ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
2017-05-07 11:03
1341 查看
原文:http://tchuairen.blog.51cto.com/3848118/1861167?utm_source=tuicool&utm_medium=referral
什么要做日志分析平台?
随着业务量的增长,每天业务服务器将会产生上亿条的日志,单个日志文件达几个GB,这时我们发现用Linux自带工具,cat grep awk 分析越来越力不从心了,而且除了服务器日志,还有程序报错日志,分布在不同的服务器,查阅繁琐。
待解决的痛点:
1、大量不同种类的日志成为了运维人员的负担,不方便管理;
2、单个日志文件巨大,无法使用常用的文本工具分析,检索困难;
3、日志分布在多台不同的服务器上,业务一旦出现故障,需要一台台查看日志。
为了解决以上困扰:
接下来我们要一步步构建这个日志分析平台,架构图如下:
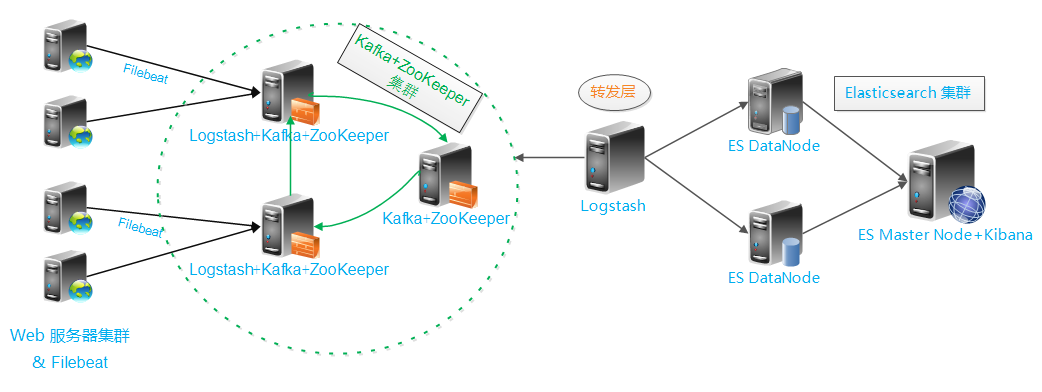
架构解读 : (整个架构从左到右,总共分为5层)
第一层、数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务。
第二层、数据处理层,数据缓存层
logstash服务把接受到的日志经过格式处理,转存到本地的kafka broker+zookeeper 集群中。
第三层、数据转发层
这个单独的Logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode。
第四层、数据持久化存储
ES DataNode 会把收到的数据,写磁盘,建索引库。
第五层、数据检索,数据展示
ES Master + Kibana 主要协调ES集群,处理数据检索请求,数据展示。
笔者为了节约宝贵的服务器资源,把一些可拆分的服务合并在同一台主机。大家可以根据自己的实际业务环境自由拆分,延伸架构。
开 工 !
操作系统环境 : CentOS release 6.5
各服务器角色分配 :
软件包版本:
jdk-8u101-linux-x64.rpm
logstash-2.3.2.tar.gz
filebeat-1.2.3-x86_64.rpm
kafka_2.11-0.10.0.1.tgz
zookeeper-3.4.9.tar.gz
elasticsearch-2.3.4.rpm
kibana-4.5.3-linux-x64.tar.gz
一、安装部署Elasticsearch集群
布置ES Master节点 10.10.1.244
1、安装jdk1.8,elasticsearch-2.3.4
oracle官网 jdk 下载地址: http://www.oracle.com/technetwork/java/javase/downloads/index.html
elasticsearch 官网: https://www.elastic.co/
2、系统调优,JVM调优
3、编写ES Master节点配置文件
注: path.data、path.logs 这两个参数指定的路径,如果没有需要自己创建,还要赋予权限给elasticsearch用户。(后面的ES DataNode也同样)
4、安装head、kopf、bigdesk 开源插件
安装方法有两种 :
1、使用ES自带的命令plugin
2、自行下载插件的源码包安装
我们通过plugin命令安装的插件,其实是安装到了这个路径:/usr/share/elasticsearch/plugins
而plugin install 命令后面跟的这一串 mobz/elasticsearch-head 其实是github上的一个地址。
前面加上github的官网地址就是 https://github.com/mobz/elasticsearch-head 可以复制到浏览器中打开,找到该插件的源码仓库。
现在知道了,想要找插件自己可以去github上搜一下出来一大堆。随便选一个然后取后面那串路径,用ES自带的命令安装。
如果安装失败了,那么就手动下载该插件的源码包。 解压后直接整个目录mv到 ES 的插件安装路径下。
也就是这里: /usr/share/elasticsearch/plugins/
那如何访问安装好的插件呢?
http://ES_server_ip:port/_plugin/plugin_name
Example:
http://127.0.0.1:9200/_plugin/head/ http://127.0.0.1:9200/_plugin/kopf/
这时,ES Master已经配置好了。
布置ES DataNode节点 10.10.1.60
安装和系统调优方法同上,插件不用安装,只是配置文件不同。
编写配置文件
10.10.1.60 也准备好了。
布置另一台ES DataNode节点 10.10.1.90
编写配置文件
5、现在三台ES节点已经准备就绪,分别启动服务
6、访问head插件,查看集群状态
此时 Elasticsearch 集群已经准备完成
二、配置位于架构图中第二层的ZooKeeper集群
配置 10.10.1.30 节点
1、安装,配置 zookeeper
zookeeper官网: http://zookeeper.apache.org/
编写配置文件
同步配置文件到其他两台节点
注: zookeeper 集群,每个节点的配置文件都是一样的。所以直接同步过去,不需要做任何修改。
不熟悉zookeeper的朋友,可以参考这里: http://tchuairen.blog.51cto.com/3848118/1859494
2、创建myid文件
3、启动服务 & [b]查看节点状态[/b]
此时zookeeper集群配置完成
三、配置位于架构图中第二层的Kafka Broker集群
Kafka官网: http://kafka.apache.org/
不熟悉Kafka的朋友可以参考: http://tchuairen.blog.51cto.com/3848118/1855090
配置 10.10.1.30 节点
1、安装,配置 kafka
编写配置文件
注: 其他两个节点的配置文件也基本相同,只有一个参数需要修改 broker.id 。 它用于唯一标识节点,所以绝对不能相同,不然会节点冲突。
同步配置文件到其他两台节点
2、配置主机名对应IP的解析
3、启动服务
Kafka+ZooKeeper集群配置完成
四、配置位于架构图中第二层的Logstash服务
配置 10.10.1.30 节点
1、安装,配置 logstash
配置 GeoLiteCity , 用于地图显示IP访问的城市
官网地址: http://dev.maxmind.com/geoip/legacy/geolite/
下载地址: http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz
解压
gunzip GeoLiteCity.dat.gz
编写配置文件
2、启动服务
10.10.1.31 节点的这块配置,与上述完全相同。(略)
位于第二层、数据处理层的 Logstash 配置完成
五、配置数据采集层,业务服务器+Filebeat
1、定制Nginx日志格式
2、安装 Filebeat
Filebeat 也是 Elasticsearch 公司的产品,在官网可以下载。
3、编写 Filebeat 配置文件
4、启动服务
数据采集层,Filebeat配置完成。
现在业务服务器上的日志数据已经在源源不断的写入缓存了。
六、配置位于架构图中的第三层,数据转发层
Logstash安装上面已经讲过(略)
编写Logstash配置文件
启动服务
数据转发层已经配置完成
这时数据已经陆陆续续的从kafka取出,转存到ES DataNode。
我们登陆到任意一台kafka主机,查看数据的缓存和消费情况

七、修改ES的索引模版配置
为什么要做这一步呢? 因为logstash写入数据到ES时,会自动选用一个索引模版。 我们可以看一下
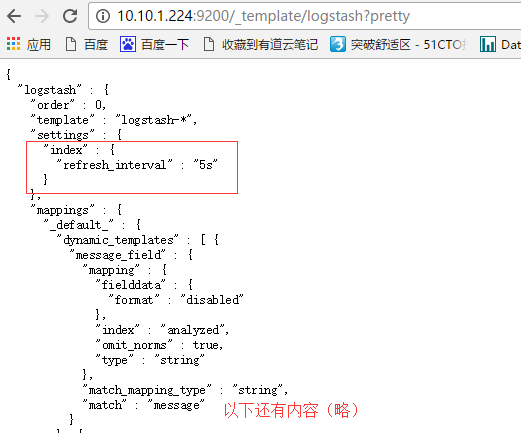
这个模版其实也挺好,不过有一个参数,我标记出来了。 "refresh_interval":"5s" 这个参数用于控制,索引的刷新频率。 索引的刷新频率越快,你搜索到的数据就实时。 这里是5秒。 一般我们日志场景不需要这么高的实时性。 可以适当降低该参数,提高ES 索引库的写入速度。
上传自定义模版
由于这个自定义模版,我把优先级 order 定义的比logstash模版高,而模版的匹配规则又一样,所以这个自定义模版的配置会覆盖原logstash模版。
我这里只是简单描述。 如果要详细理解其中道理,请查看我的 ES 调优篇。
八、配置 Kibana 数据展示层
10.10.1.244 节点
Kibana是ELK套件中的一员,也属于elasticsearch 公司,在官网提供下载。
安装
修改配置文件
启动服务

打开浏览器访问: http://10.10.1.244:5601/
定制 Elasticsearch 索引的 Index pattern
默认情况下,Kibana认为你要访问的是通过Logstash导入Elasticsearch的数据,这时候你可以用默认的 logstash-* 作为你的 index pattern。 通配符(*)匹配索引名中任意字符任意个数。
选择一个包含了时间戳的索引字段(字段类型为 date 的字段),可以用来做基于时间的处理。Kibana 会读取索引的
映射,然后列出所有包含了时间戳的字段。如果你的索引没有基于时间的数据.
关闭 Index contains time-based events 参数。
如果一个新索引是定期生成,而且索引名中带有时间戳,选择 Use event times to create index names 选项,
然后再选择 Index pattern interval 。这可以提高搜索性能,Kibana 会至搜索你指定的时间范围内的索引。在你用 Logstash 输出数据给Elasticsearch 的情况下尤其有效。
由于我们的索引是用日期命名,按照每天分割的。 index pattern 如下
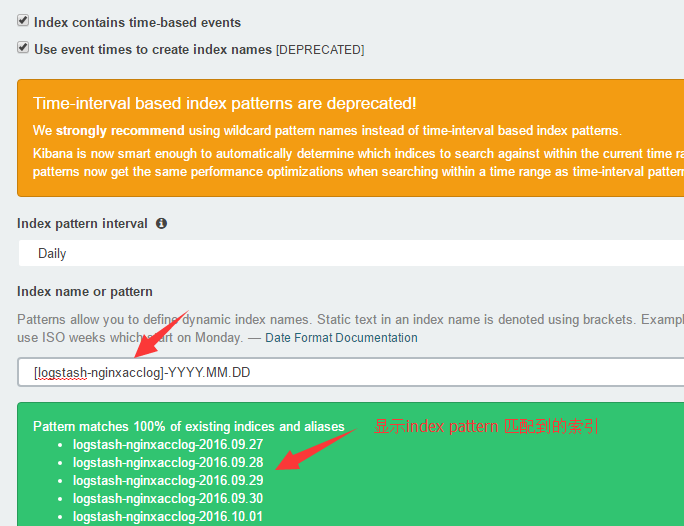
数据展示
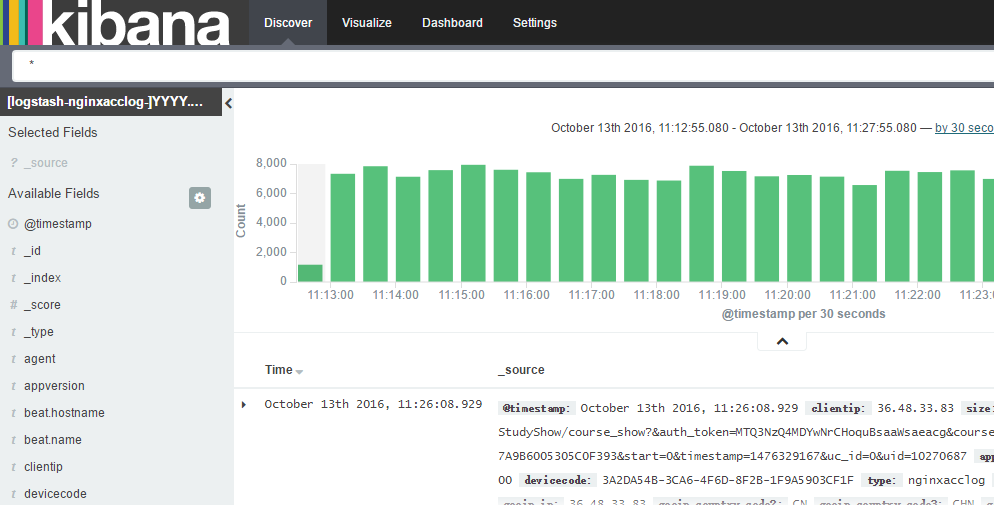
完 工 !
什么要做日志分析平台?
随着业务量的增长,每天业务服务器将会产生上亿条的日志,单个日志文件达几个GB,这时我们发现用Linux自带工具,cat grep awk 分析越来越力不从心了,而且除了服务器日志,还有程序报错日志,分布在不同的服务器,查阅繁琐。
待解决的痛点:
1、大量不同种类的日志成为了运维人员的负担,不方便管理;
2、单个日志文件巨大,无法使用常用的文本工具分析,检索困难;
3、日志分布在多台不同的服务器上,业务一旦出现故障,需要一台台查看日志。
为了解决以上困扰:
接下来我们要一步步构建这个日志分析平台,架构图如下:
架构解读 : (整个架构从左到右,总共分为5层)
第一层、数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务。
第二层、数据处理层,数据缓存层
logstash服务把接受到的日志经过格式处理,转存到本地的kafka broker+zookeeper 集群中。
第三层、数据转发层
这个单独的Logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode。
第四层、数据持久化存储
ES DataNode 会把收到的数据,写磁盘,建索引库。
第五层、数据检索,数据展示
ES Master + Kibana 主要协调ES集群,处理数据检索请求,数据展示。
笔者为了节约宝贵的服务器资源,把一些可拆分的服务合并在同一台主机。大家可以根据自己的实际业务环境自由拆分,延伸架构。
开 工 !
操作系统环境 : CentOS release 6.5
各服务器角色分配 :
| IP | 角色 | 所属集群 |
| 10.10.1.2 | 业务服务器+filebeat | 业务服务器集群 |
| 10.10.1.30 | Logstash+Kafka+ZooKeeper | Kafka Broker 集群 |
| 10.10.1.31 | Logstash+Kafka+ZooKeeper | |
| 10.10.1.32 | Kafka+ZooKeeper | |
| 10.10.1.50 | Logstash | 数据转发 |
| 10.10.1.60 | ES DataNode | Elasticsearch 集群 |
| 10.10.1.90 | ES DataNode | |
| 10.10.1.244 | ES Master+Kibana |
jdk-8u101-linux-x64.rpm
logstash-2.3.2.tar.gz
filebeat-1.2.3-x86_64.rpm
kafka_2.11-0.10.0.1.tgz
zookeeper-3.4.9.tar.gz
elasticsearch-2.3.4.rpm
kibana-4.5.3-linux-x64.tar.gz
一、安装部署Elasticsearch集群
布置ES Master节点 10.10.1.244
1、安装jdk1.8,elasticsearch-2.3.4
oracle官网 jdk 下载地址: http://www.oracle.com/technetwork/java/javase/downloads/index.html
elasticsearch 官网: https://www.elastic.co/
4、安装head、kopf、bigdesk 开源插件
安装方法有两种 :
1、使用ES自带的命令plugin
我们通过plugin命令安装的插件,其实是安装到了这个路径:/usr/share/elasticsearch/plugins
而plugin install 命令后面跟的这一串 mobz/elasticsearch-head 其实是github上的一个地址。
前面加上github的官网地址就是 https://github.com/mobz/elasticsearch-head 可以复制到浏览器中打开,找到该插件的源码仓库。
现在知道了,想要找插件自己可以去github上搜一下出来一大堆。随便选一个然后取后面那串路径,用ES自带的命令安装。
如果安装失败了,那么就手动下载该插件的源码包。 解压后直接整个目录mv到 ES 的插件安装路径下。
也就是这里: /usr/share/elasticsearch/plugins/
那如何访问安装好的插件呢?
http://ES_server_ip:port/_plugin/plugin_name
Example:
http://127.0.0.1:9200/_plugin/head/ http://127.0.0.1:9200/_plugin/kopf/
这时,ES Master已经配置好了。
布置ES DataNode节点 10.10.1.60
安装和系统调优方法同上,插件不用安装,只是配置文件不同。
编写配置文件
布置另一台ES DataNode节点 10.10.1.90
编写配置文件
此时 Elasticsearch 集群已经准备完成
二、配置位于架构图中第二层的ZooKeeper集群
配置 10.10.1.30 节点
1、安装,配置 zookeeper
zookeeper官网: http://zookeeper.apache.org/
注: zookeeper 集群,每个节点的配置文件都是一样的。所以直接同步过去,不需要做任何修改。
不熟悉zookeeper的朋友,可以参考这里: http://tchuairen.blog.51cto.com/3848118/1859494
三、配置位于架构图中第二层的Kafka Broker集群
Kafka官网: http://kafka.apache.org/
不熟悉Kafka的朋友可以参考: http://tchuairen.blog.51cto.com/3848118/1855090
配置 10.10.1.30 节点
1、安装,配置 kafka
同步配置文件到其他两台节点
四、配置位于架构图中第二层的Logstash服务
配置 10.10.1.30 节点
1、安装,配置 logstash
官网地址: http://dev.maxmind.com/geoip/legacy/geolite/
下载地址: http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz
解压
gunzip GeoLiteCity.dat.gz
编写配置文件
位于第二层、数据处理层的 Logstash 配置完成
五、配置数据采集层,业务服务器+Filebeat
1、定制Nginx日志格式
Filebeat 也是 Elasticsearch 公司的产品,在官网可以下载。
现在业务服务器上的日志数据已经在源源不断的写入缓存了。
六、配置位于架构图中的第三层,数据转发层
Logstash安装上面已经讲过(略)
编写Logstash配置文件
这时数据已经陆陆续续的从kafka取出,转存到ES DataNode。
我们登陆到任意一台kafka主机,查看数据的缓存和消费情况
七、修改ES的索引模版配置
为什么要做这一步呢? 因为logstash写入数据到ES时,会自动选用一个索引模版。 我们可以看一下
这个模版其实也挺好,不过有一个参数,我标记出来了。 "refresh_interval":"5s" 这个参数用于控制,索引的刷新频率。 索引的刷新频率越快,你搜索到的数据就实时。 这里是5秒。 一般我们日志场景不需要这么高的实时性。 可以适当降低该参数,提高ES 索引库的写入速度。
上传自定义模版
我这里只是简单描述。 如果要详细理解其中道理,请查看我的 ES 调优篇。
八、配置 Kibana 数据展示层
10.10.1.244 节点
Kibana是ELK套件中的一员,也属于elasticsearch 公司,在官网提供下载。
安装
打开浏览器访问: http://10.10.1.244:5601/
定制 Elasticsearch 索引的 Index pattern
默认情况下,Kibana认为你要访问的是通过Logstash导入Elasticsearch的数据,这时候你可以用默认的 logstash-* 作为你的 index pattern。 通配符(*)匹配索引名中任意字符任意个数。
选择一个包含了时间戳的索引字段(字段类型为 date 的字段),可以用来做基于时间的处理。Kibana 会读取索引的
映射,然后列出所有包含了时间戳的字段。如果你的索引没有基于时间的数据.
关闭 Index contains time-based events 参数。
如果一个新索引是定期生成,而且索引名中带有时间戳,选择 Use event times to create index names 选项,
然后再选择 Index pattern interval 。这可以提高搜索性能,Kibana 会至搜索你指定的时间范围内的索引。在你用 Logstash 输出数据给Elasticsearch 的情况下尤其有效。
由于我们的索引是用日期命名,按照每天分割的。 index pattern 如下
数据展示
完 工 !

相关文章推荐
- ELK+filebeat+kafka+zookeeper构建海量日志分析平台
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台(elk5.2+filebeat2.11)
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台 推荐
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
- ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
- ELK+FILEBEAT+KAFKA+ZOOKEEPER日志管理分析平台
- ELK实时日志分析平台(elk+kafka+metricbeat)-logstash(四)
- elk6.3.1+zookeeper+kafka+filebeat收集dockerswarm容器日志
- ELK实时日志分析平台(elk+kafka+metricbeat)-metricbeat(三)
- ELK实时日志分析平台(elk+kafka+metricbeat)-kibana部署(六)
- ELK实时日志分析平台(elk+kafka+metricbeat)-搭建说明(一)
- ELK实时日志分析平台(elk+kafka+metricbeat)-KAFKA(二)
- ELK实时日志分析平台(elk+kafka+metricbeat)-elasticsearch部署(五)
- ELK+Filebeat搭建实时日志分析平台
- 24.ELK实时日志分析平台之Filebeat介绍及安装方法
- 6.3.1版本elk+redis+filebeat收集docker+swarm日志分析
- Filebeat+ELK搭建日志实时分析系统
- 海量可视化日志分析平台之ELK搭建
- ELK-filebeat+kafka日志收集
- 海量可视化日志分析平台之ELK搭建