python3 爬“斗图啦”
2017-05-04 08:31
148 查看
接触了一个多月的python,终于可以小小露一手了。手法之拙略就不得不恭维了,哈哈,
环境win7系统,Python3.6,Pycharm2017社区版,还有Google浏览器(官网均可下载)
http:// href="http://www.doutula.com" target=_blank>www.doutula.com
需要的模块requests, lxml, BeautifulSoup,
也就是获得
User-Agent:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36
方法:随便打开网页 F12 --Network --F5 --Headers -- User-Agent

代码来了

每一套“斗图”对应一个 a 标签,所以直接find_all('a',attrs={'class':'list-group-item'}),谢谢站长布局如此规律。
注意这是上面代码的继续,所以注意 缩进
然后就有你要的图了,一个一个,据说还可以多线程下载,当然需要另一个模块(threading)了的,
下次见
环境win7系统,Python3.6,Pycharm2017社区版,还有Google浏览器(官网均可下载)
http://
需要的模块requests, lxml, BeautifulSoup,
import requests import lxml from bs4 import BeautifulSoup说明一下,下载很多网站都有了反爬机制,所以道高一尺,魔高一丈了,我们模拟浏览器去访问网站,
也就是获得
User-Agent:
Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.81 Safari/537.36
方法:随便打开网页 F12 --Network --F5 --Headers -- User-Agent
代码来了
start_url = "http://www.doutula.com/arcticle/list/?page=1"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'}
start_html = requests.get(url=url, headers=headers).content
#print(start_html)
soup = BeautifulSoup(start_html,'lxml') ##lxml 解析网页的
all_a = soup.find_all('a',attrs={'class':'list-group-item'})
for a in all_a:
#title = a.h4.get_text()
url = a['href']
#print(title,url)每一套“斗图”对应一个 a 标签,所以直接find_all('a',attrs={'class':'list-group-item'}),谢谢站长布局如此规律。
注意这是上面代码的继续,所以注意 缩进
img_html = requests.get(url,headers=header).text
img_soup = lxml.etree.HTML(img_html) ##打印源码,自动修正html
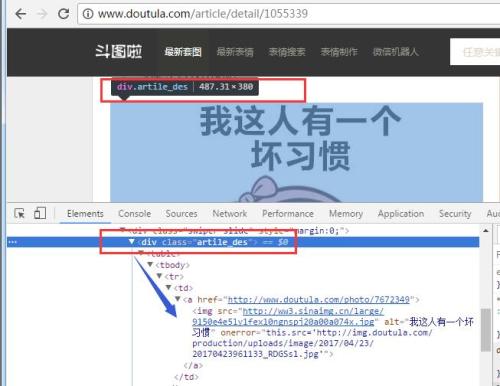
img_items = img_soup.xpath('//div[@class="artile_des"]')
for item in img_items:
imgurl_list = item.xpath('table/tbody/tr/td/a/img/@src')[0] ##[0]取list的第一个元素
print("正在下载"+imgurl_list)
imgcontent = requests.get(imgurl_list).content ##换成text会报错no 'str'
with open('doutu/%s' % imgurl_list.split('/')[-1],'wb') as f: ##doutu是文件夹,需要自己提前创建
f.write(imgcontent)然后就有你要的图了,一个一个,据说还可以多线程下载,当然需要另一个模块(threading)了的,
下次见

相关文章推荐
- Python爬虫系列(三)多线程爬取斗图网站(皮皮虾,我们上车)
- [置顶] 学会用python网络爬虫爬取斗图网的表情包,聊微信再也不怕斗图了
- 用python爬取斗图啦图片
- 学会用python网络爬虫爬取斗图网的表情包,聊微信再也不怕斗图了
- 搭建Python的集成开发环境WingIDE
- Python指南--深入流程控制
- Python指南--深入流程控制
- 用Python实现数据库编程
- Python指南--开胃菜
- Python指南--数据结构
- Python指南--开胃菜
- Python指南--数据结构
- Python指南--初步认识Python
- Python指南--前言
- Python指南--使用Python解释器
- Python指南--使用Python解释器
- C++ Boost 之Python(生成一个扩展模块)
- C++ Boost 之Python(一个简单的例子)
- C++ Boost 之Python(继承)