从编程的角度去理解逻辑回归
2017-05-07 15:56
197 查看
先从一本书说起吧----《机器学习实战》
作者在书中讲到逻辑回归的时候,用简短的语言介绍了一下理论之后,就给出了一段代码。然而就是这段代码把我带进了误区,也许不能叫误区,而是因为我自己的水平不够。后来在查阅资料的时候,发现有人也因为这个问题纠结了好久。也许这本书是写给一些有经验的人员看的,不是特别适合作为入门的书。
在查找关于逻辑回归相关资料的时候,发现大多数都是介绍了好多数学公式,所以我一直都在理解数学公式的基础上同时试图在脑海中演练该如何编程实现它,然后再对照上面提到的书中的代码,然后悲哀的发现了解不了。并且,查到的大多数资料上并没有详细的代码实现,如果有,也是跟书上的代码是一样的。
最后,从网上找到书中使用的测试数据,跟踪打印代码中的每个变量,才理解了书中第一段代码的求解原理,进而理解了后面一些代码的原理。现在回过头想想确实比较简单,但是这个简单是有一个前提的:书上的代码或者资料中推导出的的公式或者我自己的理解,这三者之间必须是有一个错误的。
并且在这个过程中,我一直试图绕过那么多数学公式和一堆概念,但是发现很难,所以我按照自己的理解剔除掉一些无用的数学公式和概念,力求用最少的理论解释清楚什么是逻辑回归。
1.逻辑回归的定义
1)有一种定义是这样的:逻辑回归其实是一个线性分类器,只是在外面嵌套了一个逻辑函数,主要用于二分类问题。
这个定义明确的指明了逻辑回归的特点:
a) 一个线性分类器
b)外层有一个逻辑函数
2)假设有一个线性函数z,其一般公式为:
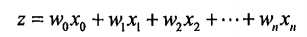
(公式一)
转换成求和公式:
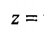

(公式二)
转化成向量的形式:
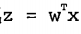
(公式三)
3)逻辑函数(也叫Sigmoid函数)
基本上采用的都是下面这个函数:
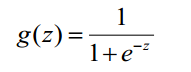
(公式四)
这个函数的作用就是把无限大或者无限小的数据压缩到[0,1]之间,用来估计概率。图像大致为:
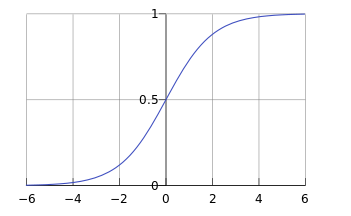
基本上是以0.5分界,0.5以上为1,0.5以下为0。但是这个分界值可以自己设定。
4)逻辑回归函数
综合公式四和公式一或者公式四和公式三,即可得到逻辑回归函数:
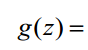
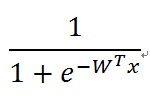
(公式五)或者
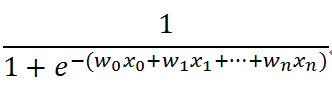
(公式六)
其实,如果编程求解的话,到这里基本就可以了。但是既然都提到了最大似然估计,那我们也说下。
2.最大似然估计
最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
换句话说就是:既然我们无法知道真实值,那么就把这个当作真实值吧!
其唯一的作用就是给这个算法找一个说的过去的理论基础,然后在这个基础上推导出最大似然函数,接着构建损失函数。这对于非数学专业的人来说,用途并不大,有时候甚至会造成理解上的困难,进而变成学习的阻碍。其实,我们完全可以绕过这个阻碍,只去关注最后的结果。
3.求解方式
1)使用梯度下降法求解
经过一系列推导之后,得出梯度下降法求解的核心公式,即权重的更新方式:
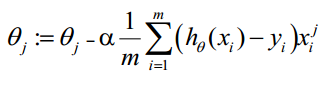
(公式七)
需要说明的是:α表示下降的步长,可以自己指定。hθ 表示损失函数或者惩罚系数。如果hθ 表示惩罚系数,那么如何求的这组系数才是整个逻辑回归算法的重点。
在开始写代码前,再介绍另外一个求解方式:向量化
2)向量化
向量化是使用矩阵计算来代替for循环,以简化计算过程,提高效率。(下面引用下其他文章的讲解:出现的地方太多不知道哪个是原作者,见谅)
向量化过程:
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:

g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。
θ更新过程可以改为:
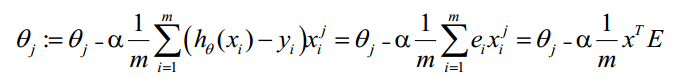
综上所述,向量化后θ更新的步骤如下:
a)求 A=x*θ
b)求 E=g(A)-y
c)求
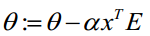
4.实现过程(下面的代码实现的是梯度上升法,其跟梯度下降法的唯一区别就是
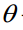
和

之间的减号变成了加号,前者求最大值,后者求最小值)
代码基本脱胎于《机器学习实战》这本书,但是有改动。
1)普通的梯度上升法
下面这段代码,也就是开头提到的那个造成误解的代码,其实现依据是向量化求解,并不是根据公式七来的,所以如果对照公式七理解这段代码会完全摸不着头脑。如果对照向量化后θ(也就是权重)的更新步骤会很容易理解。
2)随机梯度上升发
这个算法,才是符合公式七的算法,但是代码中并没有
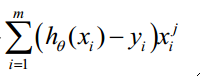
求和这步,只有括号中的那部分,这也是我开头说的三者之间必有一个错误的地方。
只包括核心部分,其他部分见上段代码
3)改进的随机梯度上升算法
书中还讲到了一个改进的随机梯度上升算法。
该算法每次都会调整步长值,即缓解了随着循环次数的增加造成的特征值的波动,也保证了当j<<max(i)时,步长值的下降不是严格下降的。而避免参数的严格下降在优化退火算法中常常用到。
5.使用sklearn包中的逻辑回归算法(非完整代码,缺少部分在第一个代码段)
sklearn包中的LogisticRegression函数,默认使用L2正则化防止过度拟合。
最后得出的预测结果就是0,1值,跟标签对比,有两个分类错了。
6.逻辑回归优缺点
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度可能不高
适用数据类型:数值型和标称型数据
附录:测试数据

View Code
作者在书中讲到逻辑回归的时候,用简短的语言介绍了一下理论之后,就给出了一段代码。然而就是这段代码把我带进了误区,也许不能叫误区,而是因为我自己的水平不够。后来在查阅资料的时候,发现有人也因为这个问题纠结了好久。也许这本书是写给一些有经验的人员看的,不是特别适合作为入门的书。
在查找关于逻辑回归相关资料的时候,发现大多数都是介绍了好多数学公式,所以我一直都在理解数学公式的基础上同时试图在脑海中演练该如何编程实现它,然后再对照上面提到的书中的代码,然后悲哀的发现了解不了。并且,查到的大多数资料上并没有详细的代码实现,如果有,也是跟书上的代码是一样的。
最后,从网上找到书中使用的测试数据,跟踪打印代码中的每个变量,才理解了书中第一段代码的求解原理,进而理解了后面一些代码的原理。现在回过头想想确实比较简单,但是这个简单是有一个前提的:书上的代码或者资料中推导出的的公式或者我自己的理解,这三者之间必须是有一个错误的。
并且在这个过程中,我一直试图绕过那么多数学公式和一堆概念,但是发现很难,所以我按照自己的理解剔除掉一些无用的数学公式和概念,力求用最少的理论解释清楚什么是逻辑回归。
1.逻辑回归的定义
1)有一种定义是这样的:逻辑回归其实是一个线性分类器,只是在外面嵌套了一个逻辑函数,主要用于二分类问题。
这个定义明确的指明了逻辑回归的特点:
a) 一个线性分类器
b)外层有一个逻辑函数
2)假设有一个线性函数z,其一般公式为:
(公式一)
转换成求和公式:
(公式二)
转化成向量的形式:
(公式三)
3)逻辑函数(也叫Sigmoid函数)
基本上采用的都是下面这个函数:
(公式四)
这个函数的作用就是把无限大或者无限小的数据压缩到[0,1]之间,用来估计概率。图像大致为:
基本上是以0.5分界,0.5以上为1,0.5以下为0。但是这个分界值可以自己设定。
4)逻辑回归函数
综合公式四和公式一或者公式四和公式三,即可得到逻辑回归函数:
(公式五)或者
(公式六)
其实,如果编程求解的话,到这里基本就可以了。但是既然都提到了最大似然估计,那我们也说下。
2.最大似然估计
最大似然估计是建立在这样的思想上:已知某个参数能使这个样本出现的概率最大,我们当然不会再去选择其他小概率的样本,所以干脆就把这个参数作为估计的真实值。
换句话说就是:既然我们无法知道真实值,那么就把这个当作真实值吧!
其唯一的作用就是给这个算法找一个说的过去的理论基础,然后在这个基础上推导出最大似然函数,接着构建损失函数。这对于非数学专业的人来说,用途并不大,有时候甚至会造成理解上的困难,进而变成学习的阻碍。其实,我们完全可以绕过这个阻碍,只去关注最后的结果。
3.求解方式
1)使用梯度下降法求解
经过一系列推导之后,得出梯度下降法求解的核心公式,即权重的更新方式:
(公式七)
需要说明的是:α表示下降的步长,可以自己指定。hθ 表示损失函数或者惩罚系数。如果hθ 表示惩罚系数,那么如何求的这组系数才是整个逻辑回归算法的重点。
在开始写代码前,再介绍另外一个求解方式:向量化
2)向量化
向量化是使用矩阵计算来代替for循环,以简化计算过程,提高效率。(下面引用下其他文章的讲解:出现的地方太多不知道哪个是原作者,见谅)
向量化过程:
约定训练数据的矩阵形式如下,x的每一行为一条训练样本,而每一列为不同的特称取值:
g(A)的参数A为一列向量,所以实现g函数时要支持列向量作为参数,并返回列向量。
θ更新过程可以改为:
综上所述,向量化后θ更新的步骤如下:
a)求 A=x*θ
b)求 E=g(A)-y
c)求
4.实现过程(下面的代码实现的是梯度上升法,其跟梯度下降法的唯一区别就是
和
之间的减号变成了加号,前者求最大值,后者求最小值)
代码基本脱胎于《机器学习实战》这本书,但是有改动。
1)普通的梯度上升法
下面这段代码,也就是开头提到的那个造成误解的代码,其实现依据是向量化求解,并不是根据公式七来的,所以如果对照公式七理解这段代码会完全摸不着头脑。如果对照向量化后θ(也就是权重)的更新步骤会很容易理解。
''' 普通的梯度上升法 ''' import numpy as np import os import pandas as pd def loadDataSet(): ##运行脚本所在目录 base_dir=os.getcwd() ##记得添加header=None,否则会把第一行当作头 data=pd.read_table(base_dir+r"\lr.txt",header=None) ##dataLen行dataWid列 :返回值是dataLen=100 dataWid=3 dataLen,dataWid = data.shape ##训练数据集 xList = [] ##标签数据集 lables = [] ##读取数据 for i in range(dataLen): row = data.values[i] xList.append(row[0:dataWid-1]) lables.append(row[-1]) return xList,lables ##逻辑函数 def sigmoid(inX): return 1.0/(1+np.exp(-inX)) ##梯度上升函数 def gradAscent(datamatIn,classLables): ##把datamatIn从列表转换成矩阵 dataMatrix = np.mat(datamatIn) ##把列表转换成100行1列的矩阵,而np.mat(classLables)是转换成1行100列的矩阵 labelMat = np.mat(classLables).transpose() ##求矩阵的长宽 m,n = np.shape(dataMatrix) ##步长,可以自己设置 alpha = 0.001 ##最大循环次数 maxTry = 500 ##初始化向量:2行1列的矩阵 weights =np.ones((n,1)) ##循环一定次数,求权重 for k in range(maxTry): ##dataMatrix 100行2列 weights是2行1列 ##h是100行1列 h = sigmoid(dataMatrix*weights) ##向量的偏差 error = (labelMat - h) ##dataMatrix.transpose() 转换成2行100列的矩阵 ##error 是100行1列 ##weights是2行1列的值 weights = weights + alpha*dataMatrix.transpose()*error return weights ''' 结果大于0.3的设置为1,正确率基本100% ''' def GetResult(): dataMat,labelMat=loadDataSet() weights=gradAscent(dataMat,labelMat) dataMatrix = np.mat(dataMat) ##求的最后的结果 h = sigmoid(dataMatrix*weights) ##打印结果,观察数据 for i in range(len(h)): print(str(h[i])+":"+str(labelMat[i])) #print(h) #print(weights) ##0.08108752 -0.1233496 if __name__=='__main__': GetResult()
2)随机梯度上升发
这个算法,才是符合公式七的算法,但是代码中并没有
求和这步,只有括号中的那部分,这也是我开头说的三者之间必有一个错误的地方。
只包括核心部分,其他部分见上段代码
''' 结果大于0.29或者0.26都可以,也只有1-2个分类错误 weights:[ 0.0868611 -0.13086297] ''' ##随机梯度上升算法 def gradAscent(datamatIn,classLables): m,n = np.shape(datamatIn) ##步长,可以自己指定,决定收敛速度 alpha = 0.001 ##最大循环次数 maxTry = 200 ##初始化权重:列表而不是矩阵 weights =np.ones(n) ##循环求解:在整个数据集上循环 for k in range(maxTry): ##对每行进行处理 for i in range(m): ##每行向量化 h = sigmoid(sum(datamatIn[i]*weights)) ##每行向量偏差 error = (classLables[i] - h) ##更新权重 weights = weights +alpha*error*datamatIn[i] return weights ##打印结果 def GetResult(): dataMat,labelMat=loadDataSet() weights=gradAscent(dataMat,labelMat) m,n = np.shape(dataMat) for i in range(m): h = sigmoid(sum(dataMat[i]*weights)) print(str(h)+" : "+str(labelMat[i])) #print(weights)
3)改进的随机梯度上升算法
书中还讲到了一个改进的随机梯度上升算法。
##随机梯度上升函数 def gradAscent(datamatIn,classLables): m,n = np.shape(datamatIn) ##循环次数 maxTry = 150 ##初始化权重:列表 weights =np.ones(n) ##循环求解 for j in range(maxTry): ##在整个数据集上循环 for i in range(m): ##跟新alpha,即跟新步长值 alpha = 4/(1.0+j+i)+0.01 ##随机抽取一个下标 randIndex = int(np.random.uniform(0,m)) ##对抽到下标的数据行进行求值 h = sigmoid(sum(datamatIn[randIndex]*weights)) ##求得误差值 error = classLables[randIndex] - h ##更新权重 weights = weights +alpha*error*datamatIn[randIndex] return weights
该算法每次都会调整步长值,即缓解了随着循环次数的增加造成的特征值的波动,也保证了当j<<max(i)时,步长值的下降不是严格下降的。而避免参数的严格下降在优化退火算法中常常用到。
5.使用sklearn包中的逻辑回归算法(非完整代码,缺少部分在第一个代码段)
sklearn包中的LogisticRegression函数,默认使用L2正则化防止过度拟合。
from sklearn.linear_model import LogisticRegression
def sk_lr(X_train,y_train):
model = LogisticRegression()
model.fit(X_train, y_train)
model.score(X_train,y_train)
#print('权重',model.coef_)
return model.predict(X_train)
##分类错了2个
def GetResult():
dataMat,labelMat=loadDataSet()
pred = sk_lr(dataMat,labelMat)
for i in range(len(pred)):
print(str(pred[i])+" : "+str(labelMat[i]))
if __name__=='__main__':
GetResult()最后得出的预测结果就是0,1值,跟标签对比,有两个分类错了。
6.逻辑回归优缺点
优点:计算代价不高,易于理解和实现
缺点:容易欠拟合,分类精度可能不高
适用数据类型:数值型和标称型数据
附录:测试数据
View Code

相关文章推荐
- 从编程的角度去理解逻辑回归
- 机器学习:从编程的角度去理解逻辑回归
- 机器学习:从编程的角度去理解逻辑回归
- IT第七天 - 类及其属性、方法的理解,断点调试初识,代码优化总结,编程逻辑培养
- Coursera机器学习 week3 逻辑回归 编程作业代码
- 对于《机器学习实战》中逻辑斯谛回归算法公式理解
- 【机器学习】线性回归和逻辑回归的理解
- (理解)线性回归, 逻辑回归和线性分类器,Softmax回归。
- [Step By Step]SAP HANA PAL逻辑回归预测分析Logistic Regression编程实例LOGISTICREGRESSION(模型)
- 01 逻辑回归的理解
- 逻辑回归、决策树和支持向量机的直观理解
- stanford coursera 机器学习编程作业 exercise 3(逻辑回归实现多分类问题)
- 理解逻辑斯蒂回归模型
- 逻辑回归算法之交叉熵函数理解
- 以程序员编程的角度去理解笛卡尔积
- 逻辑回归 S函数 极大似然 这三者的理解 结合具体案例
- 机器学习(四)从信息论交叉熵的角度看softmax/逻辑回归损失
- 逻辑回归_梯度跟新公式的理解
- 从编程的角度理解gradle脚本﹘﹘Android Studio脚本构建和编程
- 从编程的角度理解gradle脚本﹘﹘Android Studio脚本构建和编程[魅族Degao]