Python 爬虫7——自定义Item Pipeline将数据存入MongoDB
2016-08-11 15:44
459 查看
前言:
上篇我们介绍了scrapy的安装和基本的使用,本篇主要补充一个比较实用的操作,就是如何把从URL页面爬取到的数据保存到数据库中,以便于其他地方的使用,这里选择了比较简单的MongoDB作为存储数据的数据库。
一、设置信息:
在scrapy,一些基本的设置都是在settings.py中进行的,为了把爬虫爬取的数据写到数据库中的collection中,我们需要在settings.py中添加几个必要的设置信息。
1.存储使用的管道pipeline的信息:
将爬虫返回的Item数据存入数据库的操作,实际上是通过在pipelines.py脚本中自定义管道类来实现的,但是要让定义的管道正常工作就必须在设置信息中设置指向该管道的信息,打开pipelines.py脚本可以查找到跟pipeline相关的参数只有:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = {
# 'MyTest.pipelines.SomePipeline': 300,
#}
这就是配置自定义Pipeline类的参数,假设我们在pipelines.py中定义的类名为MytestPipeline,则此时ITEM_PIPELINES的参数应该为:
这里其实可以给ITEM_PIPELINES配置多个自定义的管道类,所以分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
2.连接MongoDB的一些基本参数:
使用过MongoDB的应该清楚,想要连接MongoDB数据库有几个必要的参数需要被指定,包括:ip地址、端口号、db名称和Collection的名称,这些其实对应的几个参数分别是:
MONGODB_SERVER:数据库所在服务器的ip地址
MONGODB_PORT:数据库连接对应的端口号
MONGODB_DB :数据库连接中创建的database名称
MONGODB_COLLECTION:用于存放数据的文档collection的名称
一般本地测试时,ip通常设置为localhost,端口号由创建数据库时设定的一致,其他两项参数根据所要存入数据的数据库和文档名称对应。这里我使用MongoChef来管理MongoDB数据库,所以相关的参数都能在其中查询到,如下:
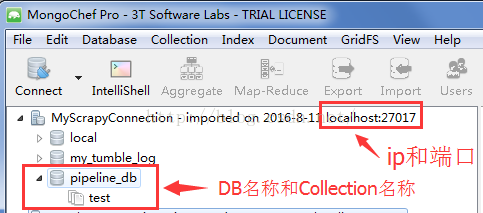
由上图可知:
因此,修改后的settings.py的内容为:
二、自定义Pipeline类:
完成了上述设置之后,我们要开始定义pipelines.py脚本中MytestPipeline类的内容,关于管道类的定义有几点基本的要求:
首先,MytestPipeline类不继承自任何类,所以按照python定义类的规律,此类继承自object;
必须重写process_item(self, item, spider)这个方法;
1.创建mongodb连接:
在Python中操作MongoDB,简单的操作可以使用pymongo直接完成,而对于比较复杂的需求,则可以使用mongoengine来抽象简化操作。这里我们以pymongo为例,在MytestPipeline类的初始化__init__方法中创建一个mongodb连接:
2.重写process_item方法:
接下来就是process_item方法的重写,这个方法必须返回一个Item(或任何继承类)对象,或是抛出
DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。这就相当于进行一次数据的合理性检测,去除不合法的数据。
参数:
item (Item 对象) – 被爬取的item
spider (Spider 对象) – 爬取该item的spider
所以,我们再对item进行判断时,同时可以将合格的数据保存到数据库中,具体实现如下:
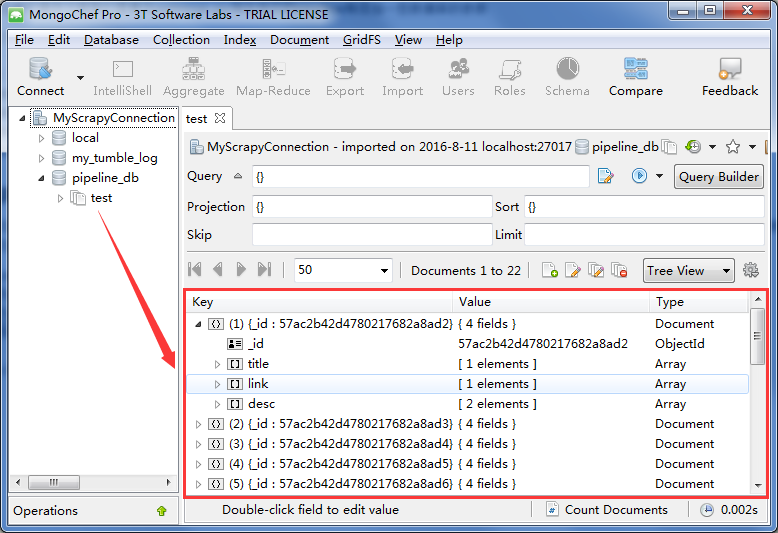
完成上述所有操作之后,我们再次运行爬虫“scrapy crawl lsh”,查看数据库,发现所有爬取的数据都已存储到数据库中:
上篇我们介绍了scrapy的安装和基本的使用,本篇主要补充一个比较实用的操作,就是如何把从URL页面爬取到的数据保存到数据库中,以便于其他地方的使用,这里选择了比较简单的MongoDB作为存储数据的数据库。
一、设置信息:
在scrapy,一些基本的设置都是在settings.py中进行的,为了把爬虫爬取的数据写到数据库中的collection中,我们需要在settings.py中添加几个必要的设置信息。
1.存储使用的管道pipeline的信息:
将爬虫返回的Item数据存入数据库的操作,实际上是通过在pipelines.py脚本中自定义管道类来实现的,但是要让定义的管道正常工作就必须在设置信息中设置指向该管道的信息,打开pipelines.py脚本可以查找到跟pipeline相关的参数只有:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html #ITEM_PIPELINES = {
# 'MyTest.pipelines.SomePipeline': 300,
#}
这就是配置自定义Pipeline类的参数,假设我们在pipelines.py中定义的类名为MytestPipeline,则此时ITEM_PIPELINES的参数应该为:
ITEM_PIPELINES = {
'MyTest.pipelines.MytestPipeline':300,
}这里其实可以给ITEM_PIPELINES配置多个自定义的管道类,所以分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。
2.连接MongoDB的一些基本参数:
使用过MongoDB的应该清楚,想要连接MongoDB数据库有几个必要的参数需要被指定,包括:ip地址、端口号、db名称和Collection的名称,这些其实对应的几个参数分别是:
MONGODB_SERVER:数据库所在服务器的ip地址
MONGODB_PORT:数据库连接对应的端口号
MONGODB_DB :数据库连接中创建的database名称
MONGODB_COLLECTION:用于存放数据的文档collection的名称
一般本地测试时,ip通常设置为localhost,端口号由创建数据库时设定的一致,其他两项参数根据所要存入数据的数据库和文档名称对应。这里我使用MongoChef来管理MongoDB数据库,所以相关的参数都能在其中查询到,如下:
由上图可知:
MONGODB_SERVER = "localhost" MONGODB_PORT = 27017 MONGODB_DB = "pipeline_db" MONGODB_COLLECTION = "test"
因此,修改后的settings.py的内容为:
ITEM_PIPELINES = {
'MyTest.pipelines.MytestPipeline':300,
}
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "pipeline_db"
MONGODB_COLLECTION = "test"二、自定义Pipeline类:
完成了上述设置之后,我们要开始定义pipelines.py脚本中MytestPipeline类的内容,关于管道类的定义有几点基本的要求:
首先,MytestPipeline类不继承自任何类,所以按照python定义类的规律,此类继承自object;
必须重写process_item(self, item, spider)这个方法;
1.创建mongodb连接:
在Python中操作MongoDB,简单的操作可以使用pymongo直接完成,而对于比较复杂的需求,则可以使用mongoengine来抽象简化操作。这里我们以pymongo为例,在MytestPipeline类的初始化__init__方法中创建一个mongodb连接:
# -*- coding: utf-8 -*- from pymongo import MongoClient from scrapy.conf import settings class MytestPipeline(object): def __init__(self): connection = MongoClient( settings[ 'MONGODB_SERVER' ], settings[ 'MONGODB_PORT' ] ) db = connection[settings[ 'MONGODB_DB' ]] self.collection = db[settings[ 'MONGODB_COLLECTION' ]]
2.重写process_item方法:
接下来就是process_item方法的重写,这个方法必须返回一个Item(或任何继承类)对象,或是抛出
DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。这就相当于进行一次数据的合理性检测,去除不合法的数据。
参数:
item (Item 对象) – 被爬取的item
spider (Spider 对象) – 爬取该item的spider
所以,我们再对item进行判断时,同时可以将合格的数据保存到数据库中,具体实现如下:
# -*- coding: utf-8 -*-
from pymongo import MongoClient
from scrapy.conf import settings
from scrapy import log
class MytestPipeline(object):
def __init__(self):
connection = MongoClient(
settings[ 'MONGODB_SERVER' ],
settings[ 'MONGODB_PORT' ]
)
db = connection[settings[ 'MONGODB_DB' ]]
self.collection = db[settings[ 'MONGODB_COLLECTION' ]]
def process_item(self, item, spider):
valid=True
for data in item:
if not data:
valid=False
raise DropItem('Missing{0}!'.format(data))
if valid:
self.collection.insert(dict(item))
log.msg('question added to mongodb database!',
level=log.DEBUG,spider=spider)
return item完成上述所有操作之后,我们再次运行爬虫“scrapy crawl lsh”,查看数据库,发现所有爬取的数据都已存储到数据库中:

相关文章推荐
- 运用python抓取博客园首页的所有数据,而且定时持续抓取新公布的内容存入mongodb中
- python3 [爬虫入门实战]scrapy爬取盘多多五百万数据并存mongoDB
- python爬取数据并将其存入mongodb
- Scrapy爬虫(6)爬取银行理财产品并存入MongoDB(共12w+数据)
- Python3实现的爬虫爬取数据并存入mysql数据库操作示例
- python3 爬虫日记(二) 将数据存到Mongodb
- python爬虫获取数据后存入MySQL数据库中
- 一个抓取智联招聘数据并存入表格的python爬虫
- python实现爬虫数据存到 MongoDB
- 【原创】python爬虫获取网站数据并存入本地数据库
- python爬虫--连接MongoDB 存数据
- python 爬虫获取json数据存入文件时乱码
- Python爬虫(入门+进阶)学习笔记 1-7 数据入库之MongoDB(案例二:爬取拉勾)
- Python爬虫系列(七)豆瓣图书排行榜(数据存入到数据库)
- python3 [爬虫入门实战]scrapy爬取盘多多五百万数据并存mongoDB
- python - 利用Pandas对某app数据进行整理、分析并存入mongodb
- python实现爬虫数据存到 MongoDB
- 运用python抓取博客园首页的全部数据,并且定时持续抓取新发布的内容存入mongodb中
- python获取mysql天数据,聚合存入mongodb(我的第一个用python写的程序)
- Python爬虫入门实战八:数据储存——MongoDB与MySQL