linux/unix命令详解之sed
2017-05-19 12:43
405 查看
原文:
http://blog.pureisle.net/archives/1348.html
ps:我只能说别说你会sed。。。这篇综合很多sed文档写成。
1. 功能说明:利用script来处理文本文件。
语 法:sed [-hnV][-e(script)][-f (script文件) ][文本文件]
补充说明:sed可依照script的指令,来处理、编辑文本文件。
2. 定址
可以通过定址来定位你所希望编辑的行,该地址用数字构成,用逗号分隔的两个行数表示以这两行为起止的行的范围(包括行数表示的那两行)。如1,3表示1,2,3行,美元符号($)表示最后一行。范围可以通过数据,正则表达式或者二者结合的方式确定 。
3. sed命令(并非参数)
调用sed命令有两种形式:
sed [options] ‘command’ file(s)
sed [options] -f scriptfile file(s)
a\ 在当前行后面加入一行文本。
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
c\ 用新的文本改变本行的文本。
d 从模板块(Pattern space)位置删除行。
D 删除模板块的第一行。
i\ 在当前行上面插入文本。
h 拷贝模板块的内容到内存中的缓冲区。
H 追加模板块的内容到内存中的缓冲区
g 获得内存缓冲区的内容,并替代当前模板块中的文本。
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l 列表不能打印字符的清单。
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p 打印模板块的行。
P(大写)打印模板块的第一行。
q 退出Sed。
r file 从file中读行。
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file 写并追加模板块到file末尾。
W file 写并追加模板块的第一行到file末尾。
! 表示后面的命令对所有没有被选定的行发生作用。
s/rep/string/ 用string替换正则表达式re匹配的内容。
= 打印当前行号码。
# 把注释扩展到下一个换行符以前。
以下的是替换标记:
g表示行内全面替换。
p表示打印行。
w表示把行写入一个文件。
x表示互换模板块中的文本和缓冲区中的文本。
y表示把一个字符翻译为另外的字符(但是不用于正则表达式)
4. 选项
-e command, –expression=command 允许多台编辑。
-h, –help 打印帮助,并显示bug列表的地址。
-n, –quiet, –silent 取消默认输出。
-f, –filer=script-file 引导sed脚本文件名。
-V, –version 打印版本和版权信息。
5. 元字符集(熟悉正则就清楚多了)
^ 锚定行的开始 如:/^sed/匹配所有以sed开头的行。
$ 锚定行的结束 如:/sed$/匹配所有以sed结尾的行。
. 匹配一个非换行符的字符 如:/s.d/匹配s后接一个任意字符,然后是d。
* 匹配零或多个字符 如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] 匹配一个指定范围内的字符,如/[Ss]ed/匹配sed和Sed。
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。

保存匹配的字符,如s/
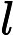

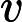

able/\1rs,loveable被替换成lovers。
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
\< 锚定单词的开始,如:/\ 锚定单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个o的行。
x\{m,\} 重复字符x,至少m次,如:/o\{5,\}/匹配至少有5个o的行。
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/o\{5,10\}/匹配5–10个o的行。
6. 实例
删除:d命令
$ sed '2d' #删除文件的第二行。
$ sed '2,$d' #删除文件的第二行到末尾所有行。
$ sed '$d’ #删除文件的最后一行。
$ sed 'N;$!P;$!D;$d' # 删除文件中的最后两行
# 删除文件中的最后10行
$ sed -e :a -e '$d;N;2,10ba' -e 'P;D' # 方法1
$ sed -n -e :a -e '1,10!{P;N;D;};N;ba' # 方法2
# 删除8的倍数行
$ gsed '0~8d' # 只对GNU sed有效
$ sed 'n;n;n;n;n;n;n;d;' # 其他sed
# 删除文件中的所有空行(与“grep '.' ”效果相同)
$ sed '/^$/d' # 方法1
$ sed '/./!d' # 方法2
# 只保留多个相邻空行的第一行并且删除文件顶部和尾部的空行。模拟“cat -s”
$ sed '/./,/^$/!d' #方法1,删除文件顶部的空行,允许尾部保留一空行
$ sed '/^$/N;/\n$/D' #方法2,允许顶部保留一空行,尾部不留空行
$ sed '/^$/N;/\n$/N;//D'# 只保留多个相邻空行的前两行。
$ sed '/./,$!d'# 删除文件顶部的所有空行
# 删除文件尾部的所有空行
$ sed -e :a -e '/^\n*$/{$d;N;ba' -e '}' # 对所有sed有效
$ sed -e :a -e '/^\n*$/N;/\n$/ba' # 同上,但只对 gsed 3.02.*有效
$ sed 's/^[ \t]*//;s/[ \t]*$//'#将每一行中的前导和拖尾的空白字符删除
$ sed '/test/d' #删除文件所有包含test的行。
$ sed '/test/!d' #删除文件未包含test的行。
$ sed -n '/^$/{p;h;};/./{x;/./p;}'# 删除每个段落的最后一行
$ sed '/Iowa/,/Montana/d'# 删除两个正则表达式之间的内容
# 删除文件中相邻的重复行(模拟“uniq”)只保留重复行中的第一行,其他行删除
$ sed '$!N; /^
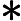
\n\1$/!P;
D'
#删除文件中的重复行,不管有无相邻。注意hold space所能支持的缓存大小,或者使用GNU sed。
$ sed -n 'G; s/\n/&&/; /^ Undefined
control sequence \n .*\n\1/d;
s/\n//; h; P'
$ sed '$!N; s/^
\n\1$/\1/;
t; D' # 删除除重复行外的所有行(模拟“uniq -d”)
替换:s命令
$ sed ‘s/test/mytest/g’ example—–在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。
*
$ sed 's/foo/bar/4' # 只替换每一行中的第四个“foo”字串
*
$ sed 's/
foo

/\1bar\2/'
# 替换倒数第二个“foo”
*
$ sed -n ‘s/^test/mytest/p’ example—–(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。
*
$ sed '/baz/s/foo/bar/g'# 只在行中出现字串“baz”的情况下将“foo”替换成“bar”
*
$ sed '/baz/!s/foo/bar/g'# 将“foo”替换成“bar”,并且只在行中未出现字串“baz”的情况下替换
*
# 不管是“scarlet”“ruby”还是“puce”,一律换成“red”
$ sed 's/scarlet/red/g;s/ruby/red/g;s/puce/red/g' #对多数的sed都有效
$ gsed 's/scarlet\|ruby\|puce/red/g' # 只对GNU sed有效
*
$ sed ‘s/^192.168.0.1/&localhost/’ example—–&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost。
*
$ sed -n ‘s/
able/\1rs/p’
example—–love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。
*
$ sed 's/^M$//' # 在bash/tcsh中,将按Ctrl-M改为按Ctrl-V。Unix环境:转换DOS的新行符(CR/LF)为Unix格式
*
$ sed ‘s#10#100#g’ example—–不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。
选定行的范围:逗号
*
$ sed -n ‘/test/,/check/p’ example—–所有在模板test和check所确定的范围内的行都被打印。
*
$ sed -n ’5,/^test/p’ example—–打印从第五行开始到第一个包含以test开始的行之间的所有行。
*
$ sed ‘/test/,/check/s/$/sed test/’ example—–对于模板test和check之间的行,每行的末尾用字符串sed test替换。$变成^当然就是行头了。
多点编辑:e命令
*
$ sed -e ’1,5d’ -e ‘s/test/check/’ example—–(-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行,第二条命令用check替换test。命令的执 行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
*
$ sed –expression=’s/test/check/’ –expression=’/love/d’ example—–一个比-e更好的命令是–expression。它能给sed表达式赋值。
从文件读入:r命令
*
$ sed ‘/test/r file’ example—–file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。
写入文件:w命令
*
$ sed -n ‘/test/w file’ example—–在example中所有包含test的行都被写入file里。
追加命令:a命令
*
$ sed ‘/^test/a\\—>this is a example’ example<—–’this is a example’被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。 * 追加命令:G命令 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 sed G # 在每一行后面增加一空行 # 将原来的所有空行删除并在每一行后面增加一空行。 sed '/^$/d;G' # 这样在输出的文本中每一行后面将有且只有一空行。 sed 'G;G' # 在每一行后面增加两行空行 sed '/regex/G'
# 在匹配式样“regex”的行之后插入一空行 sed '/regex/{x;p;x;}'# 在匹配式样“regex”的行之前插入一空行 sed '/regex/{x;p;x;G;}'# 在匹配式样“regex”的行之前和之后各插入一空行 # 在每5行后增加一空白行 (在第5,10,15,20,等行后增加一空白行) gsed '0~5G' # 只对GNU sed有效 sed 'n;n;n;n;G;' # 其他sed 插入:i命令 $ sed ‘/test/i\\ new line ————————-’ example
如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。 下一个:n命令 * $ sed ‘/test/{ n; s/aa/bb/; }’ example—–如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。 变形:y命令 * $ sed ’1,10y/abcde/ABCDE/’ example—–把1–10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。 退出:q命令 * $ sed ’10q’ example—–打印完第10行后,退出sed。
* sed -e :a -e '$q;N;11,$D;ba'# 显示文件中的最后10行 (模拟“tail”) 保持和获取:h命令和G命令 $ sed -e ‘/test/h’ -e ‘$G example—–在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保 持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中
的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。 保持和互换:h命令和x命令 * $ sed -e ‘/test/h’ -e ‘/check/x’ example —–互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换。 编号: # 为文件中的每一行进行编号(简单的左对齐方式)。这里使用了“制表符” # (tab,见本文末尾关于'\t'的用法的描述)而不是空格来对齐边缘。 sed = filename | sed 'N;s/\n/\t/'
* # 对文件中的所有行编号(行号在左,文字右端对齐)。 sed = filename | sed 'N; s/^/ /; s/ *




\n/\1
/' * # 对文件中的所有行编号,但只显示非空白行的行号。 sed '/./=' filename | sed '/./N; s/\n/ /' * # 计算行数 (模拟 "wc -l") sed -n '$=' 显示特定行: # 显示文件中的前10行 (模拟“head”的行为) sed 10q # 显示文件中的第一行 (模拟“head -1”命令) sed q # 显示文件中的最后10行 (模拟“tail”) sed -e :a -e '$q;N;11,$D;ba' # 显示文件中的最后2行(模拟“tail
-2”命令) sed '$!N;$!D' # 显示文件中的最后一行(模拟“tail -1”) sed '$!d' # 方法1 sed -n '$p' # 方法2 # 显示文件中的倒数第二行 sed -e '$!{h;d;}' -e x # 当文件中只有一行时,输入空行 sed -e '1{$q;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,显示该行 sed -e '1{$d;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,不输出 # 只显示匹配正则表达式的行(模拟“grep”)
sed -n '/regexp/p' # 方法1 sed '/regexp/!d' # 方法2 # 只显示“不”匹配正则表达式的行(模拟“grep -v”) sed -n '/regexp/!p' # 方法1,与前面的命令相对应 sed '/regexp/d' # 方法2,类似的语法 # 查找“regexp”并将匹配行的上一行显示出来,但并不显示匹配行 sed -n '/regexp/{g;1!p;};h' # 查找“regexp”并将匹配行的下一行显示出来,但并不显示匹配行 sed -n '/regexp/{n;p;}'
# 显示包含“regexp”的行及其前后行,并在第一行之前加上“regexp”所 # 在行的行号 (类似“grep -A1 -B1”) sed -n -e '/regexp/{=;x;1!p;g;$!N;p;D;}' -e h # 显示包含“AAA”、“BBB”或“CCC”的行(任意次序) sed '/AAA/!d; /BBB/!d; /CCC/!d' # 字串的次序不影响结果 # 显示包含“AAA”、“BBB”和“CCC”的行(固定次序) sed '/AAA.*BBB.*CCC/!d' # 显示包含“AAA”“BBB”或“CCC”的行
(模拟“egrep”) sed -e '/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d # 多数sed gsed '/AAA\|BBB\|CCC/!d' # 对GNU sed有效 # 显示包含“AAA”的段落 (段落间以空行分隔) # HHsed v1.5 必须在“x;”后加入“G;”,接下来的3个脚本都是这样 sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;' # 显示包含“AAA”“BBB”和“CCC”三个字串的段落 (任意次序) sed -e '/./{H;$!d;}'
-e 'x;/AAA/!d;/BBB/!d;/CCC/!d' # 显示包含“AAA”、“BBB”、“CCC”三者中任一字串的段落 (任意次序) sed -e '/./{H;$!d;}' -e 'x;/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d gsed '/./{H;$!d;};x;/AAA\|BBB\|CCC/b;d' # 只对GNU sed有效 # 显示包含65个或以上字符的行 sed -n '/^.\{65\}/p' # 显示包含65个以下字符的行 sed -n '/^.\{65\}/!p'
# 方法1,与上面的脚本相对应 sed '/^.\{65\}/d' # 方法2,更简便一点的方法 # 显示部分文本——从包含正则表达式的行开始到最后一行结束 sed -n '/regexp/,$p' # 显示部分文本——指定行号范围(从第8至第12行,含8和12行) sed -n '8,12p' # 方法1 sed '8,12!d' # 方法2 # 显示第52行 sed -n '52p' # 方法1 sed '52!d' # 方法2 sed '52q;d' # 方法3, 处理大文件时更有效率 # 从第3行开始,每7行显示一次
gsed -n '3~7p' # 只对GNU sed有效 sed -n '3,${p;n;n;n;n;n;n;}' # 其他sed # 显示两个正则表达式之间的文本(包含) sed -n '/Iowa/,/Montana/p' # 区分大小写方式 更多复杂组合用法: # 以79个字符为宽度,将所有文本右对齐 sed -e :a -e 's/^.\{1,78\}$/ &/;ta' # 78个字符外加最后的一个空格 * # 以79个字符为宽度,使所有文本居中。在方法1中,为了让文本居中每一行的前 # 头和后头都填充了空格。
在方法2中,在居中文本的过程中只在文本的前面填充 # 空格,并且最终这些空格将有一半会被删除。此外每一行的后头并未填充空格。 sed -e :a -e 's/^.\{1,77\}$/ & /;ta' # 方法1 sed -e :a -e 's/^.\{1,77\}$/ &/;ta' -e 's/
\1/\1/'
# 方法2 * # 倒置所有行,第一行成为最后一行,依次类推(模拟“tac”)。 # 由于某些原因,使用下面命令时HHsed v1.5会将文件中的空行删除 sed '1!G;h;$!d' # 方法1 sed -n '1!G;h;$p' # 方法2 * # 将行中的字符逆序排列,第一个字成为最后一字,……(模拟“rev”) sed '/\n/!G;s/
Undefined
control sequence \n /&\2\1/;//D;s/.//'
* sed '$!N;s/\n/ /'# 将每两行连接成一行(类似“paste”) * #如果当前行以反斜杠“\”结束,则将下一行并到当前行末尾并去掉原来行尾的反斜杠 sed -e :a -e '/\\$/N; s/\\\n//; ta' * # 如果当前行以等号开头,将当前行并到上一行末尾并以单个空格代替原来行头的“=” sed -e :a -e '$!N;s/\n=/ /;ta' -e 'P;D' * # 为数字字串增加逗号分隔符号,将“1234567”改为“1,234,567” gsed ':a;s/\B[0-9]\{3\}\>/,&/;ta'
# GNU sed
sed -e :a -e 's/






/\1,\2/;ta'
# 其他sed
*
# 为带有小数点和负号的数值增加逗号分隔符(GNU sed)
gsed -r ':a;s/(^|[^0-9.])([0-9]+)([0-9]{3})/\1\2,\3/g;ta'
*
特殊应用:
--------
# 移除手册页(man page)中的nroff标记。在Unix System V或bash shell下使
# 用'echo'命令时可能需要加上 -e 选项。
sed "s/.`echo \\\b`//g" # 外层的双括号是必须的(Unix环境)
sed 's/.^H//g' # 在bash或tcsh中, 按 Ctrl-V 再按 Ctrl-H
sed 's/.\x08//g' # sed 1.5,GNU sed,ssed所使用的十六进制的表示方法
# 提取新闻组或 e-mail 的邮件头
sed '/^$/q' # 删除第一行空行后的所有内容
# 提取新闻组或 e-mail 的正文部分
sed '1,/^$/d' # 删除第一行空行之前的所有内容
# 从邮件头提取“Subject”(标题栏字段),并移除开头的“Subject:”字样
sed '/^Subject: */!d; s///;q'
# 从邮件头获得回复地址
sed '/^Reply-To:/q; /^From:/h; /./d;g;q'
# 获取邮件地址。在上一个脚本所产生的那一行邮件头的基础上进一步的将非电邮
# 地址的部分剃除。(见上一脚本)
sed 's/ *(.*)//; s/>.*//; s/.*[:<] *//' # 在每一行开头加上一个尖括号和空格(引用信息) sed 's/^/> /'
# 将每一行开头处的尖括号和空格删除(解除引用)
sed 's/^> //'
# 移除大部分的HTML标签(包括跨行标签)
sed -e :a -e 's/<[^>]*>//g;/zipup.bat
dir /b *.txt | sed "s/^
\.TXT/pkzip
-mo \1 \1.TXT/" >>zipup.bat
7. 脚本
Sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
8. 小技巧
在sed的命令行中引用shell变量时要使用双引号,而不是通常所用的单引号。下面是一个根据name变量的内容来删除named.conf文件中zone段的脚本:name=’zone\ “localhost”‘
sed “/$name/,/};/d” named.conf
9. 速度优化:当由于某种原因(比如输入文件较大、处理器或硬盘较慢等)需要提高
命令执行速度时,可以考虑在替换命令(“s/.../.../”)前面加上地址表达式来
提高速度。举例来说:
sed 's/foo/bar/g' filename # 标准替换命令
sed '/foo/ s/foo/bar/g' filename # 速度更快
sed '/foo/ s//bar/g' filename # 简写形式
当只需要显示文件的前面的部分或需要删除后面的内容时,可以在脚本中使用“q”
命令(退出命令)。在处理大的文件时,这会节省大量时间。因此:
sed -n '45,50p' filename # 显示第45到50行
sed -n '51q;45,50p' filename # 一样,但快得多
http://blog.pureisle.net/archives/1348.html
ps:我只能说别说你会sed。。。这篇综合很多sed文档写成。
1. 功能说明:利用script来处理文本文件。
语 法:sed [-hnV][-e(script)][-f (script文件) ][文本文件]
补充说明:sed可依照script的指令,来处理、编辑文本文件。
2. 定址
可以通过定址来定位你所希望编辑的行,该地址用数字构成,用逗号分隔的两个行数表示以这两行为起止的行的范围(包括行数表示的那两行)。如1,3表示1,2,3行,美元符号($)表示最后一行。范围可以通过数据,正则表达式或者二者结合的方式确定 。
3. sed命令(并非参数)
调用sed命令有两种形式:
sed [options] ‘command’ file(s)
sed [options] -f scriptfile file(s)
a\ 在当前行后面加入一行文本。
b lable 分支到脚本中带有标记的地方,如果分支不存在则分支到脚本的末尾。
c\ 用新的文本改变本行的文本。
d 从模板块(Pattern space)位置删除行。
D 删除模板块的第一行。
i\ 在当前行上面插入文本。
h 拷贝模板块的内容到内存中的缓冲区。
H 追加模板块的内容到内存中的缓冲区
g 获得内存缓冲区的内容,并替代当前模板块中的文本。
G 获得内存缓冲区的内容,并追加到当前模板块文本的后面。
l 列表不能打印字符的清单。
n 读取下一个输入行,用下一个命令处理新的行而不是用第一个命令。
N 追加下一个输入行到模板块后面并在二者间嵌入一个新行,改变当前行号码。
p 打印模板块的行。
P(大写)打印模板块的第一行。
q 退出Sed。
r file 从file中读行。
t label if分支,从最后一行开始,条件一旦满足或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
T label 错误分支,从最后一行开始,一旦发生错误或者T,t命令,将导致分支到带有标号的命令处,或者到脚本的末尾。
w file 写并追加模板块到file末尾。
W file 写并追加模板块的第一行到file末尾。
! 表示后面的命令对所有没有被选定的行发生作用。
s/rep/string/ 用string替换正则表达式re匹配的内容。
= 打印当前行号码。
# 把注释扩展到下一个换行符以前。
以下的是替换标记:
g表示行内全面替换。
p表示打印行。
w表示把行写入一个文件。
x表示互换模板块中的文本和缓冲区中的文本。
y表示把一个字符翻译为另外的字符(但是不用于正则表达式)
4. 选项
-e command, –expression=command 允许多台编辑。
-h, –help 打印帮助,并显示bug列表的地址。
-n, –quiet, –silent 取消默认输出。
-f, –filer=script-file 引导sed脚本文件名。
-V, –version 打印版本和版权信息。
5. 元字符集(熟悉正则就清楚多了)
^ 锚定行的开始 如:/^sed/匹配所有以sed开头的行。
$ 锚定行的结束 如:/sed$/匹配所有以sed结尾的行。
. 匹配一个非换行符的字符 如:/s.d/匹配s后接一个任意字符,然后是d。
* 匹配零或多个字符 如:/*sed/匹配所有模板是一个或多个空格后紧跟sed的行。
[] 匹配一个指定范围内的字符,如/[Ss]ed/匹配sed和Sed。
[^] 匹配一个不在指定范围内的字符,如:/[^A-RT-Z]ed/匹配不包含A-R和T-Z的一个字母开头,紧跟ed的行。
保存匹配的字符,如s/
able/\1rs,loveable被替换成lovers。
& 保存搜索字符用来替换其他字符,如s/love/**&**/,love这成**love**。
\< 锚定单词的开始,如:/\ 锚定单词的结束,如/love\>/匹配包含以love结尾的单词的行。
x\{m\} 重复字符x,m次,如:/0\{5\}/匹配包含5个o的行。
x\{m,\} 重复字符x,至少m次,如:/o\{5,\}/匹配至少有5个o的行。
x\{m,n\} 重复字符x,至少m次,不多于n次,如:/o\{5,10\}/匹配5–10个o的行。
6. 实例
删除:d命令
$ sed '2d' #删除文件的第二行。
$ sed '2,$d' #删除文件的第二行到末尾所有行。
$ sed '$d’ #删除文件的最后一行。
$ sed 'N;$!P;$!D;$d' # 删除文件中的最后两行
# 删除文件中的最后10行
$ sed -e :a -e '$d;N;2,10ba' -e 'P;D' # 方法1
$ sed -n -e :a -e '1,10!{P;N;D;};N;ba' # 方法2
# 删除8的倍数行
$ gsed '0~8d' # 只对GNU sed有效
$ sed 'n;n;n;n;n;n;n;d;' # 其他sed
# 删除文件中的所有空行(与“grep '.' ”效果相同)
$ sed '/^$/d' # 方法1
$ sed '/./!d' # 方法2
# 只保留多个相邻空行的第一行并且删除文件顶部和尾部的空行。模拟“cat -s”
$ sed '/./,/^$/!d' #方法1,删除文件顶部的空行,允许尾部保留一空行
$ sed '/^$/N;/\n$/D' #方法2,允许顶部保留一空行,尾部不留空行
$ sed '/^$/N;/\n$/N;//D'# 只保留多个相邻空行的前两行。
$ sed '/./,$!d'# 删除文件顶部的所有空行
# 删除文件尾部的所有空行
$ sed -e :a -e '/^\n*$/{$d;N;ba' -e '}' # 对所有sed有效
$ sed -e :a -e '/^\n*$/N;/\n$/ba' # 同上,但只对 gsed 3.02.*有效
$ sed 's/^[ \t]*//;s/[ \t]*$//'#将每一行中的前导和拖尾的空白字符删除
$ sed '/test/d' #删除文件所有包含test的行。
$ sed '/test/!d' #删除文件未包含test的行。
$ sed -n '/^$/{p;h;};/./{x;/./p;}'# 删除每个段落的最后一行
$ sed '/Iowa/,/Montana/d'# 删除两个正则表达式之间的内容
# 删除文件中相邻的重复行(模拟“uniq”)只保留重复行中的第一行,其他行删除
$ sed '$!N; /^
\n\1$/!P;
D'
#删除文件中的重复行,不管有无相邻。注意hold space所能支持的缓存大小,或者使用GNU sed。
$ sed -n 'G; s/\n/&&/; /^ Undefined
control sequence \n .*\n\1/d;
s/\n//; h; P'
$ sed '$!N; s/^
\n\1$/\1/;
t; D' # 删除除重复行外的所有行(模拟“uniq -d”)
替换:s命令
$ sed ‘s/test/mytest/g’ example—–在整行范围内把test替换为mytest。如果没有g标记,则只有每行第一个匹配的test被替换成mytest。
*
$ sed 's/foo/bar/4' # 只替换每一行中的第四个“foo”字串
*
$ sed 's/
foo
/\1bar\2/'
# 替换倒数第二个“foo”
*
$ sed -n ‘s/^test/mytest/p’ example—–(-n)选项和p标志一起使用表示只打印那些发生替换的行。也就是说,如果某一行开头的test被替换成mytest,就打印它。
*
$ sed '/baz/s/foo/bar/g'# 只在行中出现字串“baz”的情况下将“foo”替换成“bar”
*
$ sed '/baz/!s/foo/bar/g'# 将“foo”替换成“bar”,并且只在行中未出现字串“baz”的情况下替换
*
# 不管是“scarlet”“ruby”还是“puce”,一律换成“red”
$ sed 's/scarlet/red/g;s/ruby/red/g;s/puce/red/g' #对多数的sed都有效
$ gsed 's/scarlet\|ruby\|puce/red/g' # 只对GNU sed有效
*
$ sed ‘s/^192.168.0.1/&localhost/’ example—–&符号表示替换换字符串中被找到的部份。所有以192.168.0.1开头的行都会被替换成它自已加 localhost,变成192.168.0.1localhost。
*
$ sed -n ‘s/
able/\1rs/p’
example—–love被标记为1,所有loveable会被替换成lovers,而且替换的行会被打印出来。
*
$ sed 's/^M$//' # 在bash/tcsh中,将按Ctrl-M改为按Ctrl-V。Unix环境:转换DOS的新行符(CR/LF)为Unix格式
*
$ sed ‘s#10#100#g’ example—–不论什么字符,紧跟着s命令的都被认为是新的分隔符,所以,“#”在这里是分隔符,代替了默认的“/”分隔符。表示把所有10替换成100。
选定行的范围:逗号
*
$ sed -n ‘/test/,/check/p’ example—–所有在模板test和check所确定的范围内的行都被打印。
*
$ sed -n ’5,/^test/p’ example—–打印从第五行开始到第一个包含以test开始的行之间的所有行。
*
$ sed ‘/test/,/check/s/$/sed test/’ example—–对于模板test和check之间的行,每行的末尾用字符串sed test替换。$变成^当然就是行头了。
多点编辑:e命令
*
$ sed -e ’1,5d’ -e ‘s/test/check/’ example—–(-e)选项允许在同一行里执行多条命令。如例子所示,第一条命令删除1至5行,第二条命令用check替换test。命令的执 行顺序对结果有影响。如果两个命令都是替换命令,那么第一个替换命令将影响第二个替换命令的结果。
*
$ sed –expression=’s/test/check/’ –expression=’/love/d’ example—–一个比-e更好的命令是–expression。它能给sed表达式赋值。
从文件读入:r命令
*
$ sed ‘/test/r file’ example—–file里的内容被读进来,显示在与test匹配的行后面,如果匹配多行,则file的内容将显示在所有匹配行的下面。
写入文件:w命令
*
$ sed -n ‘/test/w file’ example—–在example中所有包含test的行都被写入file里。
追加命令:a命令
*
$ sed ‘/^test/a\\—>this is a example’ example<—–’this is a example’被追加到以test开头的行后面,sed要求命令a后面有一个反斜杠。 * 追加命令:G命令 获得内存缓冲区的内容,并追加到当前模板块文本的后面。 sed G # 在每一行后面增加一空行 # 将原来的所有空行删除并在每一行后面增加一空行。 sed '/^$/d;G' # 这样在输出的文本中每一行后面将有且只有一空行。 sed 'G;G' # 在每一行后面增加两行空行 sed '/regex/G'
# 在匹配式样“regex”的行之后插入一空行 sed '/regex/{x;p;x;}'# 在匹配式样“regex”的行之前插入一空行 sed '/regex/{x;p;x;G;}'# 在匹配式样“regex”的行之前和之后各插入一空行 # 在每5行后增加一空白行 (在第5,10,15,20,等行后增加一空白行) gsed '0~5G' # 只对GNU sed有效 sed 'n;n;n;n;G;' # 其他sed 插入:i命令 $ sed ‘/test/i\\ new line ————————-’ example
如果test被匹配,则把反斜杠后面的文本插入到匹配行的前面。 下一个:n命令 * $ sed ‘/test/{ n; s/aa/bb/; }’ example—–如果test被匹配,则移动到匹配行的下一行,替换这一行的aa,变为bb,并打印该行,然后继续。 变形:y命令 * $ sed ’1,10y/abcde/ABCDE/’ example—–把1–10行内所有abcde转变为大写,注意,正则表达式元字符不能使用这个命令。 退出:q命令 * $ sed ’10q’ example—–打印完第10行后,退出sed。
* sed -e :a -e '$q;N;11,$D;ba'# 显示文件中的最后10行 (模拟“tail”) 保持和获取:h命令和G命令 $ sed -e ‘/test/h’ -e ‘$G example—–在sed处理文件的时候,每一行都被保存在一个叫模式空间的临时缓冲区中,除非行被删除或者输出被取消,否则所有被处理的行都将 打印在屏幕上。接着模式空间被清空,并存入新的一行等待处理。在这个例子里,匹配test的行被找到后,将存入模式空间,h命令将其复制并存入一个称为保 持缓存区的特殊缓冲区内。第二条语句的意思是,当到达最后一行后,G命令取出保持缓冲区的行,然后把它放回模式空间中,且追加到现在已经存在于模式空间中
的行的末尾。在这个例子中就是追加到最后一行。简单来说,任何包含test的行都被复制并追加到该文件的末尾。 保持和互换:h命令和x命令 * $ sed -e ‘/test/h’ -e ‘/check/x’ example —–互换模式空间和保持缓冲区的内容。也就是把包含test与check的行互换。 编号: # 为文件中的每一行进行编号(简单的左对齐方式)。这里使用了“制表符” # (tab,见本文末尾关于'\t'的用法的描述)而不是空格来对齐边缘。 sed = filename | sed 'N;s/\n/\t/'
* # 对文件中的所有行编号(行号在左,文字右端对齐)。 sed = filename | sed 'N; s/^/ /; s/ *
\n/\1
/' * # 对文件中的所有行编号,但只显示非空白行的行号。 sed '/./=' filename | sed '/./N; s/\n/ /' * # 计算行数 (模拟 "wc -l") sed -n '$=' 显示特定行: # 显示文件中的前10行 (模拟“head”的行为) sed 10q # 显示文件中的第一行 (模拟“head -1”命令) sed q # 显示文件中的最后10行 (模拟“tail”) sed -e :a -e '$q;N;11,$D;ba' # 显示文件中的最后2行(模拟“tail
-2”命令) sed '$!N;$!D' # 显示文件中的最后一行(模拟“tail -1”) sed '$!d' # 方法1 sed -n '$p' # 方法2 # 显示文件中的倒数第二行 sed -e '$!{h;d;}' -e x # 当文件中只有一行时,输入空行 sed -e '1{$q;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,显示该行 sed -e '1{$d;}' -e '$!{h;d;}' -e x # 当文件中只有一行时,不输出 # 只显示匹配正则表达式的行(模拟“grep”)
sed -n '/regexp/p' # 方法1 sed '/regexp/!d' # 方法2 # 只显示“不”匹配正则表达式的行(模拟“grep -v”) sed -n '/regexp/!p' # 方法1,与前面的命令相对应 sed '/regexp/d' # 方法2,类似的语法 # 查找“regexp”并将匹配行的上一行显示出来,但并不显示匹配行 sed -n '/regexp/{g;1!p;};h' # 查找“regexp”并将匹配行的下一行显示出来,但并不显示匹配行 sed -n '/regexp/{n;p;}'
# 显示包含“regexp”的行及其前后行,并在第一行之前加上“regexp”所 # 在行的行号 (类似“grep -A1 -B1”) sed -n -e '/regexp/{=;x;1!p;g;$!N;p;D;}' -e h # 显示包含“AAA”、“BBB”或“CCC”的行(任意次序) sed '/AAA/!d; /BBB/!d; /CCC/!d' # 字串的次序不影响结果 # 显示包含“AAA”、“BBB”和“CCC”的行(固定次序) sed '/AAA.*BBB.*CCC/!d' # 显示包含“AAA”“BBB”或“CCC”的行
(模拟“egrep”) sed -e '/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d # 多数sed gsed '/AAA\|BBB\|CCC/!d' # 对GNU sed有效 # 显示包含“AAA”的段落 (段落间以空行分隔) # HHsed v1.5 必须在“x;”后加入“G;”,接下来的3个脚本都是这样 sed -e '/./{H;$!d;}' -e 'x;/AAA/!d;' # 显示包含“AAA”“BBB”和“CCC”三个字串的段落 (任意次序) sed -e '/./{H;$!d;}'
-e 'x;/AAA/!d;/BBB/!d;/CCC/!d' # 显示包含“AAA”、“BBB”、“CCC”三者中任一字串的段落 (任意次序) sed -e '/./{H;$!d;}' -e 'x;/AAA/b' -e '/BBB/b' -e '/CCC/b' -e d gsed '/./{H;$!d;};x;/AAA\|BBB\|CCC/b;d' # 只对GNU sed有效 # 显示包含65个或以上字符的行 sed -n '/^.\{65\}/p' # 显示包含65个以下字符的行 sed -n '/^.\{65\}/!p'
# 方法1,与上面的脚本相对应 sed '/^.\{65\}/d' # 方法2,更简便一点的方法 # 显示部分文本——从包含正则表达式的行开始到最后一行结束 sed -n '/regexp/,$p' # 显示部分文本——指定行号范围(从第8至第12行,含8和12行) sed -n '8,12p' # 方法1 sed '8,12!d' # 方法2 # 显示第52行 sed -n '52p' # 方法1 sed '52!d' # 方法2 sed '52q;d' # 方法3, 处理大文件时更有效率 # 从第3行开始,每7行显示一次
gsed -n '3~7p' # 只对GNU sed有效 sed -n '3,${p;n;n;n;n;n;n;}' # 其他sed # 显示两个正则表达式之间的文本(包含) sed -n '/Iowa/,/Montana/p' # 区分大小写方式 更多复杂组合用法: # 以79个字符为宽度,将所有文本右对齐 sed -e :a -e 's/^.\{1,78\}$/ &/;ta' # 78个字符外加最后的一个空格 * # 以79个字符为宽度,使所有文本居中。在方法1中,为了让文本居中每一行的前 # 头和后头都填充了空格。
在方法2中,在居中文本的过程中只在文本的前面填充 # 空格,并且最终这些空格将有一半会被删除。此外每一行的后头并未填充空格。 sed -e :a -e 's/^.\{1,77\}$/ & /;ta' # 方法1 sed -e :a -e 's/^.\{1,77\}$/ &/;ta' -e 's/
\1/\1/'
# 方法2 * # 倒置所有行,第一行成为最后一行,依次类推(模拟“tac”)。 # 由于某些原因,使用下面命令时HHsed v1.5会将文件中的空行删除 sed '1!G;h;$!d' # 方法1 sed -n '1!G;h;$p' # 方法2 * # 将行中的字符逆序排列,第一个字成为最后一字,……(模拟“rev”) sed '/\n/!G;s/
Undefined
control sequence \n /&\2\1/;//D;s/.//'
* sed '$!N;s/\n/ /'# 将每两行连接成一行(类似“paste”) * #如果当前行以反斜杠“\”结束,则将下一行并到当前行末尾并去掉原来行尾的反斜杠 sed -e :a -e '/\\$/N; s/\\\n//; ta' * # 如果当前行以等号开头,将当前行并到上一行末尾并以单个空格代替原来行头的“=” sed -e :a -e '$!N;s/\n=/ /;ta' -e 'P;D' * # 为数字字串增加逗号分隔符号,将“1234567”改为“1,234,567” gsed ':a;s/\B[0-9]\{3\}\>/,&/;ta'
# GNU sed
sed -e :a -e 's/
/\1,\2/;ta'
# 其他sed
*
# 为带有小数点和负号的数值增加逗号分隔符(GNU sed)
gsed -r ':a;s/(^|[^0-9.])([0-9]+)([0-9]{3})/\1\2,\3/g;ta'
*
特殊应用:
--------
# 移除手册页(man page)中的nroff标记。在Unix System V或bash shell下使
# 用'echo'命令时可能需要加上 -e 选项。
sed "s/.`echo \\\b`//g" # 外层的双括号是必须的(Unix环境)
sed 's/.^H//g' # 在bash或tcsh中, 按 Ctrl-V 再按 Ctrl-H
sed 's/.\x08//g' # sed 1.5,GNU sed,ssed所使用的十六进制的表示方法
# 提取新闻组或 e-mail 的邮件头
sed '/^$/q' # 删除第一行空行后的所有内容
# 提取新闻组或 e-mail 的正文部分
sed '1,/^$/d' # 删除第一行空行之前的所有内容
# 从邮件头提取“Subject”(标题栏字段),并移除开头的“Subject:”字样
sed '/^Subject: */!d; s///;q'
# 从邮件头获得回复地址
sed '/^Reply-To:/q; /^From:/h; /./d;g;q'
# 获取邮件地址。在上一个脚本所产生的那一行邮件头的基础上进一步的将非电邮
# 地址的部分剃除。(见上一脚本)
sed 's/ *(.*)//; s/>.*//; s/.*[:<] *//' # 在每一行开头加上一个尖括号和空格(引用信息) sed 's/^/> /'
# 将每一行开头处的尖括号和空格删除(解除引用)
sed 's/^> //'
# 移除大部分的HTML标签(包括跨行标签)
sed -e :a -e 's/<[^>]*>//g;/zipup.bat
dir /b *.txt | sed "s/^
\.TXT/pkzip
-mo \1 \1.TXT/" >>zipup.bat
7. 脚本
Sed脚本是一个sed的命令清单,启动Sed时以-f选项引导脚本文件名。Sed对于脚本中输入的命令非常挑剔,在命令的末尾不能有任何空白或文本,如果在一行中有多个命令,要用分号分隔。以#开头的行为注释行,且不能跨行。
8. 小技巧
在sed的命令行中引用shell变量时要使用双引号,而不是通常所用的单引号。下面是一个根据name变量的内容来删除named.conf文件中zone段的脚本:name=’zone\ “localhost”‘
sed “/$name/,/};/d” named.conf
9. 速度优化:当由于某种原因(比如输入文件较大、处理器或硬盘较慢等)需要提高
命令执行速度时,可以考虑在替换命令(“s/.../.../”)前面加上地址表达式来
提高速度。举例来说:
sed 's/foo/bar/g' filename # 标准替换命令
sed '/foo/ s/foo/bar/g' filename # 速度更快
sed '/foo/ s//bar/g' filename # 简写形式
当只需要显示文件的前面的部分或需要删除后面的内容时,可以在脚本中使用“q”
命令(退出命令)。在处理大的文件时,这会节省大量时间。因此:
sed -n '45,50p' filename # 显示第45到50行
sed -n '51q;45,50p' filename # 一样,但快得多

相关文章推荐
- linux/unix命令详解之sed
- Linux/Unix环境下的make命令详解
- Linux/Unix环境下的make命令详解
- Linux/Unix环境下的make命令详解
- Linux awk命令详解 sed
- Linux下grep命令的详解,cut,sed
- Linux/UNIX的scp命令用法详解
- linux/unix系统中ldconfig命令使用详解
- Linux/UNIX的scp命令用法详解
- [Linux] sed命令详解
- Linux/Unix环境下的make命令详解
- Linux/Unix环境下的make命令详解
- Linux/Unix环境下的make命令详解
- linux sed命令详解
- linux下的sed命令详解
- Linux/Unix环境下的make命令详解
- nc命令详解 转 http://linux.chinaunix.net/techdoc/system/2008/10/14/1038114.shtml
- 超级实用的 Linux/Unix FTP 下载上传文件命令详解
- linux sed 命令参数及用法详解
- Linux/Unix环境下的make命令详解