正态分布随机数的产生
2017-05-12 17:11
274 查看
最近平凡听到关于正态分布采样相关的内容,突然想到一个问题:
到底如何利用正态分布采样?
正好近期模式识别课程上也有一个相关的内容,整理了一下查到的资料。
一。柱状图估计分布
假设样本x N(u,θ), 其pdf图如下:
设想一下如果我们并不是很清楚正态分布的mean和var,只有一些训练的数据样本,该如何估计样本分布的参数?
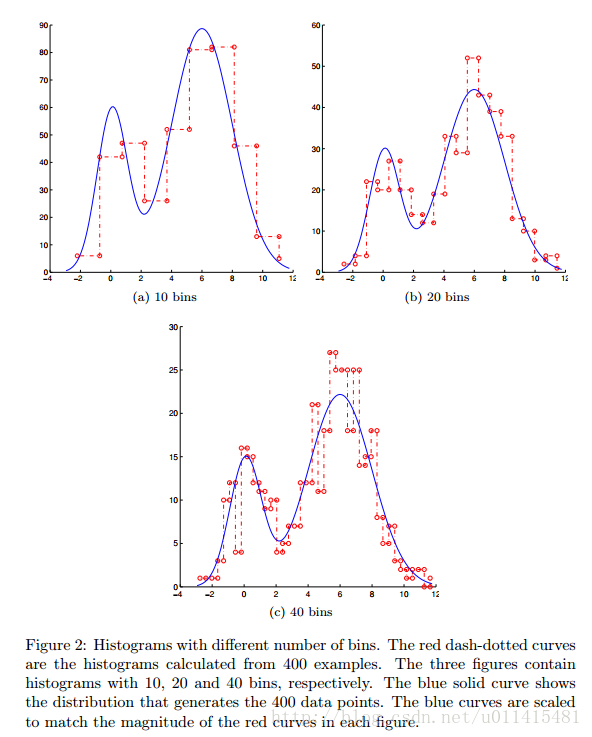
【图片来自南京大学吴建鑫老师的讲义】
上图中的bin就是把数据划分区间,然后统计每个区间点的个数,然后根据走势画出的分布图,当然上图主要是解释区间太密集导致的过拟合现象,不是这里讨论的重点。
但是从这个图可以思考一些问题,比如所谓数据服从正态分布是什么意思?图表示的是概率,其实也就是说点落在均值附近的概率比较大。
二。正态分布随机数的产生
有一篇博客写的蛮清楚的:http://cos.name/2015/06/generating-normal-distr-variates/
解释了Python中rand函数的实现,产生正态分布的过程就是:
就是Box-Muller算法。相关的还有Rejection Sampling,其实这个用到的比较多。
到底如何利用正态分布采样?
正好近期模式识别课程上也有一个相关的内容,整理了一下查到的资料。
一。柱状图估计分布
假设样本x N(u,θ), 其pdf图如下:
设想一下如果我们并不是很清楚正态分布的mean和var,只有一些训练的数据样本,该如何估计样本分布的参数?
【图片来自南京大学吴建鑫老师的讲义】
上图中的bin就是把数据划分区间,然后统计每个区间点的个数,然后根据走势画出的分布图,当然上图主要是解释区间太密集导致的过拟合现象,不是这里讨论的重点。
但是从这个图可以思考一些问题,比如所谓数据服从正态分布是什么意思?图表示的是概率,其实也就是说点落在均值附近的概率比较大。
二。正态分布随机数的产生
有一篇博客写的蛮清楚的:http://cos.name/2015/06/generating-normal-distr-variates/
解释了Python中rand函数的实现,产生正态分布的过程就是:
# When x and y are two variables from [0, 1), uniformly # distributed, then # # cos(2*pi*x)*sqrt(-2*log(1-y)) # sin(2*pi*x)*sqrt(-2*log(1-y)) # # are two *independent* variables with normal distribution
就是Box-Muller算法。相关的还有Rejection Sampling,其实这个用到的比较多。

相关文章推荐
- java正态分布随机数产生方法
- C#产生正态分布、泊松分布、指数分布、负指数分布随机数(原创)
- Matlab中产生正态分布随机数的函数normrnd-----用来产生高斯随机矩阵
- C语言产生标准正态分布或高斯分布随机数
- matlab函数randn:产生正态分布的随机数或矩阵的函数
- 如何产生正态分布的随机数?
- randn:产生正态分布的随机数或矩阵的函数
- 使用rand()产生服从高斯/正态分布的随机数
- java产生正态分布随机数
- C语言产生满足正态分布的随机数
- JAVA自定义算法产生正态分布随机数
- 产生正态分布随机数
- Python使用numpy产生正态分布随机数的向量或矩阵操作示例
- 产生满足正态分布的随机数
- C++产生正态分布的随机数
- C产生正态分布随机数写入文件并读出后用快速排序法排序
- 【matlab】在vc6.0中调用matlab中的正态分布产生随机数
- Matlab中产生正态分布随机数的函数normrnd
- C语言产生满足正态分布的随机数
- Fortran产生正态分布的随机数