服务来完成完整业务。对于入口的一个调用可能需要有多个后台服务协同完成,链路上任何一个调用超时或出错都可能造成前端请求的失败。服务的调用链也会越来越长,并形成一个树形的调用链。
随着服务的增多,对调用链的分析也会越来越负责。设想你在负责下面这个系统,其中每个小点都是一个微服务,他们之间的调用关系形成了复杂的网络。
针对服务化应用全链路追踪的问题,Google发表了Dapper论文,介绍了他们如何进行服务追踪分析。其基本思路是在服务调用的请求和响应中加入ID,标明上下游请求的关系。利用这些信息,可以可视化地分析服务调用链路和服务间的依赖关系。
Spring Cloud Sleuth和Zipkin
对应Dpper的开源实现是Zipkin,支持多种语言包括JavaScript,Python,Java, Scala, Ruby, C#, Go等。其中Java由多种不同的库来支持。在这个示例中,我们准备开发两个基于Spring Cloud的应用,利用Spring Cloud Sleuth来和Zipkin进行集成。Spring Cloud Sleuth是对Zipkin的一个封装,对于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server发送采集信息等全部自动完成。
这是Spring Cloud Sleuth的概念图。
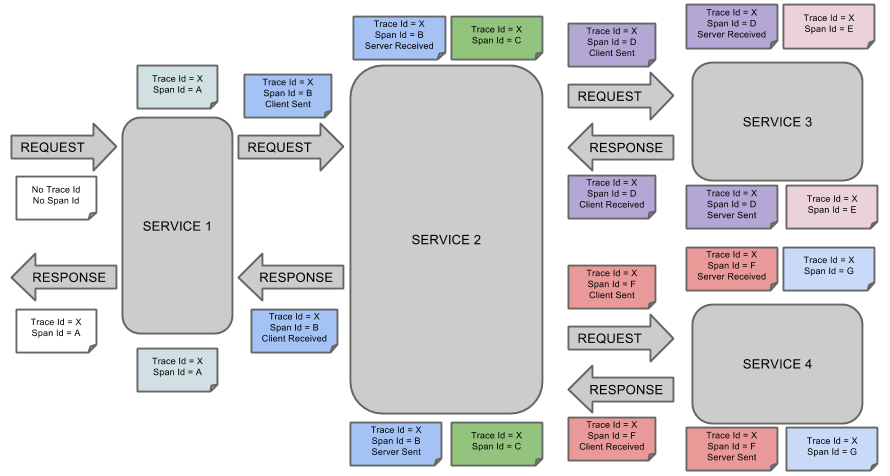
服务REST调用
本次演示的服务有两个:tracedemo做为前端服务接收用户的请求,tracebackend为后端服务,tracedemo通过http协议调用后端服务。
利用RestTemplate进行HTTP请求调用
tracedemo应用通过restTemplate调用后端tracedemo服务,注意,URL中指明tracedemo的地址为backend。
@RequestMapping("/")
public String callHome(){
LOG.log(Level.INFO, "calling trace demo backend");
return restTemplate.getForObject("http://backend:8090", String.class);
}后端服务响应HTTP请求,输出一行日志后返回经典的“hello world”。
@RequestMapping("/")
public String home(){
LOG.log(Level.INFO, "trace demo backend is being called");
return "Hello World.";
}
引入Sleuth和Zipkin依赖包
可以看到,这是典型的两个spring应用通过RestTemplate进行访问的方式,哪在HTTP请求中注入追踪信息并把相关信息发送到Zipkin Server呢?答案在两个应用所加载的JAR包里。本示例采用gradle来构建应用,在build.gradle中加载了sleuth和zipkin相关的JAR包:
dependencies {
compile('org.springframework.cloud:spring-cloud-starter-sleuth')
compile('org.springframework.cloud:spring-cloud-sleuth-zipkin')
testCompile('org.springframework.boot:spring-boot-starter-test')
}Spring应用在监测到Java依赖包中有sleuth和zipkin后,会自动在RestTemplate的调用过程中向HTTP请求注入追踪信息,并向Zipkin Server发送这些信息。
哪么Zipkin Server的地址又是在哪里指定的呢?答案是在application.properties中:
spring.zipkin.base-url=http://zipkin-server:9411
注意Zipkin Server的地址为
zipkin-server。
构建Docker镜像
为这两个服务创建相同的Dockerfile,用于生成Docker镜像:FROM java:8-jre-alpine RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.ustc.edu.cn/' /etc/apk/repositories VOLUME /tmp ADD build/libs/*.jar app.jar RUN sh -c 'touch /app.jar' ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/app.jar"]
构建容器镜像的步骤如下:
cd tracedemo ./gradlew build docker build -t zipkin-demo-frontend . cd ../tracebackend ./gradlew build docker build -t zipkin-demo-backend .
构建镜像完成后用
docker push命令上传到你的镜像仓库。
Zipkin Server
利用Annotation声明方式创建Zipkin
在build.gradle中引入Zipkin依赖包。dependencies {
compile('org.springframework.boot:spring-boot-starter')
compile('io.zipkin.java:zipkin-server')
runtime('io.zipkin.java:zipkin-autoconfigure-ui')
testCompile('org.springframework.boot:spring-boot-starter-test')
}在主程序Class增加一个注解
@EnableZipkinServer
@SpringBootApplication
@EnableZipkinServer
public class ZipkinApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinApplication.class, args);
}
}在
application.properties将端口指定为9411。
server.port=9411
构建Docker镜像
Dockerfile和前面的两个服务一样,这里就不重复了。
在阿里云容器服务上部署
创建docker-compose.yml文件,内容如下:version: "2" services: zipkin-server: image: registry.cn-hangzhou.aliyuncs.com/jingshanlb/zipkin-demo-server labels: aliyun.routing.port_9411: http://zipkin restart: always frontend: image: registry.cn-hangzhou.aliyuncs.com/jingshanlb/zipkin-demo-frontend labels: aliyun.routing.port_8080: http://frontend links: - zipkin-server - backend restart: always backend: image: registry.cn-hangzhou.aliyuncs.com/jingshanlb/zipkin-demo-backend links: - zipkin-server restart: always
在阿里云容器服务上
使用编排模版创建应用,访问zipkin端点,可以看到服务分析的效果。
访问前端应用3次,页面显示3次服务调用。
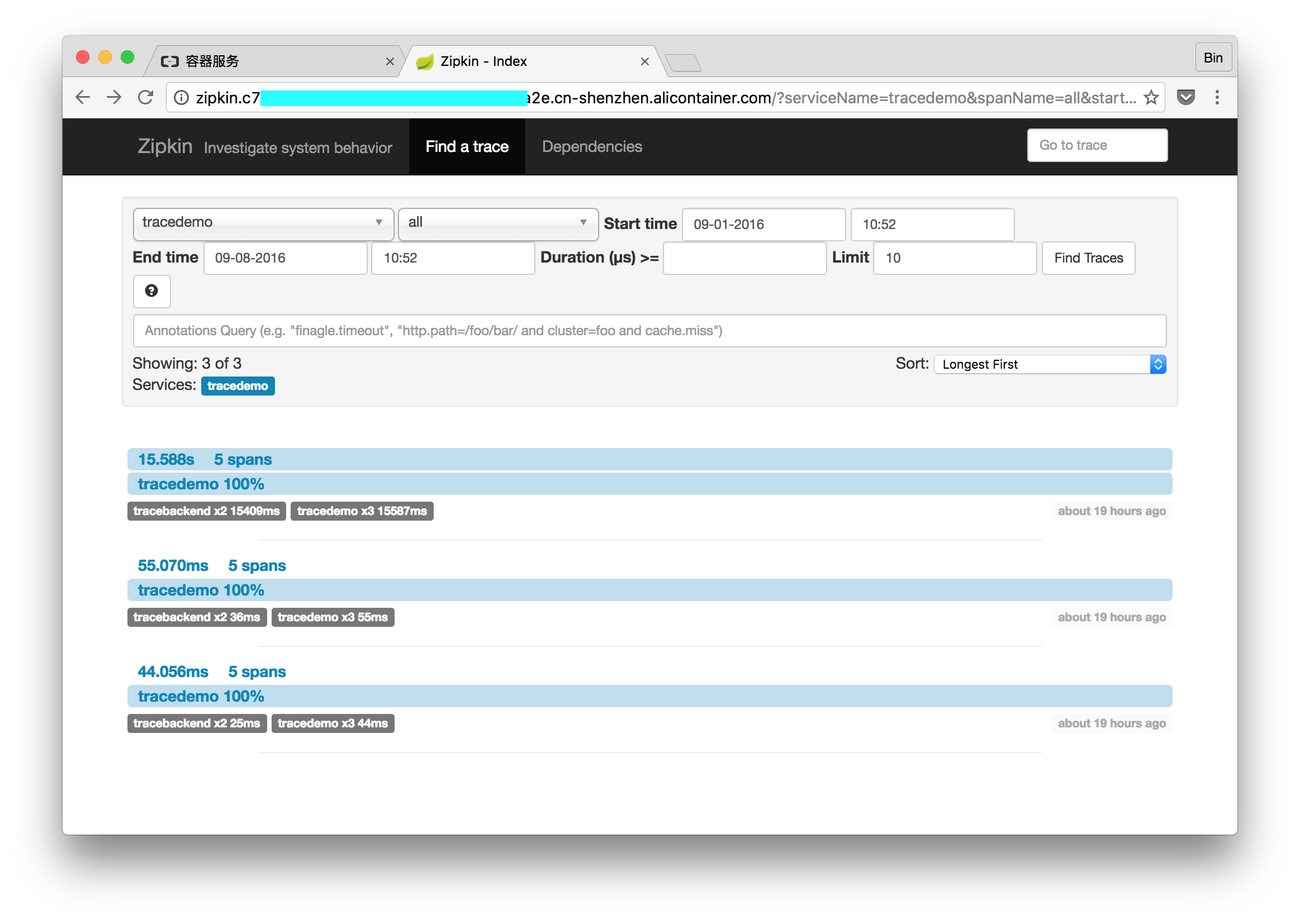
点击其中任意一个trace,可以看到请求链路上不同span所花费的时间。

进入Dependencies页面,还可以看到服务之间的依赖关系。
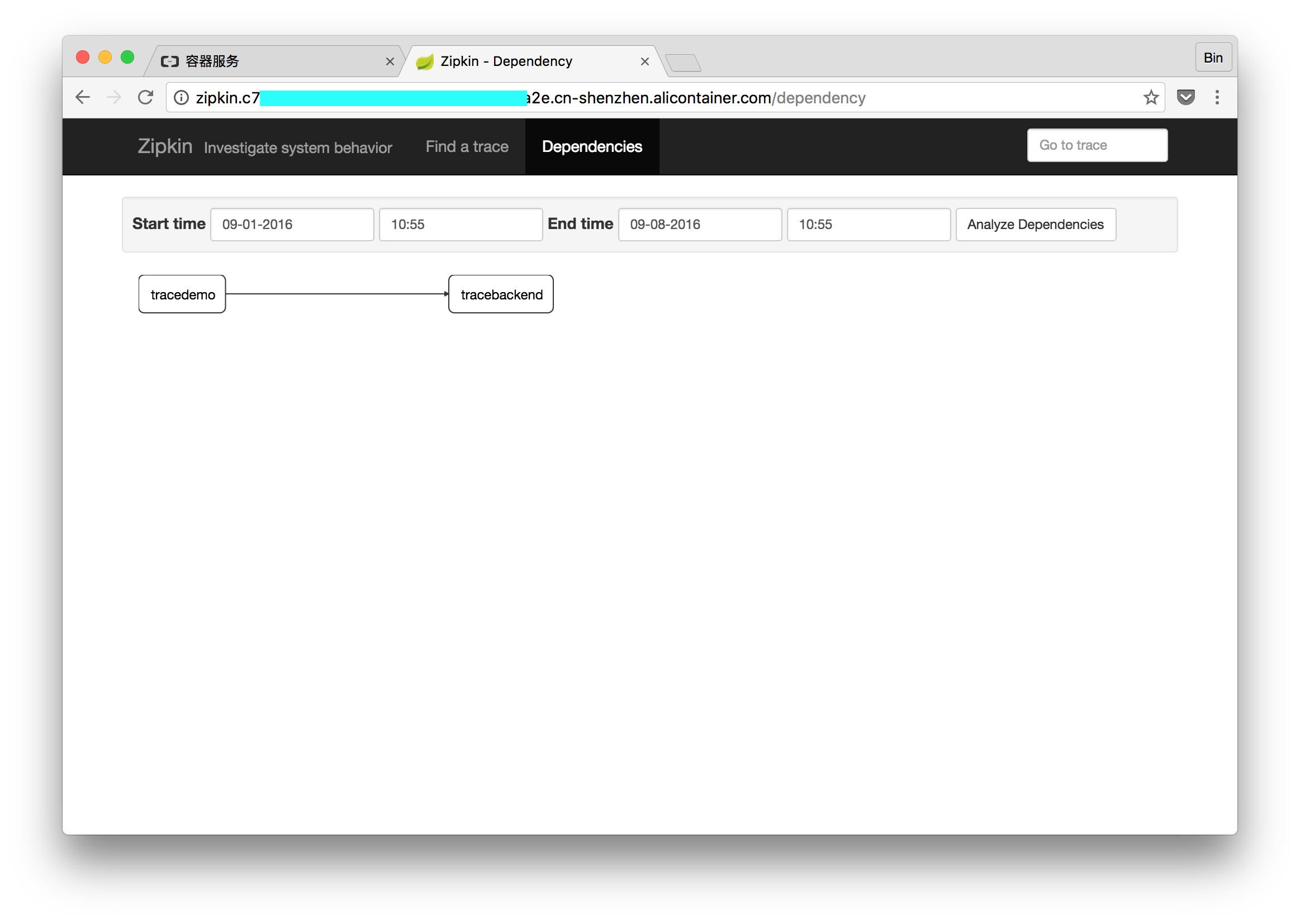
从这个过程可以看出,Zipkin和Spring Cloud的集成做得很好。而且对服务追踪分析的可视化也很直观。
注意的是,在生产环境中还需要为Zipkin配置数据库,这里就不详细介绍了。
本文的示例代码在此:https://github.com/binblee/zipkin-demo
小节
本文简单介绍了如何利用Zipkin对SpringCloud应用进行服务分析。在实际的应用场景中,Zipkin可以结合压力测试工具一起使用,分析系统在大压力下的可用性和性能。这部分内容未来会在DevOps系列中继续介绍。本文为云栖社区原创内容,未经允许不得转载,如需转载请发送邮件至yqeditor@list.alibaba-inc.com
参考文章二:(我参考的这个)
最近在学习spring cloud构建微服务,很多大牛都提供很多入门的例子帮助我们学习,对于我们这种英语不好的码农来说,效率着实提高不少。这两天学习到追踪微服务rest服务调用链路的问题,接触到zipkin,而spring cloud也提供了spring-cloud-sleuth来方便集成zipkin实现。在网络上找了好多文章,不过发现版本引入的maven依赖包,配置的参数都不完全相同。可能是因为版本更新太快 的原因,部分配置已经取消掉了。光看不动手始终是不够的,于是自己根据其他大神的博客以及github上作者的示例来自己练手试试。
我们准备了三个必要的程序来做测试,分别是
1、zipkin-server
负责数据收集以及信息展示功能。
2、provider
负责微服务的生产者,对外提供 “http://127.0.0.1:10001/add/被加数/加数” 的rest地址来完成一个简单的两整数相加的功能。
3、consumer
负责微服务的调用,对外提供 "http://127.0.0.1:10002/test/add/被加数/加数" 的rest地址,当访问此地址时,使用feign方式调用provider的rest服务地址。得到计算结果后,显示在界面上。
三个程序功能非常简单,接下来我们看看每个程序的具体代码和配置。为了方便我们对三个模块开发,我们在父POM文件中添加了spring-boot和spring-cloud的依赖,避免子模块中需要写版本号
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.1.RELEASE</version> </parent> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Dalston.RELEASE</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement>
接下来我们看看三个程序中的相关配置
一、zipkin-server
首先,我们添加maven依赖配置
<dependencies> <!--使用@EnableZipkinServer注解方式只需要依赖如下两个包--> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-server</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--保存到数据库需要如下依赖--> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-storage-mysql</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency>
线下测试环境中,我们可以将数据保存到内存中,但是生产环境还是需要将数据持久化中。原生支持了很多产品,例如ES、数据库等,本例中我们采用持久化到mysql中的方式来演示。
我们写一个启动类ZipkinServer,代码非常简单,如下
@SpringBootApplication
@EnableZipkinServer //启动ZipkinServer段
public class ZipkinServer {
public static void main(String[] args) {
SpringApplication.run(ZipkinServer.class, args);
}
}接下来我们配置application.properties配置文件
server.port=9411spring.application.name=zipkin-server
#zipkin数据保存到数据库中需要进行如下配置
#表示当前程序不使用sleuth
spring.sleuth.enabled=false
#表示zipkin数据存储方式是mysql
zipkin.storage.type=mysql
#数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素
spring.datasource.schema[0]=classpath:/zipkin.sql
#spring boot数据源配置
spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.initialize=true
spring.datasource.continue-on-error=true
从以上配置可以看到我们创建了一个 zipkin的数据库,初始化脚本为classpath下的zipkin.sql的sql文件。具体内容见附件。
启动后 无异常输出,这样我们的zipkin-server程序就OK了

二、provider和consumer
provider和consumer两个程序,与其他基础代码我们就不多讲了(相信学些到这一步的童鞋,都已经对spring cloud创建微服务以上手了),两个程序在spring-cloud-sleuth相关的配置都是一样。
首先,我们要在二者的POM文件中添加依赖,引入zipkin客户端自动配置相关依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency>
其次,在配置文件application中,我们加入zipkin-server收集信息的地址
#配置zipKin Server的地址 spring.zipkin.base-url=http://127.0.0.1:9411
这样我们的两个微服务就配置好了(注意这里我们并不会再说明如何写rest接口和使用feign调用rest接口)
三、测试
启动我们的三个程序。然后访问zipkin-server程序的UI界面地址http://127.0.0.1:9411,可以看到如下的效果
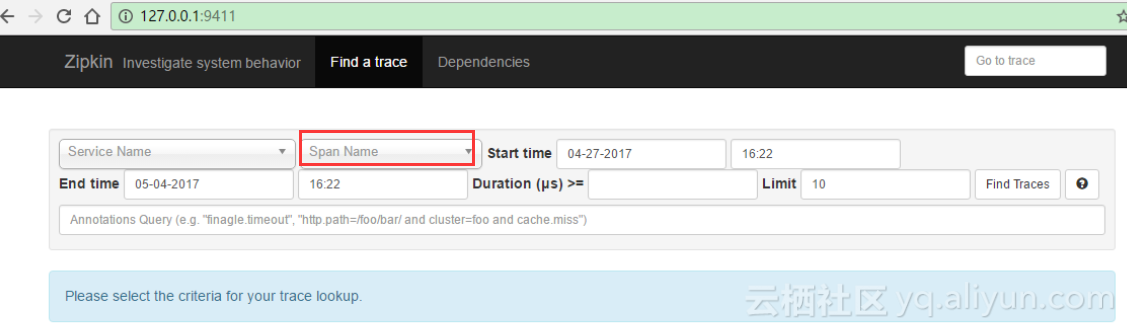
其中Span Name选项为灰色不可选,说明目前没有数据,我们查看数据库也可以看到没有任何数据信息。接下来我们访问consumer提供的访问地址 “http://127.0.0.1:10001/add/被加数/加数” 刷新几次之后,我们再次刷新我们的zipkin界面,可以看到Span
Name已经可以选择了。
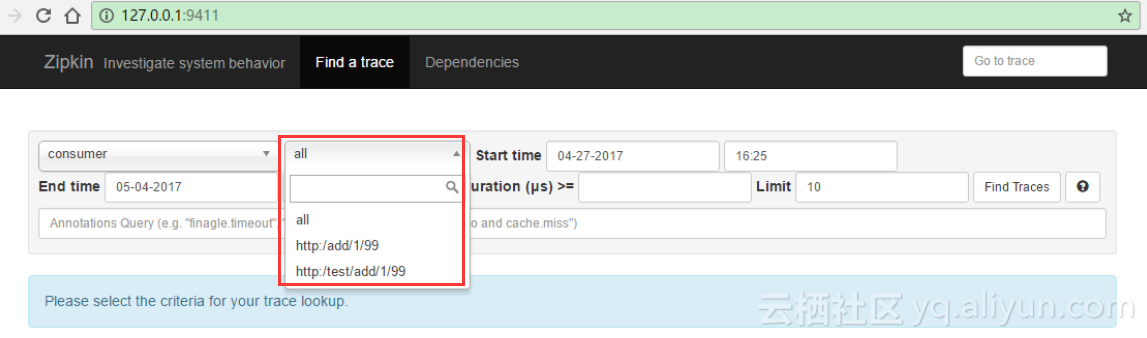
点击Find Traces按钮,我们可以看到调用的链路和耗时情况,点击Dependencies,我们可以看到provider和consumer的调用图

OK,我们的简单实用spring-cloud-sleuth+zipkin的例子就完成了。
注意:
测试时请将consumer访问地址中的“被加数”和“加数”替换为两个整数。
四、拓展
在测试的过程中我们会发现,有时候,程序刚刚启动后,刷新几次,并不能看到任何数据,原因就是我们的spring-cloud-sleuth收集信息是有一定的比率的,默认的采样率是0.1,配置此值的方式在配置文件中增加spring.sleuth.sampler.percentage参数配置(如果不配置默认0.1),如果我们调大此值为1,可以看到信息收集就更及时。但是当这样调整后,我们会发现我们的rest接口调用速度比0.1的情况下慢了很多,即时在0.1的采样率下,我们多次刷新consumer的接口,也会出现如下情况
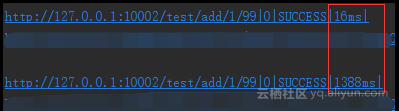
红色框中上下两个数据是两次耗时信息,可以看到相差非常大,如果取消spring-cloud-sleuth后我们再测试,会发现并没有这种情况,可以看到这种方式追踪服务调用链路会给我们业务程序性能带来一定的影响。
其实,我们仔细想想也可以总结出这种方式的几种缺陷
缺陷1:zipkin客户端向zipkin-server程序发送数据使用的是http的方式通信,每次发送的时候涉及到连接和发送过程。
缺陷2:当我们的zipkin-server程序关闭或者重启过程中,因为客户端收集信息的发送采用http的方式会被丢失。
针对以上两个明显的缺陷,改进的办法是
1、通信采用socket或者其他效率更高的通信方式。
2、客户端数据的发送尽量减少业务线程的时间消耗,采用异步等方式发送收集信息。
3、客户端与zipkin-server之间增加缓存类的中间件,例如redis、MQ等,在zipkin-server程序挂掉或重启过程中,客户端依旧可以正常的发送自己收集的信息。
相信采用以上三种方式会很大的提高我们的效率和可靠性。其实spring-cloud以及为我们提供采用MQ或redis等其他的采用socket方式通信,利用消息中间件或数据库缓存的实现方式。下一次我们再来测试spring-cloud-sleuth-zipkin-stream方式的实现。
参考文档:
https://github.com/spring-cloud/spring-cloud-sleuth
参考文章三:(监听消息的方式,我参考的这个)
在上一节《spring-cloud-sleuth+zipkin追踪服务实现(一)》中,我们使用zipkin-server、provider、consumer三个程序实现了使用http方式进行通信,数据持久化到数据库中的服务调用链路追踪实现。针对其中存在的影响性能和可能丢失数据的缺陷,在这一节我们使用spring-cloud的为我们提供的实现的方式来测试这种情况。我们还是使用之前上一节中的三个程序做修改,方便大家看到对比不同点。
一、zipkin-server
要将http方式改为通过MQ通信,我们要将依赖的原来依赖的io.zipkin.java:zipkin-server换成spring-cloud-sleuth-zipkin-stream和spring-cloud-starter-stream-rabbit,并且移除zipkin-autoconfigure-storage-mysql,因为spring-cloud-sleuth-zipkin-stream会自动为我们引入,全部maven依赖如下:
<dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> </dependency> <!--zipkin依赖--> <!--此依赖会自动引入spring-cloud-sleuth-stream并且引入zipkin的依赖包--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--保存到数据库需要如下依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> </dependencies>
添加以上maven依赖后,我们将启动类ZipkinServer中@EnableZipkinServer注解替换成@EnableZipkinStreamServer
@SpringBootApplication
@EnableDiscoveryClient //注册到eureka
@EnableZipkinStreamServer //使用Stream方式启动ZipkinServer
public class ZipkinServer {
public static void main(String[] args) {
SpringApplication.run(ZipkinServer.class, args);
}
}点击@EnableZipkinStreamServer注解的源码我们可以看到它也引入了@EnableZipkinServer注解,同时还创建了一个rabbit-mq的消息队列监听器。

以方便接收从消息客户端收集发过来的mq消息。由于使用了消息中间件rabbit-mq,所以我们还需要在配置文件中配置我们的MQ连接配置
#rabbitmq配置 spring.rabbitmq.host=127.0.0.1 spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
为了避免http通信的干扰,我们将原来的监听端口有9411更改为9412,启动程序,未报错且能够看到rabbit连接日志,说明程序启动成功。
二、provider和consumer
与上一节中的配置一样,客户端的配置也非常简单,maven依赖只需要将原来的spring-cloud-starter-zipkin替换为如下两个依赖即可
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency>
此外,在配置文件中也加上连接MQ的配置
#rabbitmq配置 spring.rabbitmq.host=127.0.0.1 spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
在第一节中,客户端连接zipkin-server是使用的配置
spring.zipkin.base-url=http://127.0.0.1:9411, 由于不再使用这种方式,我们将它取消掉。同时,我们将数据库中的数据也清空。
我们如上一节《spring-cloud-sleuth+zipkin追踪服务实现(一)》中一样,访问consumer的外部http地址("http://127.0.0.1:10001/add/被加数/加数")
。然后我们访问zipkin-server的地址“http://127.0.0.1:9412/” ,我们可以看到如下的效果,说明rabbit-mq方式通信的sleuth功能已经生效了。
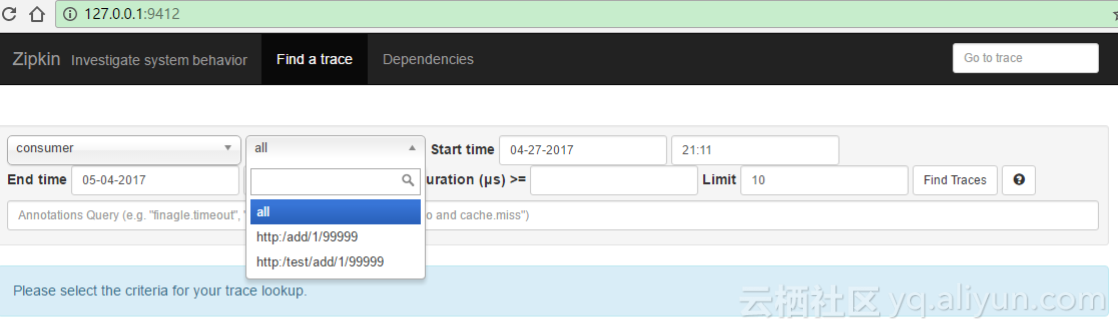
我们多次访问consumer的地址可以看到日志中,请求的耗时时间不会再次出现突然耗时特长的情况。
为了体验MQ通信给我们带来的数据不丢失的特点,我们将数据库中的数据清空,然后刷新zipkin-server的界面,可以看到不再有数据
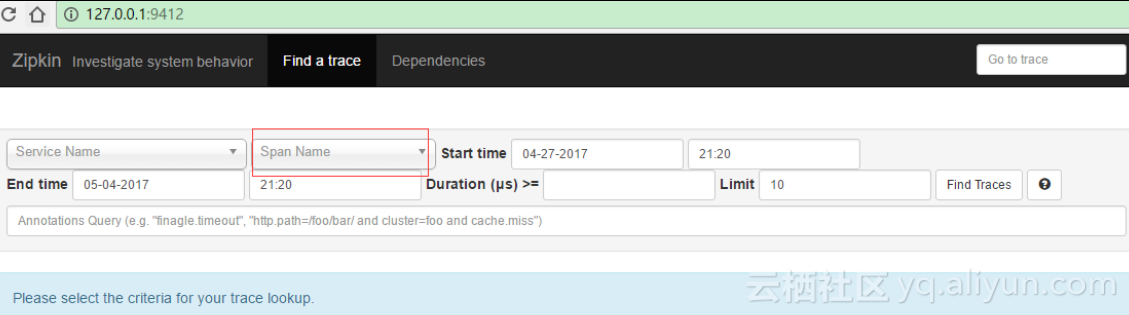
然后我们将zipkin-server程序想关闭,然后再多次访问consumer的地址,之后,我们重启zipkin-server程序,启动成功后访问UI界面
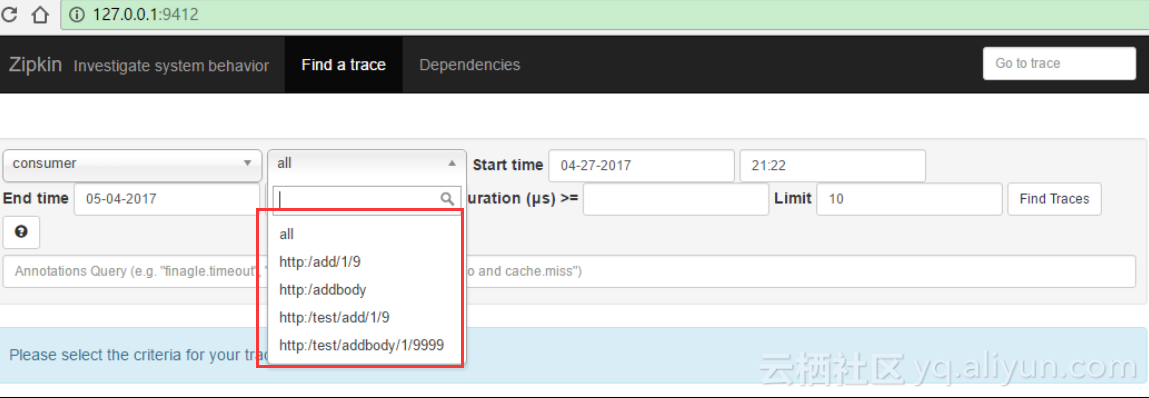
很快看到Span Name选项有数据可以选择了,同时数据库中的记录条数也不再是之前的0条了

如此说明我们的zipkin重启后,从MQ中成功获取出了在关闭这段时间里provider和consumer产生的信息数据。这样我们使用spring-cloud-sleuth-stream+zipkin方式的rest服务调用追踪功能就OK了。
注意:
测试时请将consumer访问地址中的“被加数”和“加数”替换为两个整数。

相关文章推荐
- 利用Zipkin对Spring Cloud应用进行服务追踪分析
- 利用Zipkin对Spring Cloud应用进行服务追踪分析
- 利用Zipkin对Spring Cloud应用进行服务追踪分析
- 利用Zipkin对Spring Cloud应用进行服务追踪分析
- 利用Zipkin对Spring Cloud应用进行服务追踪分析
- spring-cloud-sleuth+zipkin追踪服务实现
- Spring Boot + Spring Cloud 构建微服务系统(八):分布式链路追踪(Sleuth、Zipkin)
- Spring Cloud Sleuth服务链路追踪(zipkin)(转)
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
- SpringCloud之服务链路追踪(Spring Cloud Sleuth) |第九章 -yellowcong
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
- 企业级 SpringCloud 教程 (九) 服务链路追踪(Spring Cloud Sleuth)
- Spring Cloud Sleuth Zipkin 展示追踪数据
- Spring Cloud搭建微服务架构----使用Zipkin做服务链路追踪
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)
- 服务链路追踪(Spring Cloud Sleuth)
- springcloud(十二):使用Spring Cloud Sleuth和Zipkin进行分布式链路跟踪
- 史上最简单的SpringCloud教程 | 第九篇: 服务链路追踪(Spring Cloud Sleuth)