Pandas GroupBy 分组(分割-应用-组合)
2017-04-30 11:51
323 查看
http://pandas.pydata.org/pandas-docs/stable/groupby.html#group-by-split-apply-combine
- 分割(Splitting)将数据按照某个标准分组
- 应用(Applying)对每个分组分别使用函数
- 组合(Combining)将结果组合成数据框
当然还有更多的操作比如:
- 聚合(Aggregation) 同时对分组进行多种计算,比如同时计算sum和means
- 变换(Transformation) 标准化分组数据,根据组数据填充组空值
- Filtration(
简介
分组(group by)一般是指三个过程- 分割(Splitting)将数据按照某个标准分组
- 应用(Applying)对每个分组分别使用函数
- 组合(Combining)将结果组合成数据框
当然还有更多的操作比如:
- 聚合(Aggregation) 同时对分组进行多种计算,比如同时计算sum和means
- 变换(Transformation) 标准化分组数据,根据组数据填充组空值
- Filtration(
groupby对象具体信息
请参考Pandas GroupBy对象 索引与迭代apply函数
In [123]: df
Out[123]:
A B C D
0 foo one -0.919854 -1.131345
1 bar one -0.042379 -0.089329
2 foo two 1.247642 0.337863
3 bar three -0.009920 -0.945867
4 foo two 0.290213 -0.932132
5 bar two 0.495767 1.956030
6 foo one 0.362949 0.017587
7 foo three 1.548106 -0.016692
In [124]: grouped = df.groupby('A')
In [125]: grouped['C'].apply(lambda x: x.describe()) # 描述每组信息
Out[125]:
A
bar count 3.000000
mean 0.147823
std 0.301765
min -0.042379
25%
4000
-0.026149
50% -0.009920
75% 0.242924
...
foo mean 0.505811
std 0.966450
min -0.919854
25% 0.290213
50% 0.362949
75% 1.247642
max 1.548106
Name: C, dtype: float64使用多种函数agg()
相同的函数
如果是一列,不同值的计算,使用列表In [56]: grouped = df.groupby('A')
In [57]: grouped['C'].agg([np.sum, np.mean, np.std])
Out[57]:
sum mean std
A
bar 0.443469 0.147823 0.301765
foo 2.529056 0.505811 0.966450不同的函数
如果是多列,不同值的计算,使用字典In [60]: grouped.agg({'C' : np.sum,
....: 'D' : lambda x: np.std(x, ddof=1)})
....:
Out[60]:
C D
A
bar 0.443469 1.490982
foo 2.529056 0.645875转变数据框transformation
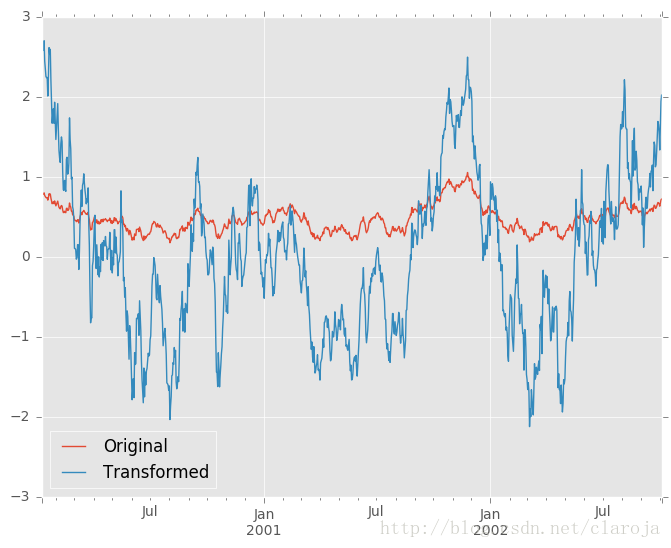
转变函数(transform)中需要返回一个和分组块(group chunk)同样大小的结果,比如我们需要标准化每一个分组的数据:In [66]: index = pd.date_range('10/1/1999', periods=1100)
In [67]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index)
In [68]: ts = ts.rolling(window=100,min_periods=100).mean().dropna()
In [71]: key = lambda x: x.year#使用年来分组
In [72]: zscore = lambda x: (x - x.mean()) / x.std()#标准化
In [73]: transformed = ts.groupby(key).transform(zscore)#使用索引的年份来分组,然后标准化各组数据
In [80]: compare = pd.DataFrame({'Original': ts, 'Transformed': transformed})# 做出图形过滤Filtration
filter方法返回一个子集(subset),这个是针对组的过滤,而不是针对组中的值过滤。比如我们只想要组长度大于2的分组:In [105]: dff = pd.DataFrame({'A': np.arange(8), 'B': list('aabbbbcc')})
In [106]: dff.groupby('B').filter(lambda x: len(x) > 2)
Out[106]:
A B
2 2 b
3 3 b
4 4 b
5 5 b

相关文章推荐
- Pandas GroupBy 分组(分割-应用-组合)
- Linq及Lamda表达式应用经验之 GroupBy 分组
- c# Linq及Lamda表达式应用经验之 GroupBy 分组
- pandas中Groupby使用(二)-对分组进行迭代
- pandas中的groupby函数的分组结果怎么保存成DataFrame
- 【.Net码农】C# Linq及Lamda表达式应用经验之 GroupBy 分组
- Linq及Lamda表达式应用经验之 GroupBy 分组
- Pandas分组统计函数:groupby、pivot_table及crosstab
- C# Linq及Lamda表达式实战应用之 GroupBy 分组统计
- BZOJ 3505 浅谈组合数学在图形区域分割问题的应用
- pandas之groupby分组与pivot_table透视表
- (转)c# Linq及Lamda表达式应用经验之 GroupBy 分组
- c# Linq及Lamda表达式应用经验之 GroupBy 分组
- c# Linq及Lamda表达式应用经验之 GroupBy 分组
- Linq及Lamda表达式应用经验之 GroupBy 分组
- Pandas分组运算(groupby)修炼
- c# Linq及Lamda表达式应用经验之 GroupBy 分组
- pandas聚合和分组运算——GroupBy技术(1)
- c# Linq及Lamda表达式应用经验之 GroupBy 分组
- 斐波那契数列应用在字符串分割组合上的算法题