Linux脚本攻略学习笔记10
2017-05-20 13:29
471 查看
今天主要说说grep吧,在讲grep之前,先上一张正则表达式的图,以供查询:

grep命令作为Unix中用于文本搜索的神奇工具,能够接受正则表达式,生成各种格式的输出,除此之外,他还有大量的有趣的选项,让我们看看具体的用法。
(1)搜索包含特定模式的文本行:
$grep pattern filename
this is the line containing pattern(2)也可以像下面这样从stdin中读取:
$ echo -e "this is a word\nnext line"|grep word
this is a word

(3)单个grep命令也可以对多个文件进行搜索:
$ grep "match_text" file1 file2 file3 ...(4) 用--color选项可以在输出行中着重标记出匹配到的单词:
$grep word filename --color=auto
this is the line containing word

(5) grep命令只解释match_text中某些特殊字符。如果要使用正则表达式,需要添加-E选项----这意味着使用扩展正则表达式。或者也可以使用默认允许正则表达式的grep命令---egrep。例如:
$grep -E "[a-z]+" filename
或者
$egrep "[a-z]+" filename(6) 只输出文件中匹配到的文本部分,可以使用选项-o:
$ echo this is a line | egrep -o "[a-z]+\."
line


(7) 要打印除包含match_pattern行之外的所有的行,可以使用:
$ grep -v match_pattern line选项-v可以将匹配结果进行反转

(8) 统计文件或文本中包含匹配字符串的行数:
$ grep -c "text" filename需要注意的是-c只是统计匹配行的数量,并不是匹配的次数。例如:

尽管有6个匹配项,但命令只打印出2,这是因为只有两个匹配行。在单行中出现的多次匹配只能被统计一次。
(9)要统计文件中统计匹配项的数量,可以使用下面的技巧:
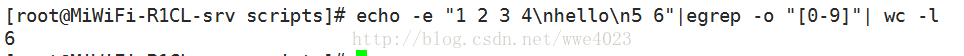
(10)-n选项可以打印匹配的行号。
下次说一说grep的更多特性
grep命令作为Unix中用于文本搜索的神奇工具,能够接受正则表达式,生成各种格式的输出,除此之外,他还有大量的有趣的选项,让我们看看具体的用法。
(1)搜索包含特定模式的文本行:
$grep pattern filename
this is the line containing pattern(2)也可以像下面这样从stdin中读取:
$ echo -e "this is a word\nnext line"|grep word
this is a word
(3)单个grep命令也可以对多个文件进行搜索:
$ grep "match_text" file1 file2 file3 ...(4) 用--color选项可以在输出行中着重标记出匹配到的单词:
$grep word filename --color=auto
this is the line containing word
(5) grep命令只解释match_text中某些特殊字符。如果要使用正则表达式,需要添加-E选项----这意味着使用扩展正则表达式。或者也可以使用默认允许正则表达式的grep命令---egrep。例如:
$grep -E "[a-z]+" filename
或者
$egrep "[a-z]+" filename(6) 只输出文件中匹配到的文本部分,可以使用选项-o:
$ echo this is a line | egrep -o "[a-z]+\."
line
(7) 要打印除包含match_pattern行之外的所有的行,可以使用:
$ grep -v match_pattern line选项-v可以将匹配结果进行反转
(8) 统计文件或文本中包含匹配字符串的行数:
$ grep -c "text" filename需要注意的是-c只是统计匹配行的数量,并不是匹配的次数。例如:
尽管有6个匹配项,但命令只打印出2,这是因为只有两个匹配行。在单行中出现的多次匹配只能被统计一次。
(9)要统计文件中统计匹配项的数量,可以使用下面的技巧:
(10)-n选项可以打印匹配的行号。
下次说一说grep的更多特性

相关文章推荐
- Linux脚本攻略学习笔记13
- linux脚本攻略学习笔记17
- Linux脚本攻略学习笔记14
- Linux脚本攻略学习笔记12
- [linux-shell]脚本攻略学习笔记
- Linux 脚本攻略学习笔记8
- Linux脚本学习攻略笔记16
- Linux 学习笔记_10_Shell编程_1_Shell编程语法
- [linux学习笔记]第2天:时间管理,命令帮助信息,文本查看,权限及用户管理,BASH和变量,脚本
- Linux学习笔记10-文件系统
- 初次学习linux脚本文件笔记
- Linux Shell 脚本攻略-学习笔记
- linux 脚本学习笔记
- Linux新手生存笔记[10]——shell脚本基础3-函数及常用命令
- 学习笔记 linux 编译文件用shell脚本实现
- [暑假学习笔记]二、Linux Shell 脚本攻略2
- shell脚本攻略学习笔记(九)管理重任
- [暑假学习笔记]四、Linux Shell 脚本攻略4
- linux shell 脚本攻略学习10--生成任意大小的文件和文本文件的交集与差集详解
- [暑假学习笔记]三、Linux Shell 脚本攻略3