python爬取数据并将其存入mongodb
2017-05-05 16:42
134 查看
其实很早就想知道如何将爬取到的数据存入数据库,并且实现前后台的交互功能,昨天刚刚看了一集关于爬数据并存数据的视频,今天,在这里总结一下~

以下为最终所需要爬取的信息:
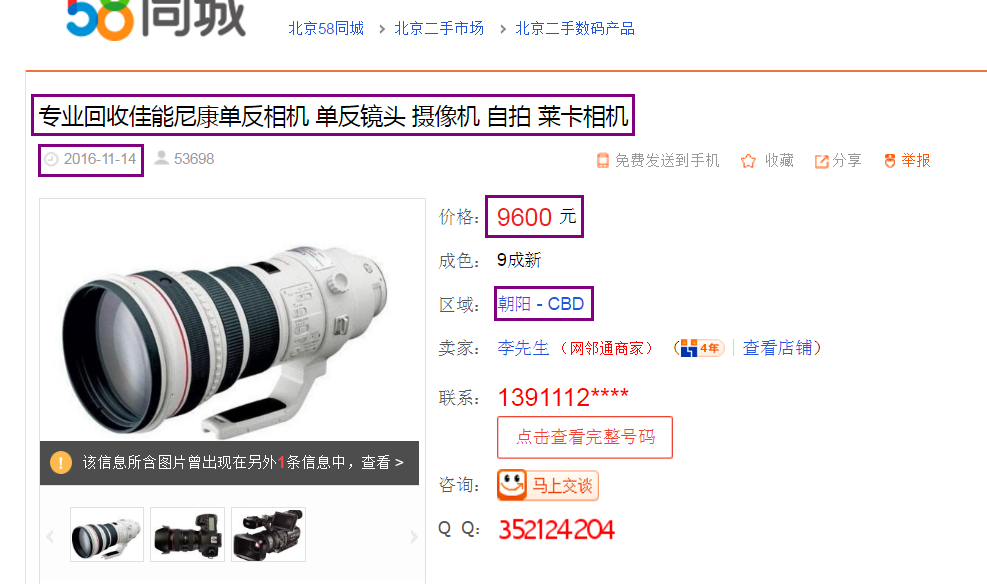
由于需要爬取所有的二手商品信息,所以以下内容也要爬取到:
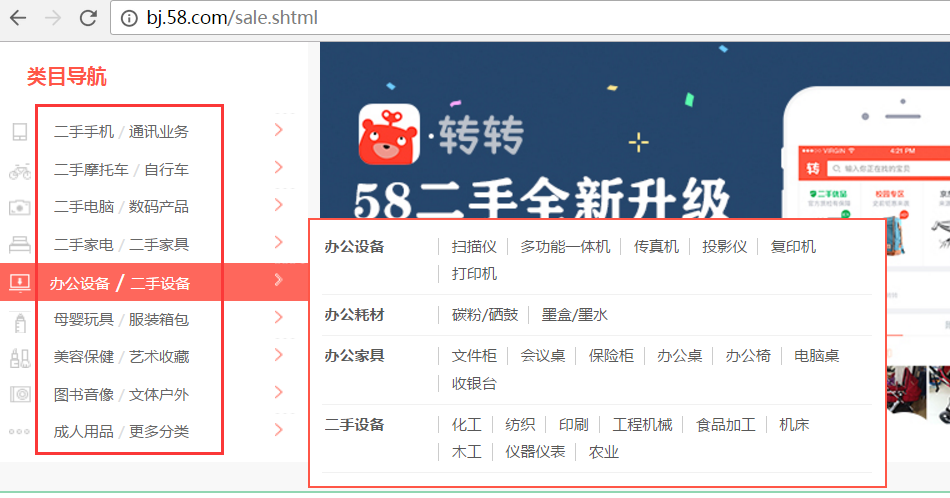
1.先写一个py文件,用于爬取上述图片类目导航的各个链接:
#-*-coding:utf-8-*-
from bs4 import BeautifulSoup
import requests
start_url = 'http://bj.58.com/sale.shtml'
url_host = 'http://bj.58.com'
def get_channel_urls(url):
wb_data = requests.get(start_url)
soup = BeautifulSoup(wb_data.text,'html.parser')
links = soup.select('ul.ym-submnu > li > b > a')
for link in links:
page_url = url_host + link.get('href')
print page_url
get_channel_urls(start_url)
#类目导航链接
channel_list = ''' http://bj.58.com/shouji/ http://bj.58.com/tongxunyw/ http://bj.58.com/danche/ http://bj.58.com/fzixingche/ http://bj.58.com/diandongche/ http://bj.58.com/sanlunche/ http://bj.58.com/peijianzhuangbei/ http://bj.58.com/diannao/ http://bj.58.com/bijiben/ http://bj.58.com/pbdn/ http://bj.58.com/diannaopeijian/ http://bj.58.com/zhoubianshebei/ http://bj.58.com/shuma/ http://bj.58.com/shumaxiangji/ http://bj.58.com/mpsanmpsi/ http://bj.58.com/youxiji/ http://bj.58.com/jiadian/ http://bj.58.com/dianshiji/ http://bj.58.com/ershoukongtiao/ http://bj.58.com/xiyiji/ http://bj.58.com/bingxiang/ http://bj.58.com/binggui/ http://bj.58.com/chuang/ http://bj.58.com/ershoujiaju/ http://bj.58.com/bangongshebei/ http://bj.58.com/diannaohaocai/ http://bj.58.com/bangongjiaju/ http://bj.58.com/ershoushebei/ http://bj.58.com/yingyou/ http://bj.58.com/yingeryongpin/ http://bj.58.com/muyingweiyang/ http://bj.58.com/muyingtongchuang/ http://bj.58.com/yunfuyongpin/ http://bj.58.com/fushi/ http://bj.58.com/nanzhuang/ http://bj.58.com/fsxiemao/ http://bj.58.com/xiangbao/ http://bj.58.com/meirong/ http://bj.58.com/yishu/ http://bj.58.com/shufahuihua/ http://bj.58.com/zhubaoshipin/ http://bj.58.com/yuqi/ http://bj.58.com/tushu/ http://bj.58.com/tushubook/ http://bj.58.com/wenti/ http://bj.58.com/yundongfushi/ http://bj.58.com/jianshenqixie/ http://bj.58.com/huju/ http://bj.58.com/qiulei/ http://bj.58.com/yueqi/ http://bj.58.com/chengren/ http://bj.58.com/nvyongpin/ http://bj.58.com/qinglvqingqu/ http://bj.58.com/qingquneiyi/ http://bj.58.com/chengren/ http://bj.58.com/xiaoyuan/ http://bj.58.com/ershouqiugou/ http://bj.58.com/tiaozao/ http://bj.58.com/tiaozao/ http://bj.58.com/tiaozao/
'''
2.建立另一个py文件,用于爬取商品信息:
from bs4 import BeautifulSoup
import requests
import time
import pymongo
client = pymongo.MongoClient()
ceshi = client['ceshi']
url_list = ceshi['url_list3']
item_info = ceshi['item_info3']
def get_links_from(channel,pages,who_sells=0):
list_view = '{}{}/pn{}'.format(channel,str(who_sells),str(pages))
wb_data = requests.get(list_view)
time.sleep(1)
soup = BeautifulSoup(wb_data.text,'html.parser')
if soup.find('td','t'):
for link in soup.select('td.t a.t'):
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url':item_link})
print item_link
else:
pass
def get_item_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'html.parser')
no_longer_exist = '404' in soup.find('script',type="text/javascript").get('src').split('/')
if no_longer_exist:
pass
else:
title = soup.title.text
price = soup.select('span.price.c_f50')[0].text
date = soup.select('.time')[0].text
area = list(soup.select('.c_25d a')[0].stripped_strings) if soup.find_all('span','c_25d') else None
item_info.insert_one({'title':title,'price':price,'date':date,'area':area})
print({'title':title,'price':price,'date':date,'area':area})
get_item_info('http://bj.58.com/shuma/28049255291945x.shtml')
#get_links_from('http://bj.58.com/shuma/',2)
在第二个py文件中,需要注意的是:
1.连接mongodb时,可以不用提前在mongovue中建立数据库和collection,它会自动创建。
2.定义的第一个函数是用来爬取每个商品的具体url,并将其存入mongodb,第二个函数是通过每个商品具体的url来爬取相应的商品信息,并存入数据库,这两个函数不能同时运行。
3.在这次的爬虫项目中,有好多爬取技巧,如:
links = soup.select('ul.ym-submnu > li > b > a')
等等,嘻嘻,反正这些我感觉比较新颖~~
最后,将数据存入数据库其实就是在连接数据库时,代码中有插入语句,就行~~
展示一下数据库中结果:
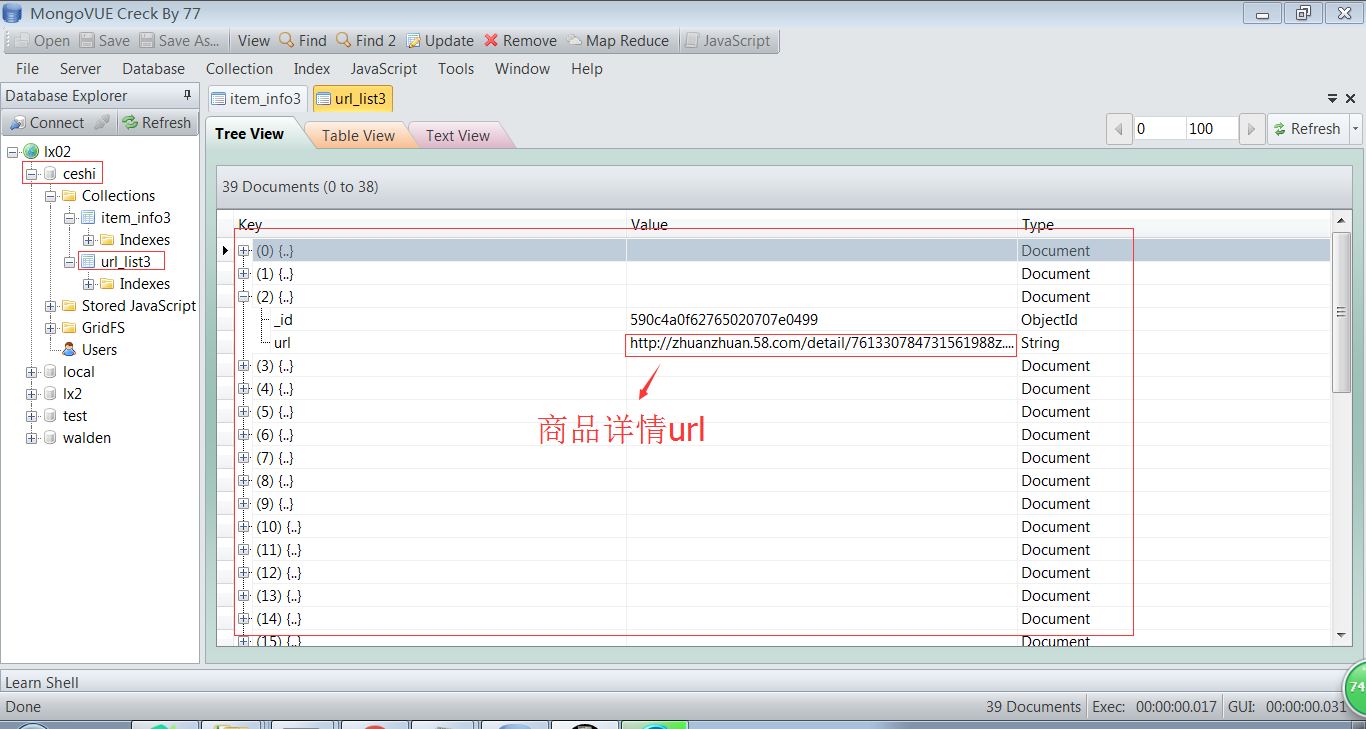

以下为最终所需要爬取的信息:
由于需要爬取所有的二手商品信息,所以以下内容也要爬取到:
1.先写一个py文件,用于爬取上述图片类目导航的各个链接:
#-*-coding:utf-8-*-
from bs4 import BeautifulSoup
import requests
start_url = 'http://bj.58.com/sale.shtml'
url_host = 'http://bj.58.com'
def get_channel_urls(url):
wb_data = requests.get(start_url)
soup = BeautifulSoup(wb_data.text,'html.parser')
links = soup.select('ul.ym-submnu > li > b > a')
for link in links:
page_url = url_host + link.get('href')
print page_url
get_channel_urls(start_url)
#类目导航链接
channel_list = ''' http://bj.58.com/shouji/ http://bj.58.com/tongxunyw/ http://bj.58.com/danche/ http://bj.58.com/fzixingche/ http://bj.58.com/diandongche/ http://bj.58.com/sanlunche/ http://bj.58.com/peijianzhuangbei/ http://bj.58.com/diannao/ http://bj.58.com/bijiben/ http://bj.58.com/pbdn/ http://bj.58.com/diannaopeijian/ http://bj.58.com/zhoubianshebei/ http://bj.58.com/shuma/ http://bj.58.com/shumaxiangji/ http://bj.58.com/mpsanmpsi/ http://bj.58.com/youxiji/ http://bj.58.com/jiadian/ http://bj.58.com/dianshiji/ http://bj.58.com/ershoukongtiao/ http://bj.58.com/xiyiji/ http://bj.58.com/bingxiang/ http://bj.58.com/binggui/ http://bj.58.com/chuang/ http://bj.58.com/ershoujiaju/ http://bj.58.com/bangongshebei/ http://bj.58.com/diannaohaocai/ http://bj.58.com/bangongjiaju/ http://bj.58.com/ershoushebei/ http://bj.58.com/yingyou/ http://bj.58.com/yingeryongpin/ http://bj.58.com/muyingweiyang/ http://bj.58.com/muyingtongchuang/ http://bj.58.com/yunfuyongpin/ http://bj.58.com/fushi/ http://bj.58.com/nanzhuang/ http://bj.58.com/fsxiemao/ http://bj.58.com/xiangbao/ http://bj.58.com/meirong/ http://bj.58.com/yishu/ http://bj.58.com/shufahuihua/ http://bj.58.com/zhubaoshipin/ http://bj.58.com/yuqi/ http://bj.58.com/tushu/ http://bj.58.com/tushubook/ http://bj.58.com/wenti/ http://bj.58.com/yundongfushi/ http://bj.58.com/jianshenqixie/ http://bj.58.com/huju/ http://bj.58.com/qiulei/ http://bj.58.com/yueqi/ http://bj.58.com/chengren/ http://bj.58.com/nvyongpin/ http://bj.58.com/qinglvqingqu/ http://bj.58.com/qingquneiyi/ http://bj.58.com/chengren/ http://bj.58.com/xiaoyuan/ http://bj.58.com/ershouqiugou/ http://bj.58.com/tiaozao/ http://bj.58.com/tiaozao/ http://bj.58.com/tiaozao/
'''
2.建立另一个py文件,用于爬取商品信息:
from bs4 import BeautifulSoup
import requests
import time
import pymongo
client = pymongo.MongoClient()
ceshi = client['ceshi']
url_list = ceshi['url_list3']
item_info = ceshi['item_info3']
def get_links_from(channel,pages,who_sells=0):
list_view = '{}{}/pn{}'.format(channel,str(who_sells),str(pages))
wb_data = requests.get(list_view)
time.sleep(1)
soup = BeautifulSoup(wb_data.text,'html.parser')
if soup.find('td','t'):
for link in soup.select('td.t a.t'):
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url':item_link})
print item_link
else:
pass
def get_item_info(url):
wb_data = requests.get(url)
soup = BeautifulSoup(wb_data.text,'html.parser')
no_longer_exist = '404' in soup.find('script',type="text/javascript").get('src').split('/')
if no_longer_exist:
pass
else:
title = soup.title.text
price = soup.select('span.price.c_f50')[0].text
date = soup.select('.time')[0].text
area = list(soup.select('.c_25d a')[0].stripped_strings) if soup.find_all('span','c_25d') else None
item_info.insert_one({'title':title,'price':price,'date':date,'area':area})
print({'title':title,'price':price,'date':date,'area':area})
get_item_info('http://bj.58.com/shuma/28049255291945x.shtml')
#get_links_from('http://bj.58.com/shuma/',2)
在第二个py文件中,需要注意的是:
1.连接mongodb时,可以不用提前在mongovue中建立数据库和collection,它会自动创建。
2.定义的第一个函数是用来爬取每个商品的具体url,并将其存入mongodb,第二个函数是通过每个商品具体的url来爬取相应的商品信息,并存入数据库,这两个函数不能同时运行。
3.在这次的爬虫项目中,有好多爬取技巧,如:
links = soup.select('ul.ym-submnu > li > b > a')
list_view = '{}{}/pn{}'.format(channel,str(who_sells),str(pages))for link in soup.select('td.t a.t'):
item_link = link.get('href').split('?')[0]
url_list.insert_one({'url':item_link})area = list(soup.select('.c_25d a')[0].stripped_strings) if soup.find_all('span','c_25d') else None等等,嘻嘻,反正这些我感觉比较新颖~~
最后,将数据存入数据库其实就是在连接数据库时,代码中有插入语句,就行~~
展示一下数据库中结果:

相关文章推荐
- 运用python抓取博客园首页的全部数据,并且定时持续抓取新发布的内容存入mongodb中
- 运用python抓取博客园首页的所有数据,而且定时持续抓取新公布的内容存入mongodb中
- python获取mysql天数据,聚合存入mongodb(我的第一个用python写的程序)
- python - 利用Pandas对某app数据进行整理、分析并存入mongodb
- Python 爬虫7——自定义Item Pipeline将数据存入MongoDB
- 抓取网络json数据并存入mongodb(2)
- 使用python获取mongodb一段时间的数据
- 把文件二进制数据存入mongodb
- python操作mongodb根据_id查询数据的实现方法
- 抓取网络json数据并存入mongodb(1)
- python抓取月光博客的所有文章并且按照标题分词存入mongodb中
- Python leveldb数据库 把txt的数据存入到leveldb
- 基于python的REST框架eve测试与mongodb的数据操作
- python抓取51CTO博客的推荐博客的所有博文,对标题分词存入mongodb中
- python连接mongodb操作数据示例(mongodb数据库配置类)
- python抓取某汽车网数据解析html存入excel示例
- python抓取CSDN博客首页的所有博文,对标题分词存入mongodb中
- 基于python的REST框架eve测试与mongodb的数据操作 推荐
- python 导出mongoDB数据中的数据
- coreseek通过python读取mongoDB数据