Hadoop(三) 大数据离线计算与实时计算
2017-05-05 20:07
260 查看
一、大数据离线计算:MapReduce计算模型
1、MapReduce是处理HDFS上的数据2、MapReduce的思想来源是PageRank(搜索排名),原理是进行分布式计算。

如上图,网页跳转中,访问网页3的次数最多,也就是权重最大的为网页3。比如京东、淘宝中给推荐的商品,就是近期访问的比较多的商品。
MapReduce的思想是把一个大任务拆分成多个小任务,再把小任务的结果汇总,得到最后的结果。
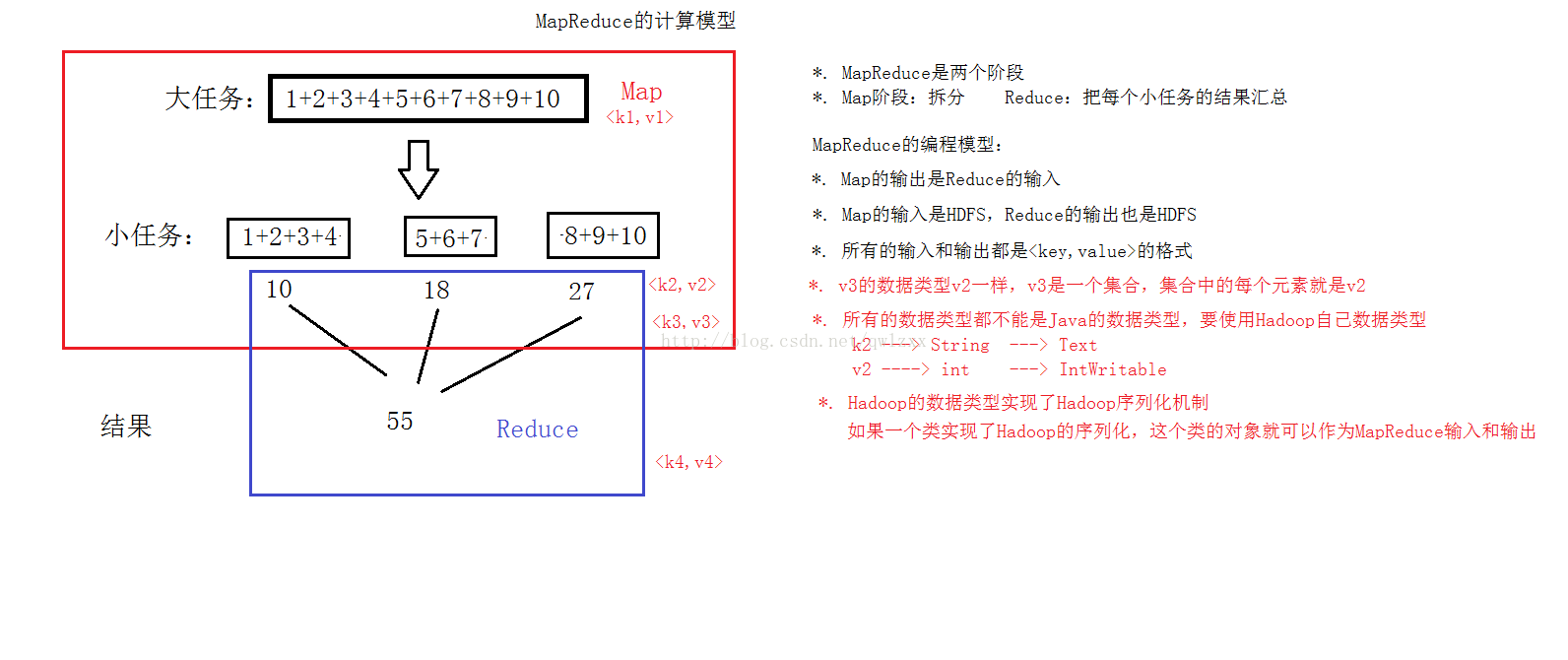
3、数据都是历史数据、数据已经存在(HDFS)
二、大数据实时计算:Apache Storm
1、特点:数据源源不断地产生,不停处理数据2、例子:自来水厂
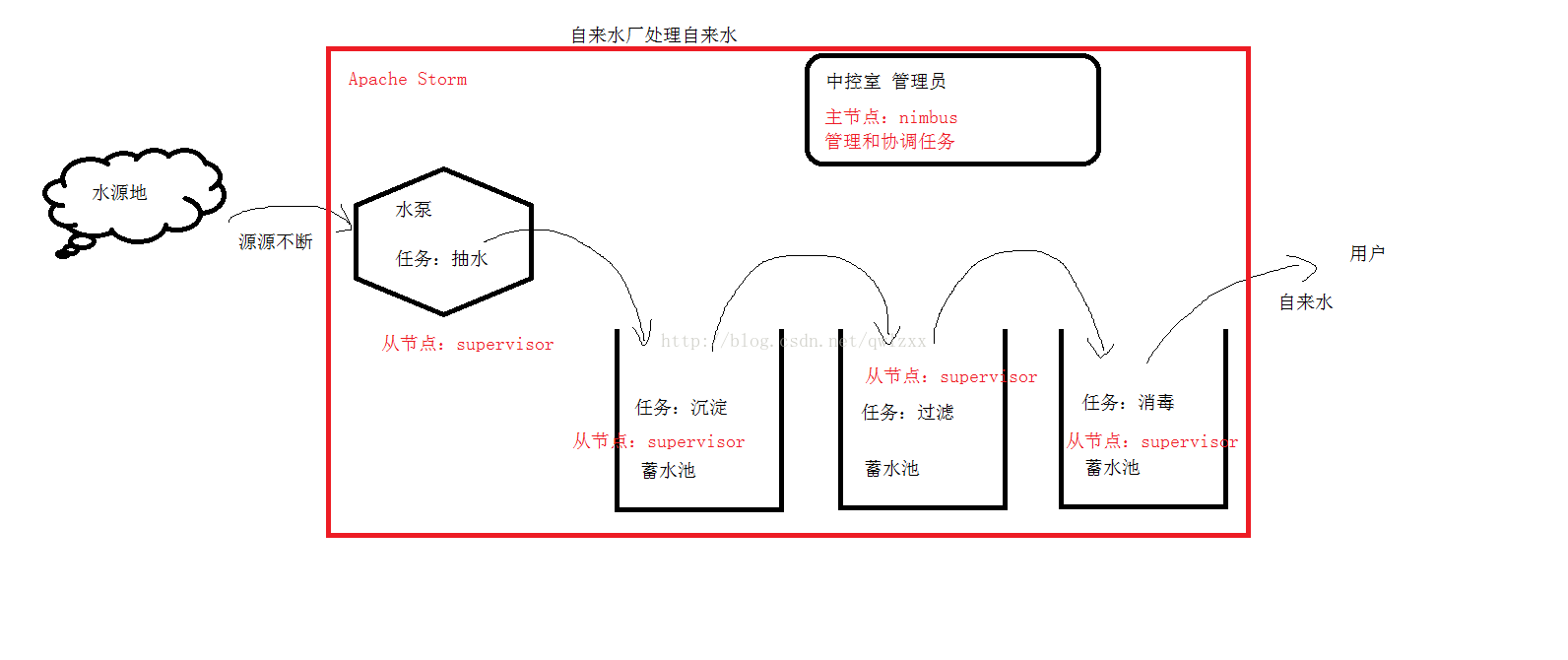
3、框架:Apache Storm、Spark Streaming
4、格式:storm jar jar文件 任务的类名 任务的别名
storm jar storm-starter-topologies-1.0.3.jar.jar org.apache.storm.starter.WordCountTopology MyWC
三、搭建Hadoop的Eclipse开发环境(不推荐)
1、配置Hadoop Home2、hadoop.dll复制到c:\windows\system32
3、配置环境变量
HADOOP_HOME
%HADOOP_HOME%/bin配置到PATH里
4、推荐:MRUnit(MapReduce Unit),类似Junit
小结
对Hadoop的认识只停留在理论上,更多的操作在精力和时间的允许下有待实践。
相关文章推荐
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
- HADOOP大数据离线分析+实时分析框架;Hadoop+Flume+Kafka+Storm+Hive+Sqoop+mysql/oracle
- 大数据实时计算工程师/Hadoop工程师/数据分析师职业路线图
- 性能优化之永恒之道(1)(实时sql优化vs业务字段冗余vs离线计算)
- 梳理一下流式处理、实时计算、Add-hoc、离线计算、实时查询等区别
- 【转】百亿级实时大数据分析项目,为什么不用Hadoop?
- Spark视频第1期:Spark亚太研究院决胜云计算大数据时代:100期Spark公益大讲堂之革命Hadoop Spark把云计算大数据速度提高100倍以上
- 流式处理、实时计算、Add-hoc、离线计算、实时查询等区别
- Hadoop平台提供离线数据和Storm平台提供实时数据流
- 大数据入门第五天——离线计算之hadoop(下)hadoop-shell与HDFS的JavaAPI入门
- [置顶] HADOOP大数据离线分析+实时分析框架;Hadoop+Flume+Kafka+Storm+Hive+Sqoop+mysql/oracle
- Hadoop分布式计算——克服大数据挑战的曙光
- 大数据入门第五天——离线计算之hadoop(上)概述与集群安装
- Hadoop大数据离线项目的运行流程图
- 实时计算与odps离线计算
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 一共81个,开源大数据处理工具汇总:查询引擎、流式计算、迭代计算、离线计算、键值存储、表格存储、文件存储、资源管理、日志收集系统、消息系统、分布式服务、集群管理、基础设施、搜索引擎、数据挖掘=监控
- 100亿小数据实时计算平台(大数据系列目录)
- 大数据时代之hadoop(五):hadoop 分布式计算框架(MapReduce)
- 离线计算,实时计算和流式计算的概念区分