深度学习Deeplearning4j 入门实战(3):简介Nd4j中JavaCPP技术的应用
2017-05-08 13:59
956 查看
Deeplearning4j中张量的计算是由一个叫Nd4j的库来完成的。它类似于Python中的numpy,对高维向量的计算有比较好的支持。并且,为了提高运算的性能,很多计算任务是通过调用C++来完成的。具体来说,底层C++运行张量计算可以选择的backend有:BLAS,OpenBLAS,
Intel MKL等,上层Java逻辑是通过JavaCPP技术来调用这些库。JavaCPP是也是一个开源库(https://github.com/bytedeco/javacpp),和大部分其他JNI的技术一样,它的目的也是为了实现JVM
on-heap memory 到 off-heap memory的映射和操作。它通过一些助记符可以将自己编写的C++类或者C++标准库中文件进行编译并自动生成C++ JNI代码,不需要手动编写。到目前为止,JavaCPP已经封装了包括OpenCV,ffmpeg等多个优秀的C++项目,方便了很多Java程序员对这些开源库的调用。小弟我自己看到网上对于JavaCPP的使用介绍并不是特别多,所以写了这篇博客,简单介绍下JavaCPP的基本使用,作为一篇入门的文章供大家参考,其中代码在windows
7上可以正常运行。
使用JavaCPP技术主要可以分为以下几个步骤:
1.编写Java的逻辑代码:可以是自己实现的Java类,也可以通过助记符引用C++的标准库
2.编译你所写的Java文件,生成字节码文件
3.运行步骤2中生成的字节码文件,自动生成C++ JNI代码
4.利用步骤3中生成的JNI代码,生成本地共享库/动态链接库
5.指定shared library路径,加载shared library并运行字节码(自动调用shared library)
由于C++中有很多高效的算法实现,比如排序、查找、全排列等等,而且据我了解Java中并没有全排列算法的实现,所以这里就结合以上说的5个步骤,以Java调用C++中的全排列算法(next_permutataion)为目标来具体说说JavaCPP技术的应用。
首先,我们在IDE环境中新建一个Maven工程,加入JavaCPP的Maven依赖如下:
[html] view
plain copy
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>javacpp</artifactId>
<version>1.3.1</version>
</dependency>
然后,在工程中新建Java文件,代码如下:
[java] view
plain copy
package cppalgo;
import java.util.Arrays;
import org.bytedeco.javacpp.IntPointer;
import org.bytedeco.javacpp.Loader;
import org.bytedeco.javacpp.annotation.Namespace;
import org.bytedeco.javacpp.annotation.Platform;
@Platform(include="<algorithm>") //include CPP header file
@Namespace("std") //CPP standard namespace
public class Algorithm {
static { Loader.load(); } //load shared library
/***
* CPP sort algorithm
*/
public static native void sort(IntPointer first, IntPointer last);
/***
* CPP next_permutation algorithm
*/
public static native boolean next_permutation(IntPointer first, IntPointer last);
@SuppressWarnings({ "resource" })
public static void main(String[] args){
int[] ary = new int[]{10, -1, 2, 8, -9};
IntPointer int_ptr = new IntPointer(ary);
IntPointer end = new IntPointer(int_ptr.position(ary.length));
IntPointer begin = new IntPointer(int_ptr.position(0));
Algorithm.sort(begin, end);
System.out.println("before sort: " + Arrays.toString(ary));
int_ptr.get(ary);
System.out.println("after sort: " + Arrays.toString(ary));
//
System.out.println("next permutaiton: ");
int count = 0;
do{
int_ptr.get(ary); //copy array from off-heap to on-heap
System.out.println(Arrays.toString(ary));
++count;
}while( next_permutation(begin ,end));
System.out.println(count);
}
}
对于这段代码我做一些补充解释。
@Platform和@Namespace都是对应于C++里的一些概念或语言特性做的Java级别的支持。目的也是简化JNI C++代码的开发,当后面编译生成JNI文件的时候,这些信息都会自动添加到.cpp文件中。代码中的sort和next_permutation是对应于C++标准库中的这两个算法的名称,也就是快速排序和全排列算法。注意,名称务必保持一致。在声明这两个方法的时候,IntPointer是作为入参的。它其实是C++指针的一个wrapper。在C++中,算法的入参一般是迭代器,当然指针也是一种迭代器,或者说迭代器是指针一种wrapper。这里我们的目的是对整型数组进行排序和全排列。在main方法中,就是具体的逻辑了。有一点要注意,就是必须先声明end
IntPointer再声明begin IntPointer。原因我在最后会做些分析。
接下来,我们对Java代码进行编译,生成字节码文件。具体的命令是:javac -cp javacpp-1.3.1.jar cppalgo/Algorithm.java。这个命令在控制台完成,或者用IDE的outputjar应该也行。结果会生成.class文件。javacpp-1.3.1.jar这个jar包,就是Maven依赖加入后,从Maven仓库里下载的jar。
再接下来,我们生成C++ JNI文件。具体的命令是:java -jar javacpp-1.3.1.jar cppalgo.Algorithm。一般来说,运行这个命令它首先会生成JNI C++文件,然后调用C++编译器生成shared library。但是,在windows上,自动链接编译器,貌似是蛮麻烦的还容易配置出错。所以,实际上运行这个命令后,是可以生成.cpp文件,但也会报连接编译器的错误:
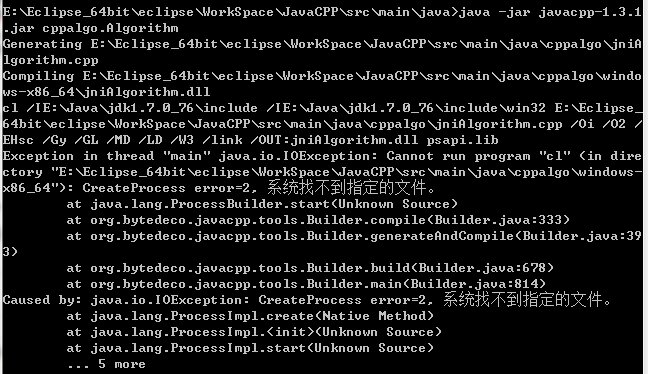
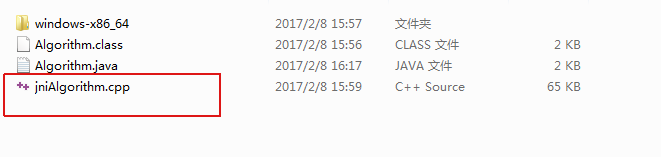
虽然报了错,但JNI的CPP文件是正常生成的,如下图中的红框:
既然我们有了JNI的C++文件,那么其实我们可以利用编译器,比如Visual Studio来对其进行编译生成shared library。我们在VS中新建dll项目(具体这里不详细讲了,和一般的dll项目一样,可网上查阅),项目命名为jniAlgorithm,也就是和生成的C++文件同名。将之前生成的JNI C++文件拷贝到项目的源文件目录中,并加上这一句:
[cpp] view
plain copy
#include "stdafx.h"
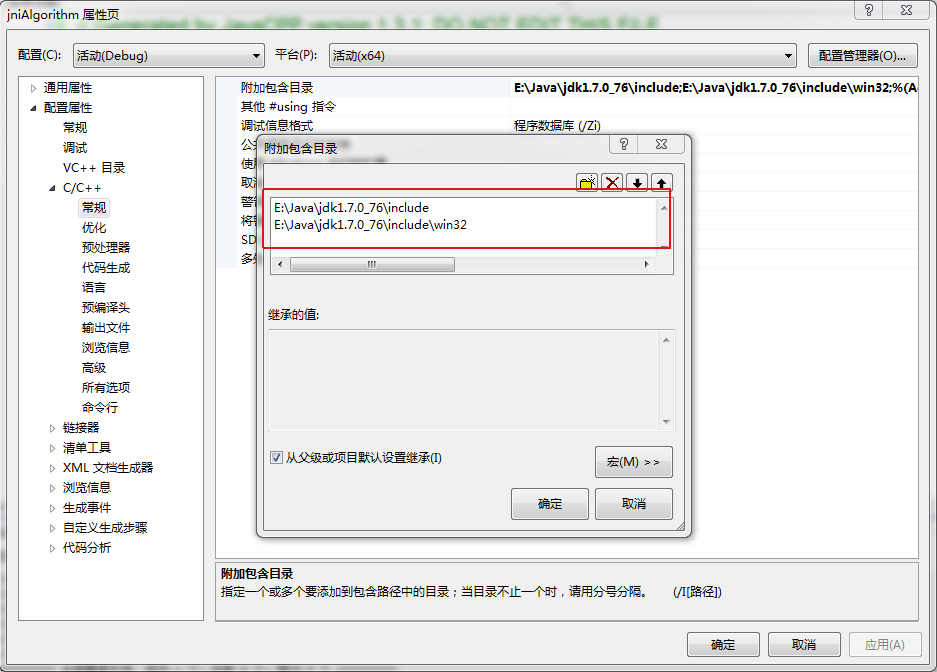
此外,由于编译的时候需要调用jni.h之类的头文件,所以需要在项目的头文件引用配置中,将JDK中jni.h所在的目录路径添加进去。我自己的在VS2012中的额外头文件配置路径如下:
此外,如果是64位的系统,还需要将整个项目配置成64位的dll输出,具体可网上搜索相关内容。
然后编译整个项目,如果成功,就会生成shared library,也就是windows平台上的dll文件。我这边生成的文件如下:

到此,整个工作已经接近完成。最后,在Java IDE中,执行那个文件,当然最好加上这一句:-Djava.library.path=动态链接库路径。也就是指定刚才动态链接库生成的路径,这样程序就可以找得到那个dll文件。执行的结果如下:
[plain] view
plain copy
before sort: [10, -1, 2, 8, -9]
after sort: [-9, -1, 2, 8, 10]
next permutaiton:
[-9, -1, 2, 8, 10]
[-9, -1, 2, 10, 8]
[-9, -1, 8, 2, 10]
[-9, -1, 8, 10, 2]
[-9, -1, 10, 2, 8]
[-9, -1, 10, 8, 2]
[-9, 2, -1, 8, 10]
[-9, 2, -1, 10, 8]
[-9, 2, 8, -1, 10]
[-9, 2, 8, 10, -1]
[-9, 2, 10, -1, 8]
[-9, 2, 10, 8, -1]
[-9, 8, -1, 2, 10]
[-9, 8, -1, 10, 2]
[-9, 8, 2, -1, 10]
[-9, 8, 2, 10, -1]
[-9, 8, 10, -1, 2]
[-9, 8, 10, 2, -1]
[-9, 10, -1, 2, 8]
[-9, 10, -1, 8, 2]
[-9, 10, 2, -1, 8]
[-9, 10, 2, 8, -1]
[-9, 10, 8, -1, 2]
[-9, 10, 8, 2, -1]
[-1, -9, 2, 8, 10]
[-1, -9, 2, 10, 8]
[-1, -9, 8, 2, 10]
[-1, -9, 8, 10, 2]
[-1, -9, 10, 2, 8]
[-1, -9, 10, 8, 2]
[-1, 2, -9, 8, 10]
[-1, 2, -9, 10, 8]
[-1, 2, 8, -9, 10]
[-1, 2, 8, 10, -9]
[-1, 2, 10, -9, 8]
[-1, 2, 10, 8, -9]
[-1, 8, -9, 2, 10]
[-1, 8, -9, 10, 2]
[-1, 8, 2, -9, 10]
[-1, 8, 2, 10, -9]
[-1, 8, 10, -9, 2]
[-1, 8, 10, 2, -9]
[-1, 10, -9, 2, 8]
[-1, 10, -9, 8, 2]
[-1, 10, 2, -9, 8]
[-1, 10, 2, 8, -9]
[-1, 10, 8, -9, 2]
[-1, 10, 8, 2, -9]
[2, -9, -1, 8, 10]
[2, -9, -1, 10, 8]
[2, -9, 8, -1, 10]
[2, -9, 8, 10, -1]
[2, -9, 10, -1, 8]
[2, -9, 10, 8, -1]
[2, -1, -9, 8, 10]
[2, -1, -9, 10, 8]
[2, -1, 8, -9, 10]
[2, -1, 8, 10, -9]
[2, -1, 10, -9, 8]
[2, -1, 10, 8, -9]
[2, 8, -9, -1, 10]
[2, 8, -9, 10, -1]
[2, 8, -1, -9, 10]
[2, 8, -1, 10, -9]
[2, 8, 10, -9, -1]
[2, 8, 10, -1, -9]
[2, 10, -9, -1, 8]
[2, 10, -9, 8, -1]
[2, 10, -1, -9, 8]
[2, 10, -1, 8, -9]
[2, 10, 8, -9, -1]
[2, 10, 8, -1, -9]
[8, -9, -1, 2, 10]
[8, -9, -1, 10, 2]
[8, -9, 2, -1, 10]
[8, -9, 2, 10, -1]
[8, -9, 10, -1, 2]
[8, -9, 10, 2, -1]
[8, -1, -9, 2, 10]
[8, -1, -9, 10, 2]
[8, -1, 2, -9, 10]
[8, -1, 2, 10, -9]
[8, -1, 10, -9, 2]
[8, -1, 10, 2, -9]
[8, 2, -9, -1, 10]
[8, 2, -9, 10, -1]
[8, 2, -1, -9, 10]
[8, 2, -1, 10, -9]
[8, 2, 10, -9, -1]
[8, 2, 10, -1, -9]
[8, 10, -9, -1, 2]
[8, 10, -9, 2, -1]
[8, 10, -1, -9, 2]
[8, 10, -1, 2, -9]
[8, 10, 2, -9, -1]
[8, 10, 2, -1, -9]
[10, -9, -1, 2, 8]
[10, -9, -1, 8, 2]
[10, -9, 2, -1, 8]
[10, -9, 2, 8, -1]
[10, -9, 8, -1, 2]
[10, -9, 8, 2, -1]
[10, -1, -9, 2, 8]
[10, -1, -9, 8, 2]
[10, -1, 2, -9, 8]
[10, -1, 2, 8, -9]
[10, -1, 8, -9, 2]
[10, -1, 8, 2, -9]
[10, 2, -9, -1, 8]
[10, 2, -9, 8, -1]
[10, 2, -1, -9, 8]
[10, 2, -1, 8, -9]
[10, 2, 8, -9, -1]
[10, 2, 8, -1, -9]
[10, 8, -9, -1, 2]
[10, 8, -9, 2, -1]
[10, 8, -1, -9, 2]
[10, 8, -1, 2, -9]
[10, 8, 2, -9, -1]
[10, 8, 2, -1, -9]
120
我们看到,无论是排序还是全排列,结果都符合我们的预期。也就是说,到此为止,一个简单的JavaCPP应用就完成了。
最后,我说下可能存在的坑:
1.之前讲的,end Pointer需要比begin Pointer先声明的原因:在程序中,调用的position接口会改变指针的位置,并且这个位置信息会传到C++中。因此,要先声明end Pointer。
2.Pointer的get方法:将off-heap memory中的数据copy到on-heap中,这步不可缺少。
3.Pointer中存在deallocate方法,用于释放C++的内存。但是,Java中对象并不会被立刻gc,其实也不可能被立刻gc
总结一下。其实在Java调用C++的场景在算法中还是比较多的。原因可能在于
1.已经有很多高效的C++的算法库存在,如opencv等等
2.理论上,C++的执行效率会高于Java。毕竟JVM有些操作也是通过调用C++来做的。因此直接将大量运算就放在off-heap上进行,也是一种选择
3.内存利用率可能会更高。C++的缺点在于程序员需要自己管理内存,管理不当,可能会造成内存泄漏。但是这恰恰也是其有点,因为及时地释放内存,可以提高使用效率。不像Java,基本只能依赖gc。
Intel MKL等,上层Java逻辑是通过JavaCPP技术来调用这些库。JavaCPP是也是一个开源库(https://github.com/bytedeco/javacpp),和大部分其他JNI的技术一样,它的目的也是为了实现JVM
on-heap memory 到 off-heap memory的映射和操作。它通过一些助记符可以将自己编写的C++类或者C++标准库中文件进行编译并自动生成C++ JNI代码,不需要手动编写。到目前为止,JavaCPP已经封装了包括OpenCV,ffmpeg等多个优秀的C++项目,方便了很多Java程序员对这些开源库的调用。小弟我自己看到网上对于JavaCPP的使用介绍并不是特别多,所以写了这篇博客,简单介绍下JavaCPP的基本使用,作为一篇入门的文章供大家参考,其中代码在windows
7上可以正常运行。
使用JavaCPP技术主要可以分为以下几个步骤:
1.编写Java的逻辑代码:可以是自己实现的Java类,也可以通过助记符引用C++的标准库
2.编译你所写的Java文件,生成字节码文件
3.运行步骤2中生成的字节码文件,自动生成C++ JNI代码
4.利用步骤3中生成的JNI代码,生成本地共享库/动态链接库
5.指定shared library路径,加载shared library并运行字节码(自动调用shared library)
由于C++中有很多高效的算法实现,比如排序、查找、全排列等等,而且据我了解Java中并没有全排列算法的实现,所以这里就结合以上说的5个步骤,以Java调用C++中的全排列算法(next_permutataion)为目标来具体说说JavaCPP技术的应用。
首先,我们在IDE环境中新建一个Maven工程,加入JavaCPP的Maven依赖如下:
[html] view
plain copy
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>javacpp</artifactId>
<version>1.3.1</version>
</dependency>
然后,在工程中新建Java文件,代码如下:
[java] view
plain copy
package cppalgo;
import java.util.Arrays;
import org.bytedeco.javacpp.IntPointer;
import org.bytedeco.javacpp.Loader;
import org.bytedeco.javacpp.annotation.Namespace;
import org.bytedeco.javacpp.annotation.Platform;
@Platform(include="<algorithm>") //include CPP header file
@Namespace("std") //CPP standard namespace
public class Algorithm {
static { Loader.load(); } //load shared library
/***
* CPP sort algorithm
*/
public static native void sort(IntPointer first, IntPointer last);
/***
* CPP next_permutation algorithm
*/
public static native boolean next_permutation(IntPointer first, IntPointer last);
@SuppressWarnings({ "resource" })
public static void main(String[] args){
int[] ary = new int[]{10, -1, 2, 8, -9};
IntPointer int_ptr = new IntPointer(ary);
IntPointer end = new IntPointer(int_ptr.position(ary.length));
IntPointer begin = new IntPointer(int_ptr.position(0));
Algorithm.sort(begin, end);
System.out.println("before sort: " + Arrays.toString(ary));
int_ptr.get(ary);
System.out.println("after sort: " + Arrays.toString(ary));
//
System.out.println("next permutaiton: ");
int count = 0;
do{
int_ptr.get(ary); //copy array from off-heap to on-heap
System.out.println(Arrays.toString(ary));
++count;
}while( next_permutation(begin ,end));
System.out.println(count);
}
}
对于这段代码我做一些补充解释。
@Platform和@Namespace都是对应于C++里的一些概念或语言特性做的Java级别的支持。目的也是简化JNI C++代码的开发,当后面编译生成JNI文件的时候,这些信息都会自动添加到.cpp文件中。代码中的sort和next_permutation是对应于C++标准库中的这两个算法的名称,也就是快速排序和全排列算法。注意,名称务必保持一致。在声明这两个方法的时候,IntPointer是作为入参的。它其实是C++指针的一个wrapper。在C++中,算法的入参一般是迭代器,当然指针也是一种迭代器,或者说迭代器是指针一种wrapper。这里我们的目的是对整型数组进行排序和全排列。在main方法中,就是具体的逻辑了。有一点要注意,就是必须先声明end
IntPointer再声明begin IntPointer。原因我在最后会做些分析。
接下来,我们对Java代码进行编译,生成字节码文件。具体的命令是:javac -cp javacpp-1.3.1.jar cppalgo/Algorithm.java。这个命令在控制台完成,或者用IDE的outputjar应该也行。结果会生成.class文件。javacpp-1.3.1.jar这个jar包,就是Maven依赖加入后,从Maven仓库里下载的jar。
再接下来,我们生成C++ JNI文件。具体的命令是:java -jar javacpp-1.3.1.jar cppalgo.Algorithm。一般来说,运行这个命令它首先会生成JNI C++文件,然后调用C++编译器生成shared library。但是,在windows上,自动链接编译器,貌似是蛮麻烦的还容易配置出错。所以,实际上运行这个命令后,是可以生成.cpp文件,但也会报连接编译器的错误:
虽然报了错,但JNI的CPP文件是正常生成的,如下图中的红框:
既然我们有了JNI的C++文件,那么其实我们可以利用编译器,比如Visual Studio来对其进行编译生成shared library。我们在VS中新建dll项目(具体这里不详细讲了,和一般的dll项目一样,可网上查阅),项目命名为jniAlgorithm,也就是和生成的C++文件同名。将之前生成的JNI C++文件拷贝到项目的源文件目录中,并加上这一句:
[cpp] view
plain copy
#include "stdafx.h"
此外,由于编译的时候需要调用jni.h之类的头文件,所以需要在项目的头文件引用配置中,将JDK中jni.h所在的目录路径添加进去。我自己的在VS2012中的额外头文件配置路径如下:
此外,如果是64位的系统,还需要将整个项目配置成64位的dll输出,具体可网上搜索相关内容。
然后编译整个项目,如果成功,就会生成shared library,也就是windows平台上的dll文件。我这边生成的文件如下:
到此,整个工作已经接近完成。最后,在Java IDE中,执行那个文件,当然最好加上这一句:-Djava.library.path=动态链接库路径。也就是指定刚才动态链接库生成的路径,这样程序就可以找得到那个dll文件。执行的结果如下:
[plain] view
plain copy
before sort: [10, -1, 2, 8, -9]
after sort: [-9, -1, 2, 8, 10]
next permutaiton:
[-9, -1, 2, 8, 10]
[-9, -1, 2, 10, 8]
[-9, -1, 8, 2, 10]
[-9, -1, 8, 10, 2]
[-9, -1, 10, 2, 8]
[-9, -1, 10, 8, 2]
[-9, 2, -1, 8, 10]
[-9, 2, -1, 10, 8]
[-9, 2, 8, -1, 10]
[-9, 2, 8, 10, -1]
[-9, 2, 10, -1, 8]
[-9, 2, 10, 8, -1]
[-9, 8, -1, 2, 10]
[-9, 8, -1, 10, 2]
[-9, 8, 2, -1, 10]
[-9, 8, 2, 10, -1]
[-9, 8, 10, -1, 2]
[-9, 8, 10, 2, -1]
[-9, 10, -1, 2, 8]
[-9, 10, -1, 8, 2]
[-9, 10, 2, -1, 8]
[-9, 10, 2, 8, -1]
[-9, 10, 8, -1, 2]
[-9, 10, 8, 2, -1]
[-1, -9, 2, 8, 10]
[-1, -9, 2, 10, 8]
[-1, -9, 8, 2, 10]
[-1, -9, 8, 10, 2]
[-1, -9, 10, 2, 8]
[-1, -9, 10, 8, 2]
[-1, 2, -9, 8, 10]
[-1, 2, -9, 10, 8]
[-1, 2, 8, -9, 10]
[-1, 2, 8, 10, -9]
[-1, 2, 10, -9, 8]
[-1, 2, 10, 8, -9]
[-1, 8, -9, 2, 10]
[-1, 8, -9, 10, 2]
[-1, 8, 2, -9, 10]
[-1, 8, 2, 10, -9]
[-1, 8, 10, -9, 2]
[-1, 8, 10, 2, -9]
[-1, 10, -9, 2, 8]
[-1, 10, -9, 8, 2]
[-1, 10, 2, -9, 8]
[-1, 10, 2, 8, -9]
[-1, 10, 8, -9, 2]
[-1, 10, 8, 2, -9]
[2, -9, -1, 8, 10]
[2, -9, -1, 10, 8]
[2, -9, 8, -1, 10]
[2, -9, 8, 10, -1]
[2, -9, 10, -1, 8]
[2, -9, 10, 8, -1]
[2, -1, -9, 8, 10]
[2, -1, -9, 10, 8]
[2, -1, 8, -9, 10]
[2, -1, 8, 10, -9]
[2, -1, 10, -9, 8]
[2, -1, 10, 8, -9]
[2, 8, -9, -1, 10]
[2, 8, -9, 10, -1]
[2, 8, -1, -9, 10]
[2, 8, -1, 10, -9]
[2, 8, 10, -9, -1]
[2, 8, 10, -1, -9]
[2, 10, -9, -1, 8]
[2, 10, -9, 8, -1]
[2, 10, -1, -9, 8]
[2, 10, -1, 8, -9]
[2, 10, 8, -9, -1]
[2, 10, 8, -1, -9]
[8, -9, -1, 2, 10]
[8, -9, -1, 10, 2]
[8, -9, 2, -1, 10]
[8, -9, 2, 10, -1]
[8, -9, 10, -1, 2]
[8, -9, 10, 2, -1]
[8, -1, -9, 2, 10]
[8, -1, -9, 10, 2]
[8, -1, 2, -9, 10]
[8, -1, 2, 10, -9]
[8, -1, 10, -9, 2]
[8, -1, 10, 2, -9]
[8, 2, -9, -1, 10]
[8, 2, -9, 10, -1]
[8, 2, -1, -9, 10]
[8, 2, -1, 10, -9]
[8, 2, 10, -9, -1]
[8, 2, 10, -1, -9]
[8, 10, -9, -1, 2]
[8, 10, -9, 2, -1]
[8, 10, -1, -9, 2]
[8, 10, -1, 2, -9]
[8, 10, 2, -9, -1]
[8, 10, 2, -1, -9]
[10, -9, -1, 2, 8]
[10, -9, -1, 8, 2]
[10, -9, 2, -1, 8]
[10, -9, 2, 8, -1]
[10, -9, 8, -1, 2]
[10, -9, 8, 2, -1]
[10, -1, -9, 2, 8]
[10, -1, -9, 8, 2]
[10, -1, 2, -9, 8]
[10, -1, 2, 8, -9]
[10, -1, 8, -9, 2]
[10, -1, 8, 2, -9]
[10, 2, -9, -1, 8]
[10, 2, -9, 8, -1]
[10, 2, -1, -9, 8]
[10, 2, -1, 8, -9]
[10, 2, 8, -9, -1]
[10, 2, 8, -1, -9]
[10, 8, -9, -1, 2]
[10, 8, -9, 2, -1]
[10, 8, -1, -9, 2]
[10, 8, -1, 2, -9]
[10, 8, 2, -9, -1]
[10, 8, 2, -1, -9]
120
我们看到,无论是排序还是全排列,结果都符合我们的预期。也就是说,到此为止,一个简单的JavaCPP应用就完成了。
最后,我说下可能存在的坑:
1.之前讲的,end Pointer需要比begin Pointer先声明的原因:在程序中,调用的position接口会改变指针的位置,并且这个位置信息会传到C++中。因此,要先声明end Pointer。
2.Pointer的get方法:将off-heap memory中的数据copy到on-heap中,这步不可缺少。
3.Pointer中存在deallocate方法,用于释放C++的内存。但是,Java中对象并不会被立刻gc,其实也不可能被立刻gc
总结一下。其实在Java调用C++的场景在算法中还是比较多的。原因可能在于
1.已经有很多高效的C++的算法库存在,如opencv等等
2.理论上,C++的执行效率会高于Java。毕竟JVM有些操作也是通过调用C++来做的。因此直接将大量运算就放在off-heap上进行,也是一种选择
3.内存利用率可能会更高。C++的缺点在于程序员需要自己管理内存,管理不当,可能会造成内存泄漏。但是这恰恰也是其有点,因为及时地释放内存,可以提高使用效率。不像Java,基本只能依赖gc。

相关文章推荐
- Deeplearning4j 实战(3):简介Nd4j中JavaCPP技术的应用
- Deeplearning4j 实战(3):简介Nd4j中Java与CPP技术的应用【转】
- 腾讯QQ会员技术团队:人人都可以做深度学习应用:入门篇(下)
- 深度学习Deeplearning4j 入门实战(2):Deeplearning4j 手写体数字识别Spark实现
- 深度学习Deeplearning4j 入门实战(4):Deep AutoEncoder进行Mnist压缩的Spark实现
- 深度学习Deeplearning4j 入门实战(6):基于LSTM的文本情感识别及其Spark实现
- 深度学习Deeplearning4j入门 实战(1):Deeplearning4j 手写体数字识别
- 深度学习Deeplearning4j 入门实战(5):基于多层感知机的Mnist压缩以及在Spark实现
- Flume学习2_Flume NG简介、配置实战、技术架构应用和可能遇到的问题
- 深度学习与计算机视觉核心技术与应用(学习目录简介)
- 腾讯QQ会员技术团队:人人都可以做深度学习应用:入门篇(下)
- 深度学习Deeplearning4j入门 实战(1):Deeplearning4j 手写体数字识别
- 《Spring 3.x 企业应用开发实战》学习笔记 第三章 IoC容器概述 3.2 相关Java基础知识 类装载器 反射机制
- java实战(八)--------Java框架——SSH框架应用简介
- Java学习之入门简介
- Java基础学习总结(26)——JNDI入门简介
- java web开发学习-15 EJB技术简介
- Kinect学习笔记(六)——深度数据测量技术及应用
- DLL技术应用04 - 零基础入门学习Delphi47
- deep learning in NLP—深度学习在自然语言处理中的应用—入门学习序列