第一个python实现的mapreduce程序
2017-05-13 21:42
375 查看
map:
reduce:
测试:
执行:可将其写入脚本文件
# !/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print ("%s\t%s") % (word, 1)reduce:
#!/usr/bin/env python
import operator
import sys
current_word = None
curent_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
curent_count += count
else:
if current_word:
print '%s\t%s' % (current_word,curent_count)
current_word=word
curent_count=count
if current_word==word:
print '%s\t%s' % (current_word,curent_count)测试:
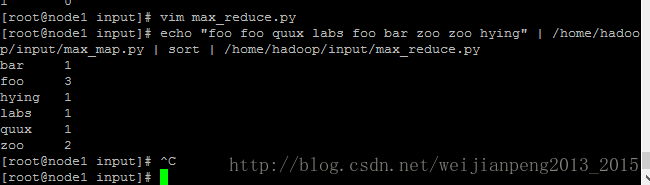
[root@node1 input]# echo "foo foo quux labs foo bar zoo zoo hying" | /home/hadoop/input/max_map.py | sort | /home/hadoop/input/max_reduce.py
执行:可将其写入脚本文件
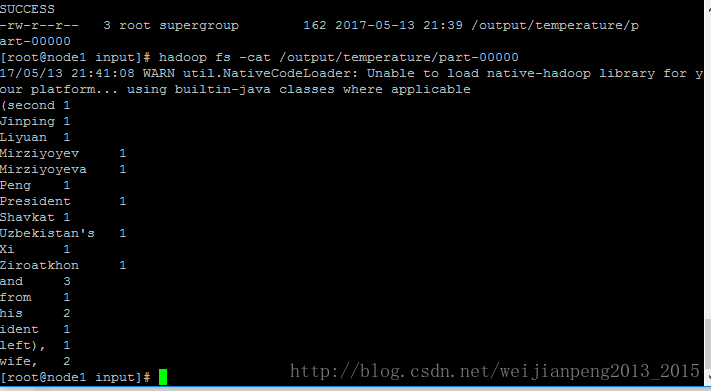
//注意\-file之间一定不能空格 hadoop jar /hadoop64/hadoop-2.7.1/share/hadoop/tools/lib/hadoop-*streaming*.jar -D stream.non.zero.exit.is.failure=false \-file /home/hadoop/input/max_map.py -mapper /home/hadoop/input/max_map.py \-file /home/hadoop/input/max_reduce.py -reducer /home/hadoop/input/max_reduce.py \-input /input/temperature/ -output /output/temperature

相关文章推荐
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序
- 一起学Hadoop——使用IDEA编写第一个MapReduce程序(Java和Python)
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序
- [python]使用python实现Hadoop MapReduce程序:计算一组数据的均值和方差
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序
- 使用Python实现Hadoop MapReduce程序遇到的问题解决办法
- Python实现mapreduce程序
- 我的第一个Python小程序
- 我的第一个struts程序(Struts1.X实现MVC框架)
- FMS3系列(一):第一个FMS程序,连接到FMS服务器(Flash/Flex两种实现)
- 第一个python程序-blog数目统计
- 第一个Python程序