Machine Learning第八讲[非监督学习] --(一)聚类
2017-05-13 20:43
232 查看
内容来自Andrew老师课程Machine Learning的第八章内容的Clustering部分。

,通过这些样本去训练模型进行预测,在这些样本中,是包含y标签的,即实际值。
在非监督学习中,我们给一系列样本数据
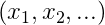
,在这些数据中,区别于监督学习最明显的特征便是没有这些实际值,我们通过聚类或者其他方式去将这些样本分类。
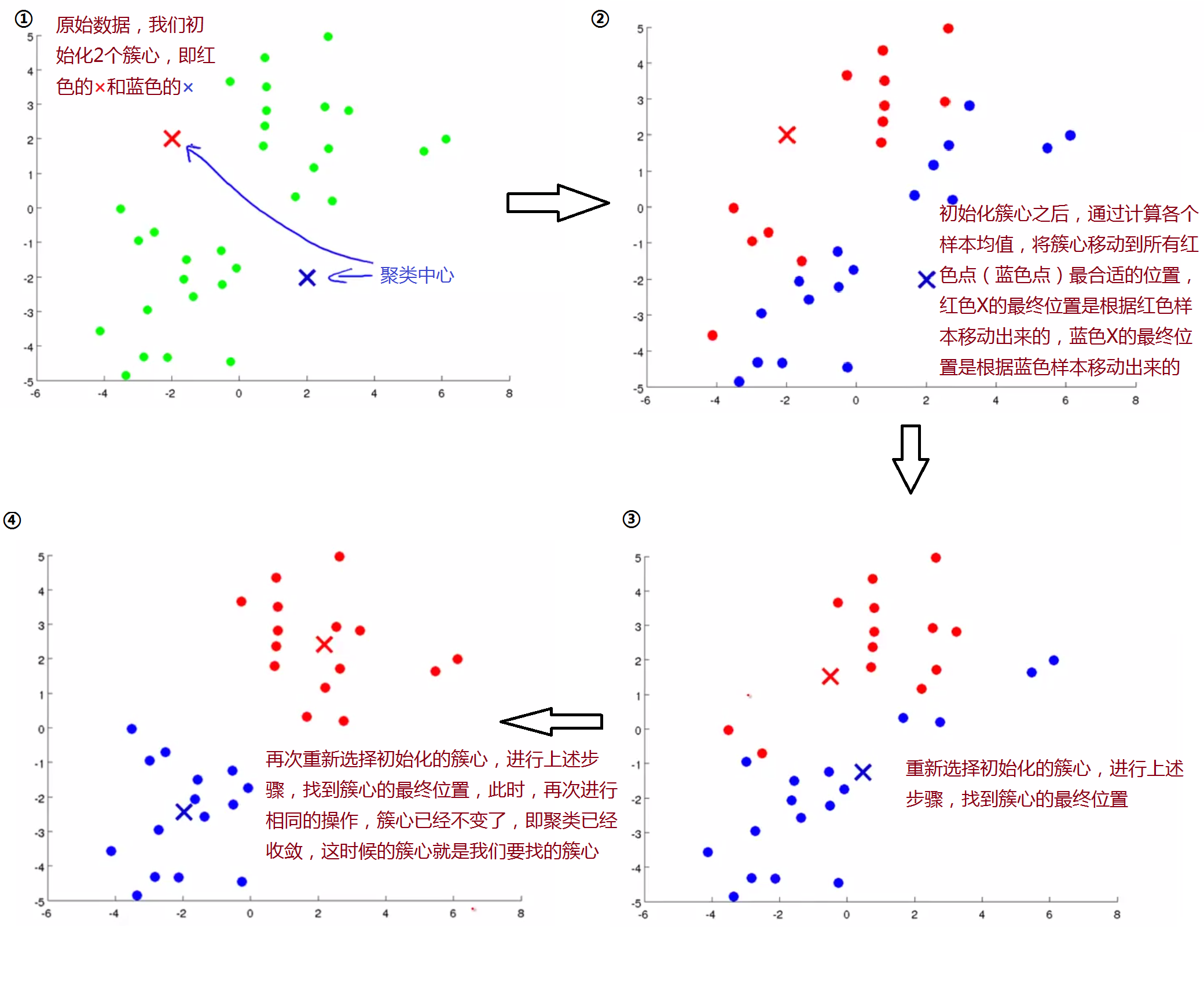
下面是K-Means算法的输入,以及具体步骤,主要分为簇心的初始化和簇心的移动。

既然我们要让簇心μ_k移动到分配给它的那些点的均值处,如果存在一个没有点可以分配给它的聚类中心,那怎么办呢?
一般情况下,我们会选择直接移除这个簇心,但是如果这样,我们将会得到K-1个簇而非K个,如果你仍需要得到K个簇,那么可以通过重新找一个簇心来使全部簇心个数为K,不过,直接移除簇心是最常见的用法。(在实际情况中,这种情况很少会发生)。
上面讲的例子,样本是分开成几部分的,那么对于没有明显分开的样本,我们可以使用K-Means进行分类吗?

即使是对于右边这种没有明显分开的例子,我们仍能够使用K-Means将其分为3类,若需要进行小、中、大号的服装设计,则可以根据这3个分类来确定具体的尺寸大小

下图讲解了K-Means过程中是怎样使优化目标函数达到最小值的。

(1)K<m
(2)随机挑选k个训练样本
(3)令μ_1,μ_2,...,μ_k等于这k个样本。
如下图,随机选择的可能结果,

在初始化的时候,有时候我们能够得到

在上图中,如果情况比较好,可能会初始化簇心,使得K-Means能够得到全局最优解。
但是在情况不好的时候,可能会出现下面两种情况,即出现局部最优解,为了避免这种情况,我们需要多次地尝试初始化。
For i = 1 to 100 {
Randomly initialize K-means.
Run K-means. Get

.
Compute cost function(distortion)

.
}
Pick clustering that gave lowest cost

.

那么我们应该如何确定K的值呢?
方法一:Elbow method(这个方法可能只能偶尔适用,有时候是不能够通过这种方法确定K的值得),如下图:
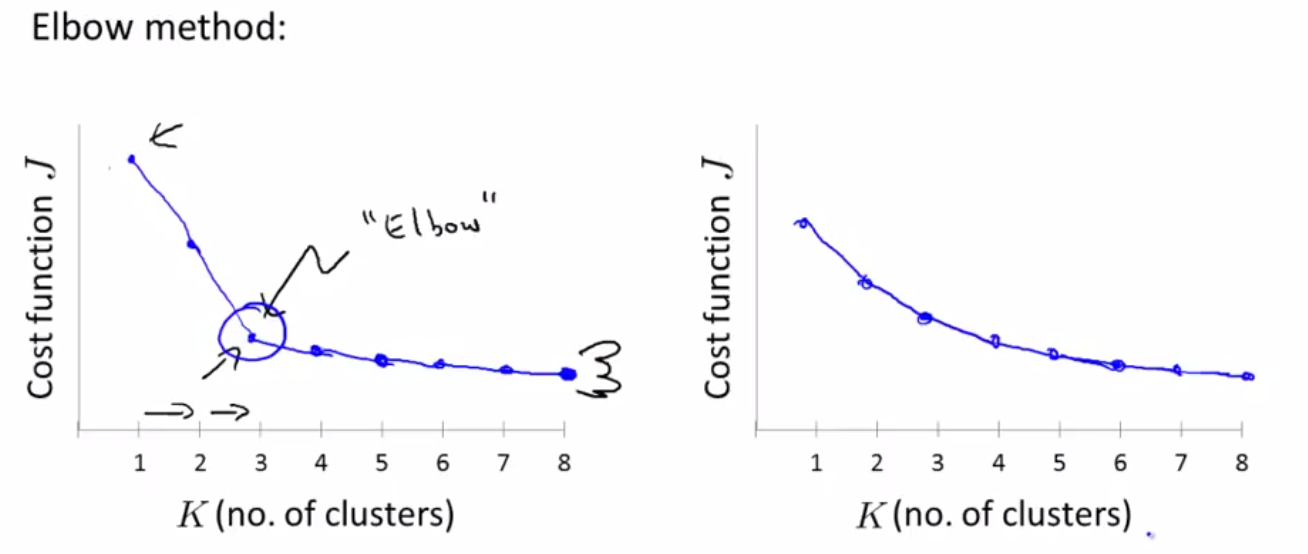
如果J随着K值的变化出现左图的情况,即存在一个K值,能够明显看到J的变化,这时候可能选择K=3作为K的值。而,如果J随着K值的变化出现右图所示的情况,则我们没有办法确定K的值,此时肘部判断法失效。
因此,我们经常使用确定K的方法是下面的方法,即根据我们的需求和目的来确定K,同样我们拿衣服尺寸来进行分类:
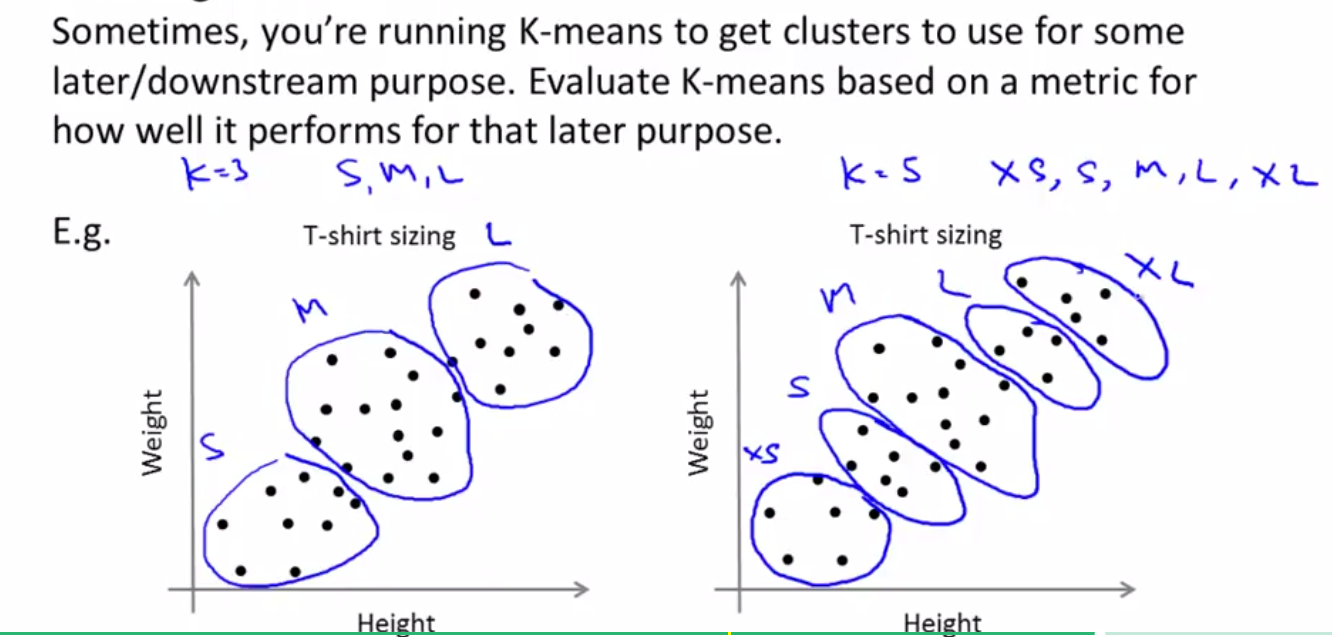
左图中K=3,右图中K=5,我们经常通过K=?时,顾客最多,销量最高,或者顾客更满意呢这些因素来确定。
K的选择我们大多数时候还是通过手工方式进行选择(因为Elbow method只适用于部分情况,如果可以的话,可以使用Elbow method),更好的方法是根据你的目的判断K=?才是最能够达到你的分类目的的。
一、Unsupervised Learning: Introduction(非监督学习简介)
之前介绍的线性回归、logistic回归以及神经网络等都是监督学习的例子,通过给出一系统样本,通过这些样本去训练模型进行预测,在这些样本中,是包含y标签的,即实际值。
在非监督学习中,我们给一系列样本数据
,在这些数据中,区别于监督学习最明显的特征便是没有这些实际值,我们通过聚类或者其他方式去将这些样本分类。
二、K-Means Algorithm(K-Means算法)
下面通过一个图形例子引入K-Means算法,如下图:下面是K-Means算法的输入,以及具体步骤,主要分为簇心的初始化和簇心的移动。
既然我们要让簇心μ_k移动到分配给它的那些点的均值处,如果存在一个没有点可以分配给它的聚类中心,那怎么办呢?
一般情况下,我们会选择直接移除这个簇心,但是如果这样,我们将会得到K-1个簇而非K个,如果你仍需要得到K个簇,那么可以通过重新找一个簇心来使全部簇心个数为K,不过,直接移除簇心是最常见的用法。(在实际情况中,这种情况很少会发生)。
上面讲的例子,样本是分开成几部分的,那么对于没有明显分开的样本,我们可以使用K-Means进行分类吗?
即使是对于右边这种没有明显分开的例子,我们仍能够使用K-Means将其分为3类,若需要进行小、中、大号的服装设计,则可以根据这3个分类来确定具体的尺寸大小
三、Optimization Objective(优化目标)
下图是几个字母的含义,以及优化目标函数下图讲解了K-Means过程中是怎样使优化目标函数达到最小值的。
四、Random Initialization(随机初始化)
初始化规则:(1)K<m
(2)随机挑选k个训练样本
(3)令μ_1,μ_2,...,μ_k等于这k个样本。
如下图,随机选择的可能结果,
在初始化的时候,有时候我们能够得到
在上图中,如果情况比较好,可能会初始化簇心,使得K-Means能够得到全局最优解。
但是在情况不好的时候,可能会出现下面两种情况,即出现局部最优解,为了避免这种情况,我们需要多次地尝试初始化。
For i = 1 to 100 {
Randomly initialize K-means.
Run K-means. Get
.
Compute cost function(distortion)
.
}
Pick clustering that gave lowest cost
.
五、Choosing the Number of Clusters(如何选择聚类的数目?)
面对同样一个数据集,有的人可能觉得觉得分成4类,即K=4,而有的人可能会觉得分成2类,即K=2,如下图:那么我们应该如何确定K的值呢?
方法一:Elbow method(这个方法可能只能偶尔适用,有时候是不能够通过这种方法确定K的值得),如下图:
如果J随着K值的变化出现左图的情况,即存在一个K值,能够明显看到J的变化,这时候可能选择K=3作为K的值。而,如果J随着K值的变化出现右图所示的情况,则我们没有办法确定K的值,此时肘部判断法失效。
因此,我们经常使用确定K的方法是下面的方法,即根据我们的需求和目的来确定K,同样我们拿衣服尺寸来进行分类:
左图中K=3,右图中K=5,我们经常通过K=?时,顾客最多,销量最高,或者顾客更满意呢这些因素来确定。
K的选择我们大多数时候还是通过手工方式进行选择(因为Elbow method只适用于部分情况,如果可以的话,可以使用Elbow method),更好的方法是根据你的目的判断K=?才是最能够达到你的分类目的的。

相关文章推荐
- 聚类——监督学习与无监督学习
- Machine learning —Machine learning :分类和聚类,监督学习和非监督学习
- 《机器学习实战》学习笔记-[13]-无监督学习-利用K-均值聚类对未标注数据分组
- 【Scikit-Learn 中文文档】聚类 - 无监督学习 - 用户指南 | ApacheCN
- 《Python机器学习及实践》----无监督学习之数据聚类
- 分类与聚类,监督学习与无监督学习
- 【Scikit-Learn 中文文档】二十一:聚类 - 无监督学习 - 用户指南 | ApacheCN
- 无监督学习典例:聚类
- 什么是无监督学习(监督学习,半监督学习,无监督聚类)?
- 【Scikit-Learn 中文文档】聚类 - 无监督学习 - 用户指南 | ApacheCN
- 聚类(序)——监督学习与无监督学习
- 分类与聚类 监督学习与无监督学习
- 聚类(序)——监督学习与无监督学习
- 机器学习-->无监督学习-->聚类
- 聚类(序)——监督学习与无监督学习
- 聚类(序)——监督学习与无监督学习
- 分类与聚类 监督学习与无监督学习
- [数据挖掘课程笔记]无监督学习——聚类(clustering)
- 有监督学习、无监督学习、分类、聚类、回归等概念
- 【Scikit-Learn 中文文档】双聚类 - 无监督学习 - 用户指南 | ApacheCN