基于深度学习的目标检测方法:fast R-CNN
2017-05-19 10:55
411 查看
fast R-CNN
论文:fast R-CNN
R-CNN存在的缺点:
1、R-CNN是multi-stage pipeline。首先利用CNN提取特征,然后利用SVM进行分类,最后利用bounding-box regressors 修正目标框。
2、训练的时间开销、空间开销比较大。用于SVM、bounding-box regressors的特征需要存储到磁盘中,这将需要占用大量的磁盘空间,而且提取这些特征也会耗费好多时间。
3、测试的时间开销比较大。提取每张图像的每个region proposal的特征,这将浪费很多时间。关于这个问题,SPP-net提出了解决方法,也就是先提取整张图像的特征图,然后从该特征图中提取各个region
proposal的特征。
SPP-net存在的缺点:
1、SPP-net也是multi-stage pipeline
2、SPP-net也需要将特征写入到磁盘中
3、SPP-net不能微调spatial pyramid pooling layer之前的convolutional layers,这将影响深层网络模型的准确度。
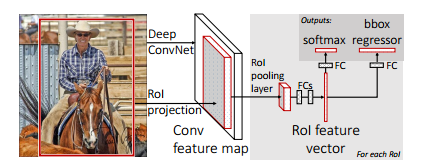
针对R-CNN、SPP-net存在的缺点,该论文提出了 fast R-CNN,其结构如下图所示。在 fast R-CNN中,1、将最后一个池化层替换为RoI
pooling layer; 2、最后一个全连接层与softmax替换为两个兄弟层,一个是全连接层+softmax,另一个是全连接层+bbox regressor;3、模型的输入为一系列图像以及这些图像的RoIs 。
------------------------------------------------------------------------------------------------------------------------------------------------------
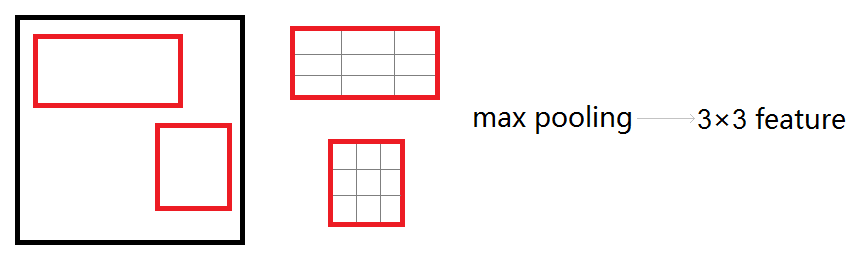
RoI pooling layer
该层有两个作用:1、将图像的RoI定位到feature map中对应位置,采用SPP-net中的定位方法; 2、对该RoI对应的特征进行max pooling, 也就是把每个候选区域均匀分成M×N块,对每块进行max
pooling,将特征图上大小不一的候选区域转变为大小统一的数据,再传入到全连接层,这个过程本质上是单层的SPP layer,如下图:
该层的反向传播过程:
首先考虑普通max pooling层。设xi为输入层的节点,yj为输出层的节点,则有:
∂L∂xi={0∂L∂yjδ(i,j)=falseδ(i,j)=true
其中判决函数δ(i,j)表示i节点是否被j节点选为最大值输出。不被选中有两种可能:xi不在yj范围内,或者xi不是最大值。
然而,对于roi max pooling,一个输入节点可能和多个输出节点相连。设xi为输入层的节点,yrj为第r个候选区域的第j个输出节点。
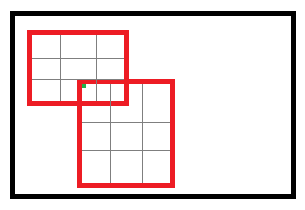
∂L∂xi=Σr,jδ(i,r,j)∂L∂yrj
其中,判决函数δ(i,r,j)表示i节点是否被候选区域r的第j个节点选为最大值输出;代价关于xi的梯度等于所有相关的后一层的梯度之和。
------------------------------------------------------------------------------------------------------------------------------------------------------
multi-task loss
Each training RoI is labeled
with a ground-truth class u and
a ground-truth bounding-box regression target v.
对于分类loss, softmax层输出K+1维的数组,表示属于K类和背景的概率。分类loss由真实类别u所对应的概率决定,也就是:Lcls=−logpu
对于回归loss,bbox regressors层输出K个regression offsets(tx,
ty, tw, th) ,
也就是为每一个类别都会训练一个单独的regressor。回归loss也是
由真实类别u所对应的预测参数(tx, ty, tw, th)决定的,这里采用的是smooth
L1误差,即:
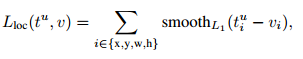
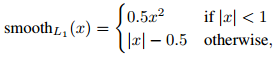
总的loss计算如下,如果分类为背景,不需要计算回归loss。
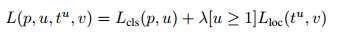
------------------------------------------------------------------------------------------------------------------------------------------------------
分层数据
在调优训练时,每一个mini-batch中,首先加入N张完整图片,然后加入从这N张图片中选取的R个候选框,也就是从每张图片中选取R/N个候选框。
实际选择N=2, R=128
------------------------------------------------------------------------------------------------------------------------------------------------------
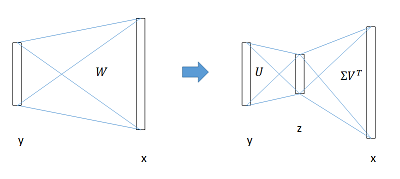
全连接层加速
全连接层的计算比较耗时,全连接层参数为W,尺寸为u×v,计算复杂度为u
* v, 该论文中提出了利用Truncated SVD来加速计算,即:
W=UΣVT≈U(:,1:t)⋅Σ(1:t,1:t)⋅V(:,1:t)T
原来的前向传播分解成两步,计算复杂度变为u×t+v×t:
y=Wx=U⋅(Σ⋅VT)⋅x=U⋅z
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。
论文:fast R-CNN
R-CNN存在的缺点:
1、R-CNN是multi-stage pipeline。首先利用CNN提取特征,然后利用SVM进行分类,最后利用bounding-box regressors 修正目标框。
2、训练的时间开销、空间开销比较大。用于SVM、bounding-box regressors的特征需要存储到磁盘中,这将需要占用大量的磁盘空间,而且提取这些特征也会耗费好多时间。
3、测试的时间开销比较大。提取每张图像的每个region proposal的特征,这将浪费很多时间。关于这个问题,SPP-net提出了解决方法,也就是先提取整张图像的特征图,然后从该特征图中提取各个region
proposal的特征。
SPP-net存在的缺点:
1、SPP-net也是multi-stage pipeline
2、SPP-net也需要将特征写入到磁盘中
3、SPP-net不能微调spatial pyramid pooling layer之前的convolutional layers,这将影响深层网络模型的准确度。
针对R-CNN、SPP-net存在的缺点,该论文提出了 fast R-CNN,其结构如下图所示。在 fast R-CNN中,1、将最后一个池化层替换为RoI
pooling layer; 2、最后一个全连接层与softmax替换为两个兄弟层,一个是全连接层+softmax,另一个是全连接层+bbox regressor;3、模型的输入为一系列图像以及这些图像的RoIs 。
------------------------------------------------------------------------------------------------------------------------------------------------------
RoI pooling layer
该层有两个作用:1、将图像的RoI定位到feature map中对应位置,采用SPP-net中的定位方法; 2、对该RoI对应的特征进行max pooling, 也就是把每个候选区域均匀分成M×N块,对每块进行max
pooling,将特征图上大小不一的候选区域转变为大小统一的数据,再传入到全连接层,这个过程本质上是单层的SPP layer,如下图:
该层的反向传播过程:
首先考虑普通max pooling层。设xi为输入层的节点,yj为输出层的节点,则有:
∂L∂xi={0∂L∂yjδ(i,j)=falseδ(i,j)=true
其中判决函数δ(i,j)表示i节点是否被j节点选为最大值输出。不被选中有两种可能:xi不在yj范围内,或者xi不是最大值。
然而,对于roi max pooling,一个输入节点可能和多个输出节点相连。设xi为输入层的节点,yrj为第r个候选区域的第j个输出节点。
∂L∂xi=Σr,jδ(i,r,j)∂L∂yrj
其中,判决函数δ(i,r,j)表示i节点是否被候选区域r的第j个节点选为最大值输出;代价关于xi的梯度等于所有相关的后一层的梯度之和。
------------------------------------------------------------------------------------------------------------------------------------------------------
multi-task loss
Each training RoI is labeled
with a ground-truth class u and
a ground-truth bounding-box regression target v.
对于分类loss, softmax层输出K+1维的数组,表示属于K类和背景的概率。分类loss由真实类别u所对应的概率决定,也就是:Lcls=−logpu
对于回归loss,bbox regressors层输出K个regression offsets(tx,
ty, tw, th) ,
也就是为每一个类别都会训练一个单独的regressor。回归loss也是
由真实类别u所对应的预测参数(tx, ty, tw, th)决定的,这里采用的是smooth
L1误差,即:
总的loss计算如下,如果分类为背景,不需要计算回归loss。
------------------------------------------------------------------------------------------------------------------------------------------------------
分层数据
在调优训练时,每一个mini-batch中,首先加入N张完整图片,然后加入从这N张图片中选取的R个候选框,也就是从每张图片中选取R/N个候选框。
实际选择N=2, R=128
------------------------------------------------------------------------------------------------------------------------------------------------------
全连接层加速
全连接层的计算比较耗时,全连接层参数为W,尺寸为u×v,计算复杂度为u
* v, 该论文中提出了利用Truncated SVD来加速计算,即:
W=UΣVT≈U(:,1:t)⋅Σ(1:t,1:t)⋅V(:,1:t)T
原来的前向传播分解成两步,计算复杂度变为u×t+v×t:
y=Wx=U⋅(Σ⋅VT)⋅x=U⋅z
在实现时,相当于把一个全连接层拆分成两个,中间以一个低维数据相连。

相关文章推荐
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN(转)
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN【转】
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 1:基于深度学习的目标检测技术:RCNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测技术演进:R-CNN、Fast R-CNN、Faster R-CNN
- 基于深度学习的目标检测方法:R-CNN
- 基于深度学习的目标检测方法:SPP-net
- 基于深度学习的目标检测方法总结