DeepLearning4j实战(7):手写体数字识别GPU实现与性能比较
2017-05-15 21:28
435 查看
在之前的博客中已经用单机、Spark分布式两种训练的方式对深度神经网络进行训练,但其实DeepLearning4j也是支持多GPU训练的。这篇文章我就总结下用GPU来对DNN/CNN进行训练和评估过程。并且我会给出CPU、GPU和多卡GPU之前的性能比较图表。不过,由于重点在于说明Mnist数据集在GPU上训练的过程,所以对于一些环境的部署,比如Java环境和CUDA的安装就不再详细说明了。
软件环境的部署主要在于两个方面,一个是JDK的安装,另外一个是CUDA。目前最新版本的DeepLearning4j以及Nd4j支持CUDA-8.0,JDK的话1.7以上。
环境部署完后,分别用java -version和nvidia-smi来确认环境是否部署正确,如果出现类似以下的信息,则说明环境部署正确,否则需要重新安装。
GPU配置:
Java环境截图:

从系统返回的信息可以看到,jdk是openJDK1.7,GPU是2张P40的卡。
下面说明下代码的构成:
由于我这里用了DeepLearning4j最新的版本--v0.8,所以和之前博客的pom文件有些修改,具体如下:
创建完Maven工程以及添加了上面POM文件的内容之后,就可以开始着手上层应用逻辑的构建。这里我参考了官网的例子,具体由以下几个部分构成:
1.初始化CUDA的环境(底层逻辑包括硬件检测、CUDA版本校验和一些GPU参数)
2.读取Mnist二进制文件(和之前的博客内容一致)
3.CNN的定义,这里我还是用的LeNet
4.训练以及评估模型的指标
首先贴一下第一部分的代码:
再下面就是设置CUDA的一些上下文参数,比如代码中罗列的cache数据的显存大小,P2P访问内存和多GPU运行的标志位等等。对于网络结构相对简单,数据量不大的情况下,默认的参数就够用了。这里我们也只是简单设置了几个参数,这对于用LeNet来训练Mnist数据集来说已经足够了。
从2~4部分的逻辑和之前的博客里几乎是一样的,就直接上代码了:
以上逻辑就是利用一块GPU卡进行Mnist数据集进行训练和评估的逻辑。如果想在多GPU下进行并行训练的话,需要修改一些设置,例如在之前第一步的创建CUDA环境上下文的时候,需要允许多GPU和P2P内存访问,即设置为true。然后在逻辑里添加并行训练的逻辑:
这样如果有多张GPU卡就可以进行单机多卡的并行训练。
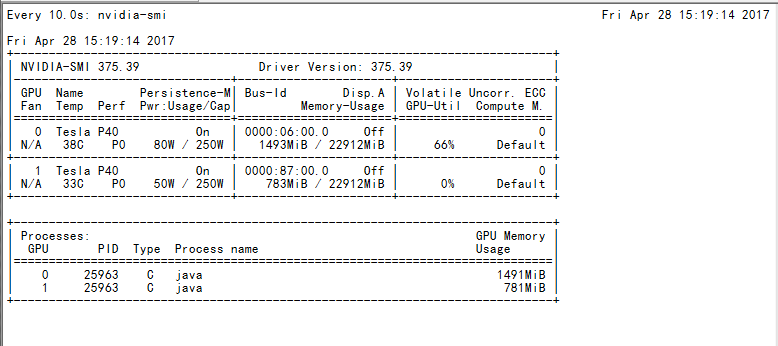
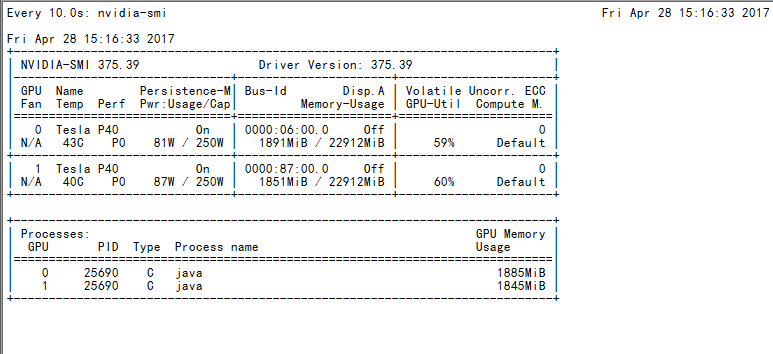
下面贴一下训练Mnist数据集在CPU/GPU/多GPU下的性能比较还有训练时候的GPU使用情况:
单卡训练截图:
双卡并行训练截图:
训练时间评估:
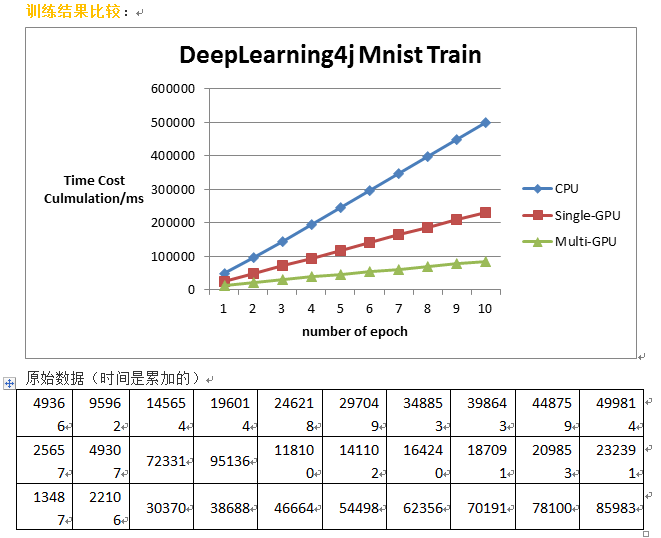
最后做下简单的总结。由于Deeplearning4j本身支持GPU单卡,多卡以及集群的训练方式,而且对于底层的接口都已经进行了很多的封装,暴露的接口都是比较hig-level的接口,一般设置一些属性就可以了。当然前提是硬件包括CUDA都要正确安装。
软件环境的部署主要在于两个方面,一个是JDK的安装,另外一个是CUDA。目前最新版本的DeepLearning4j以及Nd4j支持CUDA-8.0,JDK的话1.7以上。
环境部署完后,分别用java -version和nvidia-smi来确认环境是否部署正确,如果出现类似以下的信息,则说明环境部署正确,否则需要重新安装。
GPU配置:
Java环境截图:
从系统返回的信息可以看到,jdk是openJDK1.7,GPU是2张P40的卡。
下面说明下代码的构成:
由于我这里用了DeepLearning4j最新的版本--v0.8,所以和之前博客的pom文件有些修改,具体如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>DeepLearning</groupId> <artifactId>DeepLearning</artifactId> <version>2.0</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <nd4j.version>0.8.0</nd4j.version> <dl4j.version>0.8.0</dl4j.version> <datavec.version>0.8.0</datavec.version> <scala.binary.version>2.11</scala.binary.version> </properties> <dependencies> <dependency> <groupId>org.nd4j</groupId> <artifactId>nd4j-native</artifactId> <version>${nd4j.version}</version> </dependency> <dependency> <groupId>org.deeplearning4j</groupId> <artifactId>deeplearning4j-core</artifactId> <version>${dl4j.version}</version> </dependency> <dependency> <groupId>org.nd4j</groupId> <artifactId>nd4j-cuda-8.0</artifactId> <version>${nd4j.version}</version> </dependency> <dependency> <groupId>org.deeplearning4j</groupId> <artifactId>deeplearning4j-parallel-wrapper_${scala.binary.version}</artifactId> <version>${dl4j.version}</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>2.4</version> <configuration> <source>1.7</source> <target>1.7</target> <archive> <manifest> <mainClass>cn.live.wangongxi.cv.CNNMnist</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build> </project>
创建完Maven工程以及添加了上面POM文件的内容之后,就可以开始着手上层应用逻辑的构建。这里我参考了官网的例子,具体由以下几个部分构成:
1.初始化CUDA的环境(底层逻辑包括硬件检测、CUDA版本校验和一些GPU参数)
2.读取Mnist二进制文件(和之前的博客内容一致)
3.CNN的定义,这里我还是用的LeNet
4.训练以及评估模型的指标
首先贴一下第一部分的代码:
//精度设置,常用精度有单、双、半精度 //HALF : 半精度 DataTypeUtil.setDTypeForContext(DataBuffer.Type.HALF); //FLOAT : 单精度 //DataTypeUtil.setDTypeForContext(DataBuffer.Type.FLOAT); //DOUBLE : 双精度 //DataTypeUtil.setDTypeForContext(DataBuffer.Type.DOUBLE); //创建CUDA上下文实例并设置参数 CudaEnvironment.getInstance().getConfiguration() //是否允许多GPU .allowMultiGPU(false) //设置显存中缓存数据的容量,单位:字节 .setMaximumDeviceCache(2L * 1024L * 1024L * 1024L) //是否允许多GPU间点对点(P2P)的内存访问 .allowCrossDeviceAccess(false);通常我们需要根据需要来设置GPU计算的精度,常用的就像代码中写的那样有单、双、半精度三种。通过选择DataBuffer中定义的enum类型Type中的值来达到设置精度的目的。如果不设置,默认的是单精度。
再下面就是设置CUDA的一些上下文参数,比如代码中罗列的cache数据的显存大小,P2P访问内存和多GPU运行的标志位等等。对于网络结构相对简单,数据量不大的情况下,默认的参数就够用了。这里我们也只是简单设置了几个参数,这对于用LeNet来训练Mnist数据集来说已经足够了。
从2~4部分的逻辑和之前的博客里几乎是一样的,就直接上代码了:
int nChannels = 1;
int outputNum = 10;
int batchSize = 128;
int nEpochs = 10;
int iterations = 1;
int seed = 123;
log.info("Load data....");
DataSetIterator mnistTrain = new MnistDataSetIterator(batchSize,true,12345);
DataSetIterator mnistTest = new MnistDataSetIterator(batchSize,false,12345);
log.info("Build model....");
MultiLayerConfiguration conf = new NeuralNetConfiguration.Builder()
.seed(seed)
.iterations(iterations)
.regularization(true).l2(0.0005)
.learningRate(.01)
.weightInit(WeightInit.XAVIER)
.optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
.updater(Updater.NESTEROVS).momentum(0.9)
.list()
.layer(0, new ConvolutionLayer.Builder(5, 5)
.nIn(nChannels)
.stride(1, 1)
.nOut(20)
.activation(Activation.IDENTITY)
.build())
.layer(1, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
.layer(2, new ConvolutionLayer.Builder(5, 5)
.stride(1, 1)
.nOut(50)
.activation(Activation.IDENTITY)
.build())
.layer(3, new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2,2)
.stride(2,2)
.build())
.layer(4, new DenseLayer.Builder().activation(Activation.RELU)
.nOut(500).build())
.layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.NEGATIVELOGLIKELIHOOD)
.nOut(outputNum)
.activation(Activation.SOFTMAX)
.build())
.setInputType(InputType.convolutionalFlat(28,28,1))
.backprop(true).pretrain(false).build();
MultiLayerNetwork model = new MultiLayerNetwork(conf);
model.init();
log.info("Train model....");
model.setListeners(new ScoreIterationListener(100));
long timeX = System.currentTimeMillis();
for( int i=0; i<nEpochs; i++ ) {
long time1 = System.currentTimeMillis();
model.fit(mnistTrain);
long time2 = System.currentTimeMillis();
log.info("*** Completed epoch {}, time: {} ***", i, (time2 - time1));
}
long timeY = System.currentTimeMillis();
log.info("*** Training complete, time: {} ***", (timeY - timeX));
log.info("Evaluate model....");
Evaluation eval = new Evaluation(outputNum);
while(mnistTest.hasNext()){
DataSet ds = mnistTest.next();
INDArray output = model.output(ds.getFeatureMatrix(), false);
eval.eval(ds.getLabels(), output);
}
log.info(eval.stats());
log.info("****************Example finished********************");以上逻辑就是利用一块GPU卡进行Mnist数据集进行训练和评估的逻辑。如果想在多GPU下进行并行训练的话,需要修改一些设置,例如在之前第一步的创建CUDA环境上下文的时候,需要允许多GPU和P2P内存访问,即设置为true。然后在逻辑里添加并行训练的逻辑:
ParallelWrapper wrapper = new ParallelWrapper.Builder(model) .prefetchBuffer(24) .workers(4) .averagingFrequency(3) .reportScoreAfterAveraging(true) .useLegacyAveraging(true) .build();
这样如果有多张GPU卡就可以进行单机多卡的并行训练。
下面贴一下训练Mnist数据集在CPU/GPU/多GPU下的性能比较还有训练时候的GPU使用情况:
单卡训练截图:
双卡并行训练截图:
训练时间评估:
最后做下简单的总结。由于Deeplearning4j本身支持GPU单卡,多卡以及集群的训练方式,而且对于底层的接口都已经进行了很多的封装,暴露的接口都是比较hig-level的接口,一般设置一些属性就可以了。当然前提是硬件包括CUDA都要正确安装。

相关文章推荐
- Deeplearning4j 实战(2):Deeplearning4j 手写体数字识别Spark实现
- Deeplearning4j 实战(2):Deeplearning4j 手写体数字识别Spark实现【转】
- 深度学习Deeplearning4j 入门实战(2):Deeplearning4j 手写体数字识别Spark实现
- 深度学习Deeplearning4j入门 实战(1):Deeplearning4j 手写体数字识别
- Deeplearning4j 实战(1):Deeplearning4j 手写体数字识别【转】
- 深度学习Deeplearning4j入门 实战(1):Deeplearning4j 手写体数字识别
- python3机器学习实战 kNN实现手写体数字识别
- Deeplearning4j 实战(1):Deeplearning4j 手写体数字识别
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 用MXnet实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 《Spark商业案例与性能调优实战100课》第9课:商业案例之通过Spark SQL 下两种不同方式实现口碑最佳和最热门电影比较
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- 判断一个字符串是否全是数字的多种方法及其性能比较(C#实现)
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- C++从零实现深度神经网络之六——实战手写数字识别(sigmoid和tanh)
- 用MXnet入门实战深度学习之一:安装GPU版mxnet并跑一个MNIST手写数字识别
- Neural Network实战:Java实现Back Propagation算法 + 手写数字识别