【python学习笔记】10:Beautiful Soup模块的使用
2017-05-12 16:23
651 查看
Beautiful Soup模块的使用流程:
①根据下载好的HTML网页字符串,创建一个Beautiful Soup对象,创建时就将整个网页字符串加载成了一个DOM树。
②根据这个DOM树,进行各个节点的搜索:find(只会搜索出第一个满足要求的节点)、find_all(搜索出所有满足要求的节点),这两个方法的参数是一模一样的。
③得到节点以后,就可以访问节点的名称、属性、文字(相应地,在搜索节点时也可以按照节点的名称、属性、文字来进行搜索)。

*创建Beautiful Soup对象
*搜索节点(find,find_all)
*访问节点信息
下面就来测试一下,假设已经获取了一个网页字符串。
*测试代码
运行结果:
①根据下载好的HTML网页字符串,创建一个Beautiful Soup对象,创建时就将整个网页字符串加载成了一个DOM树。
②根据这个DOM树,进行各个节点的搜索:find(只会搜索出第一个满足要求的节点)、find_all(搜索出所有满足要求的节点),这两个方法的参数是一模一样的。
③得到节点以后,就可以访问节点的名称、属性、文字(相应地,在搜索节点时也可以按照节点的名称、属性、文字来进行搜索)。
*创建Beautiful Soup对象
from bs4 import BeautifulSoup #根据HTML网页字符串创建BeautifulSoup对象 soup=BeautifulSoup( html_doc, #HTML文档字符串 'html.parser', #HTML解析器 from_encoding='utf-8' #HTML文档的编码 )
*搜索节点(find,find_all)
#方法:find_all(name,attrs,string)即为名称、属性、文字
#查找所有标签为a的节点
soup.find_all('a')
#查找所有标签为a,链接符合/view/123.htm形式的节点
soup.find_all('a',href='/view/123.htm')
#bs强大的地方还在于对名称、属性、文字都可以传入正则表达式
soup.find_all('a',href=re.compile(r'/view/\d+\.htm'))
#查找所有标签为div,class为abc,文字为Python的节点
soup.find_all('div',class_='abc',string='Python')
#class后面加下划线是因为和python关键字区分开*访问节点信息
#得到节点:<a href='1.html'>Python</a> #获取查找到的节点的标签名称 node.name #获取查找到的a节点的href属性(以字典形式访问) node['href'] #获取查找到的a节点的链接文字 node.get_text()
下面就来测试一下,假设已经获取了一个网页字符串。
*测试代码
#下面是一个文档字符串,用来做我们测试的素材
html_doc = "
4000
""
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
#创建bs对象
from bs4 import BeautifulSoup
soup=BeautifulSoup(html_doc,'html.parser')
#格式化输出
#print(soup.prettify())
#获取所有链接
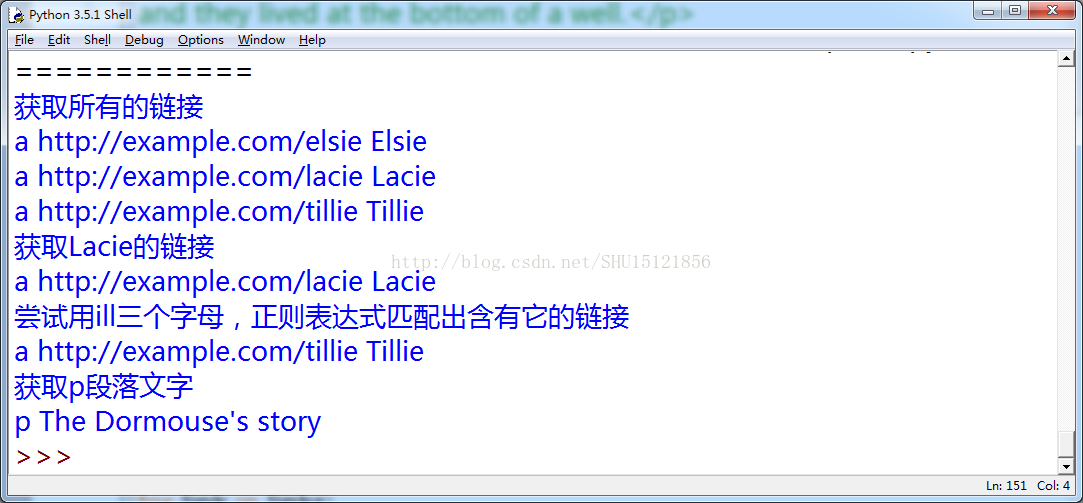
print ('获取所有的链接')
links=soup.find_all('a')
for link in links:
print (link.name,link['href'],link.get_text())
#获取某个指定的链接(注意"某个"是表示用了find,"指定"是表示查询有附加条件)
print ('获取Lacie的链接')
link_node=soup.find('a',href='http://example.com/lacie')
print (link_node.name,link_node['href'],link_node.get_text())
#正则匹配
import re
print ('尝试用ill三个字母,正则表达式匹配出含有它的链接')
link_node=soup.find('a',href=re.compile(r'ill'))
print (link_node.name,link_node['href'],link_node.get_text())
#获取其它标签试试
print ('获取p段落文字')
p_node=soup.find('p',class_='title')
print (p_node.name,p_node.get_text())运行结果:

相关文章推荐
- 【Python】学习笔记——-6.1、使用模块
- Python学习笔记之os模块使用总结
- 学习笔记(11月10日)--python常用内置模块的使用(logging, os, command)
- Python学习笔记(四十一)— 内置模块(10)urllib
- python学习笔记12-模块使用
- python学习笔记之使用smtplib模块发送邮件
- python学习笔记之使用threading模块实现多线程(转)
- Python3学习笔记(urllib模块的使用)转http://www.cnblogs.com/Lands-ljk/p/5447127.html
- python 学习笔记10-----模块
- Python3学习笔记 urllib模块的使用
- Python之学习笔记(模块的使用)
- 【Python】学习笔记——-6.2、使用第三方模块
- Python下字符串的创建和转义字符的使用 - 千月的python linux 系统管理指南学习笔记(10)
- python学习笔记10(函数一): 函数使用、调用、返回值
- Python学习笔记之os模块使用总结
- Python学习笔记(九)——使用selenium模块
- python学习笔记之使用threading模块实现多线程(转)
- python 学习笔记 13 -- 经常使用的时间模块之time