Linux Memory 理解内存模型
2017-04-25 21:47
656 查看
在user space里的内存,大致是这个结构
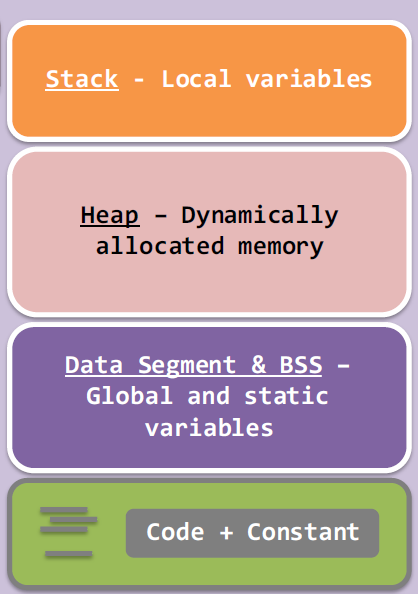
(1) 代码和常量放在底部的内存里,这是只读的区域。尝试在这个区域写入会造成segmentation fault。
(2)底部向上的第二部分是放全局变量和静态变量的内存区,其中更进一步分为了 data segment 和 BSS(Block Started by Symbol )。
data segment存放的是初始化的数据,而BSS存放的是未初始化的数据。
BSS的意义在于节省空间(Better Save Space),未初始化的全局变量和静态变量在编译时不会将实际大小空间放进可执行文件中,从而减小体积。相反,初始化过的全局变量和静态变量在编译时会得到预分配的空间。
(3)模型的顶部是存放本地变量的栈 stack。
程序调用函数时,会将参数和返回地址都压进栈中,函数执行完后就被依次弹出(整个机制是编译器加进代码的,而不是靠kernel执行的)。
由于函数的返回地址,可以被栈中的其他变量通过地址操作获得,因此会有 buffer overflow attack 栈溢出攻击 的 危险。
栈的大小通常默认是8192KB = 8MB, 可以通过 ulimit -s 设置和查询
(4) 剩下的那部分是存放动态分配变量的内存区叫做 堆 heap。
malloc和free的时候(可能)会改变堆的边界。 注意,malloc花费的内存大小会略大于请求的内存,因为会创建额外的结构。
关于free,堆中有一个指向空闲内存区的链表。
free的时候,如果被free的内存处于堆的边界,则直接压缩边界;如果处于中间,则通过操作指向空闲内存区的链表完成。
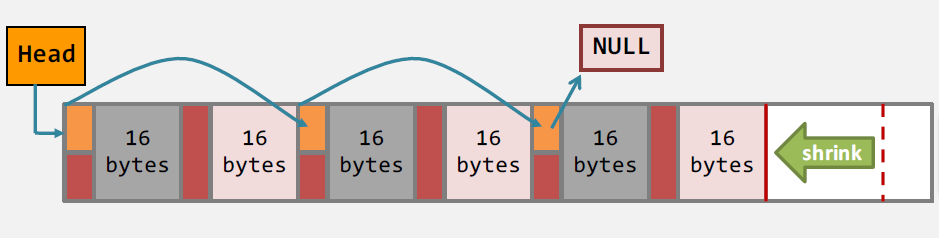
同样的,如果需要malloc新内存,则会考虑使用指向空闲内存区的链表(如果空间足够的话),或者直接扩大堆的大小。
OOM 内存耗尽
有两种情况:
(1) 内存地址耗尽
如果代码只是声明或者malloc申请了内存而没有实际写入数据,则实际上并没有使用内存,耗尽的只是内存地址
(2)真实内存耗尽
不仅声明或者malloc申请了内存而且写入数据
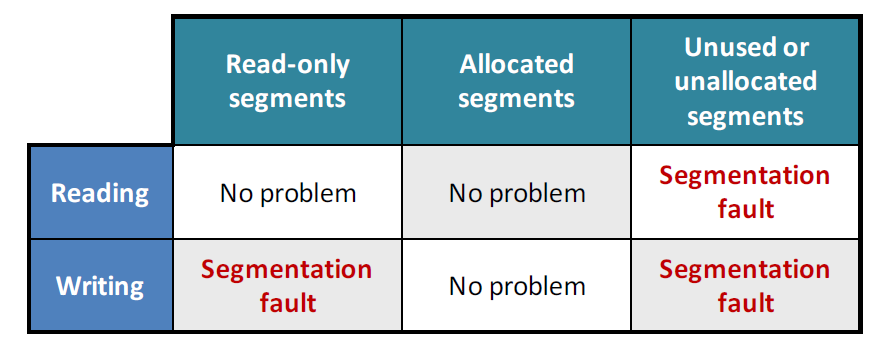
Segmentation fault 臭名昭著的段错误
通常是因为违法使用或接触了内存
Virtual memory 虚拟内存
上述的内存和地址实际上都是虚拟的,进程不会直接接触到物理内存。
虚拟内存地址通过MMU( memory management unit )转换成了物理内存。
通常在不同进程中的相同内存地址对应的物理地址是不同的,除非是共享内存 shared memory.
MMU的实现
关键在于实现一个查询表。
假设地址大小为32bit,下面将一个地址分成两部分 page address 和 page offset
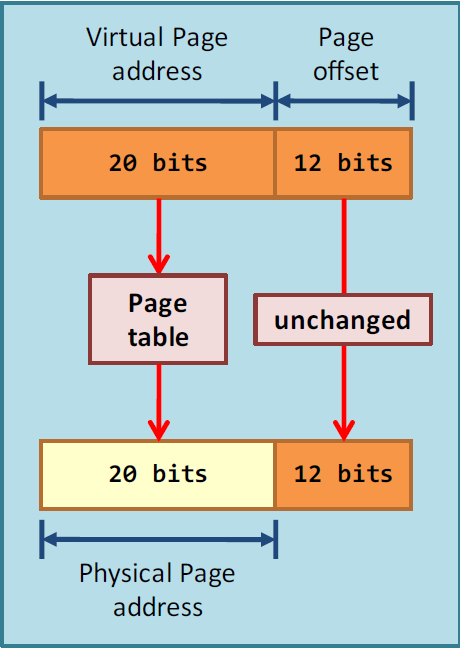
如此一来,MMU中的查询表包含了 2^20个 大小为 32 bit 的项。每个项对应一个虚拟地址page和一个物理地址page,而项中的offset则完全相等对应。这样的一个查询表 只有 2^20 x 4 bytes = 4 Mbytes 大小。
在地址分配中,page才是基本单位。因此,malloc(1) 可能会直接分配了一个page大小(默认是4096byte)的内存——这也是为什么malloc(1)的指针可能可以向上额外移动了很长距离才产生 segmentation fault。
一个 page table 示例
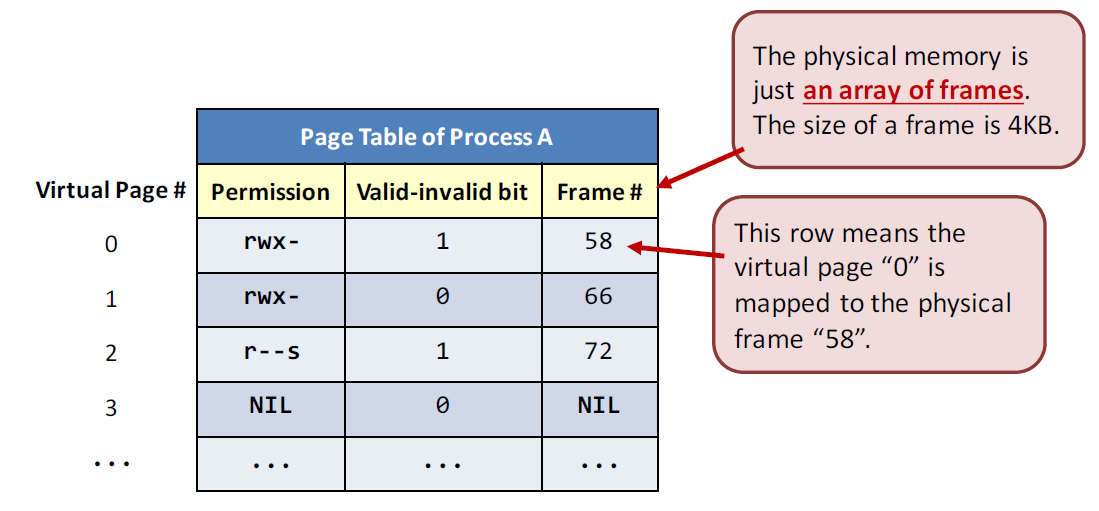
Demand paging 按需分配地址
(1) 代码执行malloc时,实际上只是创建了一个page table item,valid-invalid bit 为 0,Frame # 为 NIL。当这个内存被访问时,会产生 page fault, page fault handling routine 就会运行,从物理内存中找到一个地址返回,再将valid-invalid bit 设为 1,Frame # 设为 对应的数字。
(2) 当物理内存被分配完时,系统会将物理内存中的一些内容复制 硬盘的swap area,然后将那些内容重写成需求的内存。同时,需要更新page table。
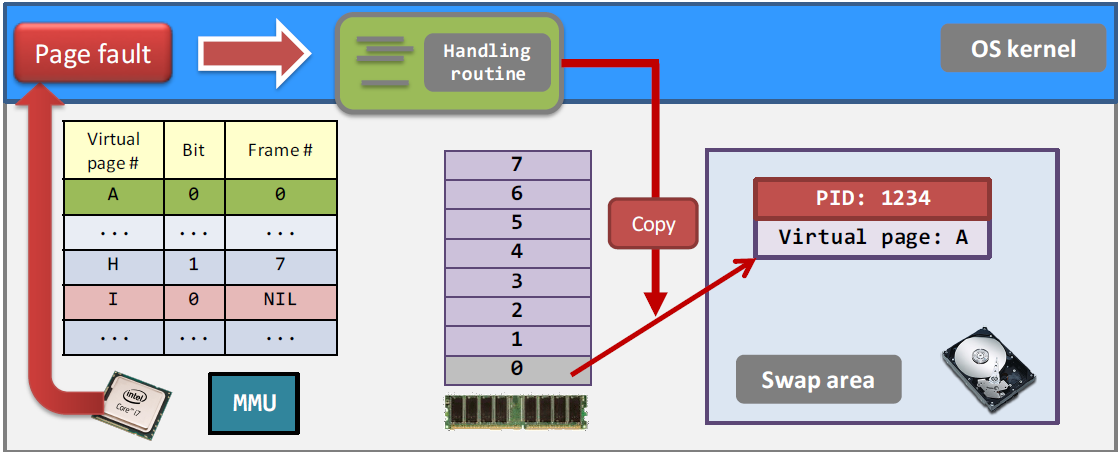
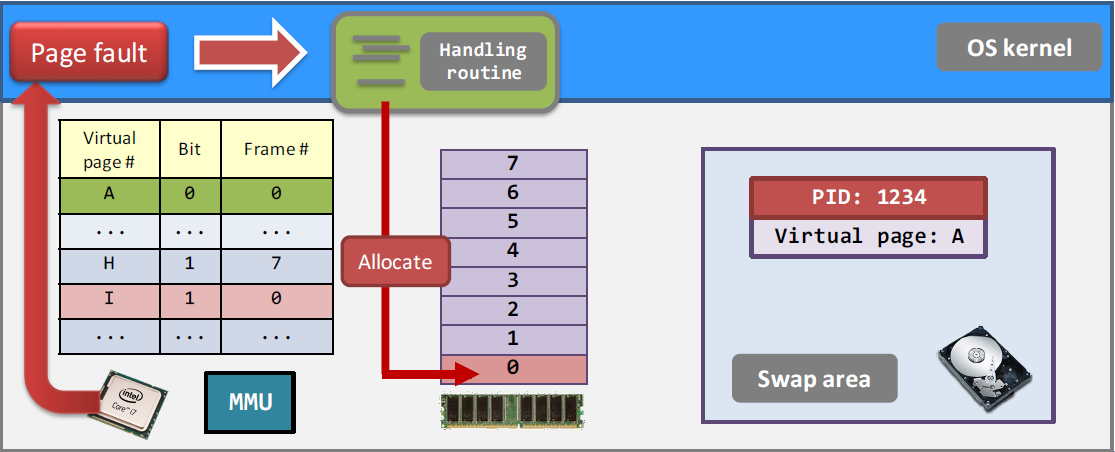
(3) 当一个进程访问它之前获取过的内存但是已经被放进swap area时,会产生page fault,尝试从swap area中将原本的内容重新加载到物理内存里,最后更新page table。
fork() 在内存方面的实现
Copy-on-write (COW) technique
fork()后得到的新进程并不会把所有物理内存都复制一遍,而是仅仅复制page table 并且将权限都改为保护性的权限。
直到进程访问了内存,将会产生page fault,并分配和复制真实的内存,最后改回权限。
Page replacement algorithms
目的:尽量减少 page fault 的次数,因此将复制到swap area 的 内存最好是将来也不常被访问的内容。
FIFO 先进先出算法
最早被swap in的内存也将是最早被swap out的内存
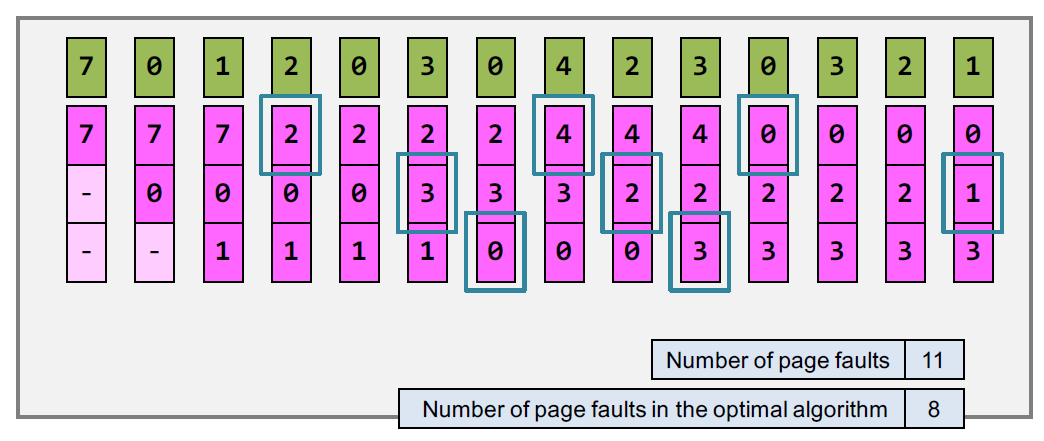
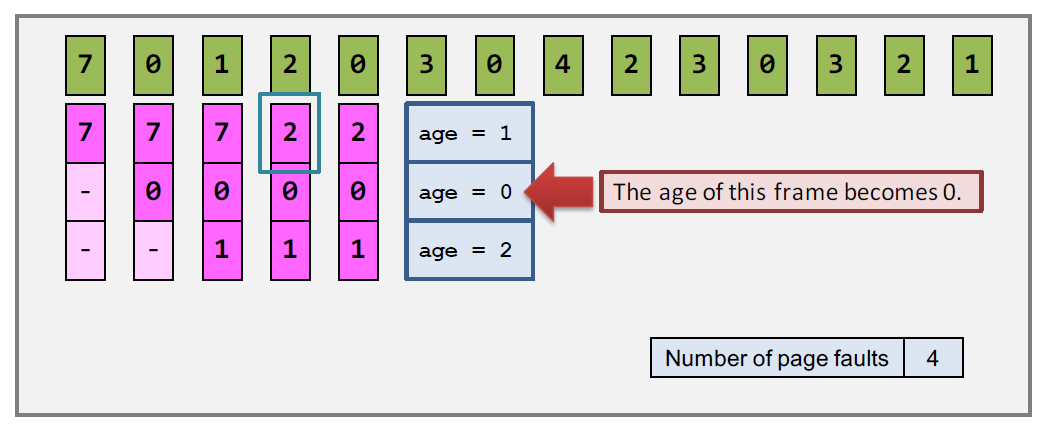
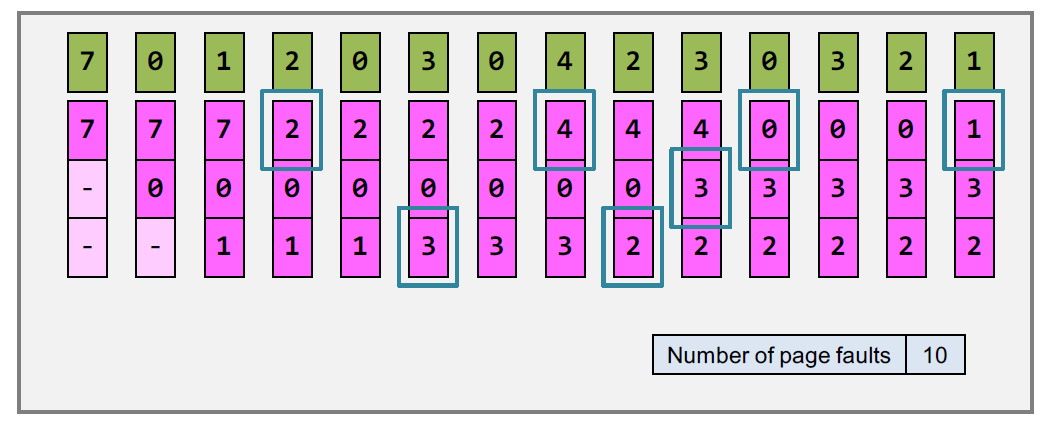
least recently- used (LRU) 最近最少使用算法
每个page都有一个age变量,每当被访问后 age 就重置为0,其他的page都加1 。需要时,就将age最大的page swap out。
Context-switch 中的 page table
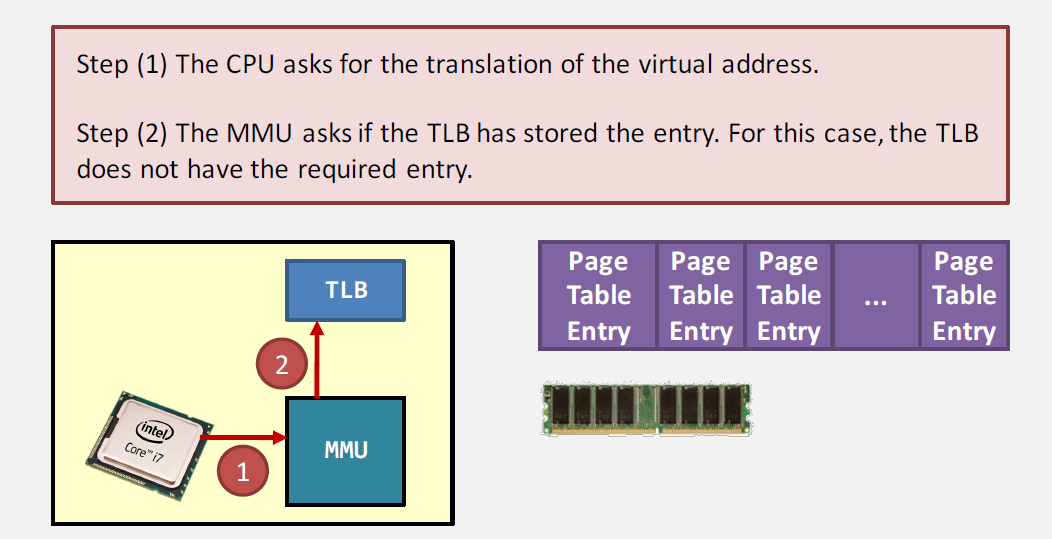
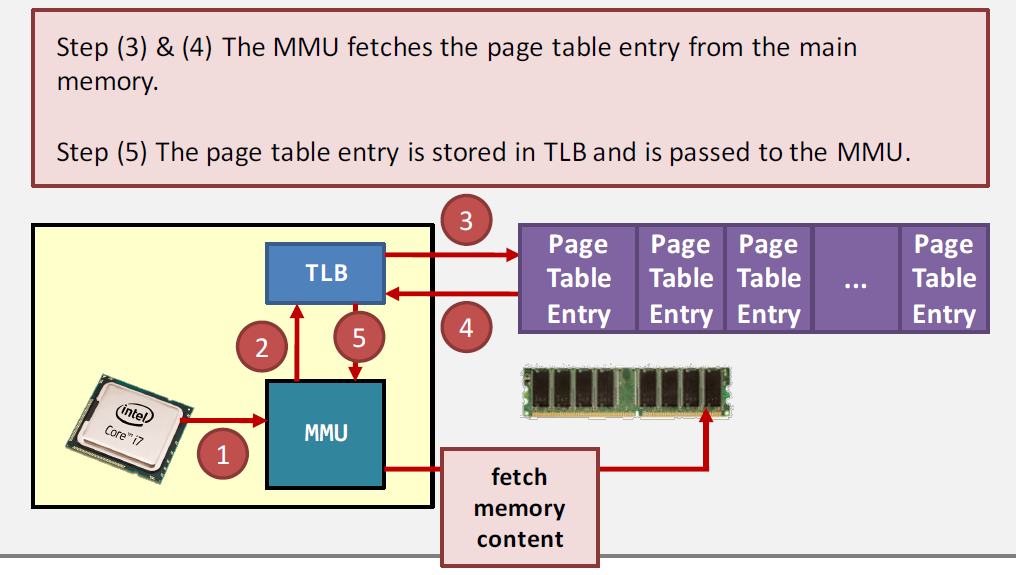
context switch 时,如果每次都将 4M 大小的page table切换,效率会很低。
最佳做法是将page table放在main memory里,在TLB(Translation Lookaside Buffer)中缓存最近使用过的page。
(1) 代码和常量放在底部的内存里,这是只读的区域。尝试在这个区域写入会造成segmentation fault。
(2)底部向上的第二部分是放全局变量和静态变量的内存区,其中更进一步分为了 data segment 和 BSS(Block Started by Symbol )。
data segment存放的是初始化的数据,而BSS存放的是未初始化的数据。
BSS的意义在于节省空间(Better Save Space),未初始化的全局变量和静态变量在编译时不会将实际大小空间放进可执行文件中,从而减小体积。相反,初始化过的全局变量和静态变量在编译时会得到预分配的空间。
(3)模型的顶部是存放本地变量的栈 stack。
程序调用函数时,会将参数和返回地址都压进栈中,函数执行完后就被依次弹出(整个机制是编译器加进代码的,而不是靠kernel执行的)。
由于函数的返回地址,可以被栈中的其他变量通过地址操作获得,因此会有 buffer overflow attack 栈溢出攻击 的 危险。
栈的大小通常默认是8192KB = 8MB, 可以通过 ulimit -s 设置和查询
(4) 剩下的那部分是存放动态分配变量的内存区叫做 堆 heap。
malloc和free的时候(可能)会改变堆的边界。 注意,malloc花费的内存大小会略大于请求的内存,因为会创建额外的结构。
关于free,堆中有一个指向空闲内存区的链表。
free的时候,如果被free的内存处于堆的边界,则直接压缩边界;如果处于中间,则通过操作指向空闲内存区的链表完成。
同样的,如果需要malloc新内存,则会考虑使用指向空闲内存区的链表(如果空间足够的话),或者直接扩大堆的大小。
OOM 内存耗尽
有两种情况:
(1) 内存地址耗尽
如果代码只是声明或者malloc申请了内存而没有实际写入数据,则实际上并没有使用内存,耗尽的只是内存地址
(2)真实内存耗尽
不仅声明或者malloc申请了内存而且写入数据
Segmentation fault 臭名昭著的段错误
通常是因为违法使用或接触了内存
Virtual memory 虚拟内存
上述的内存和地址实际上都是虚拟的,进程不会直接接触到物理内存。
虚拟内存地址通过MMU( memory management unit )转换成了物理内存。
通常在不同进程中的相同内存地址对应的物理地址是不同的,除非是共享内存 shared memory.
MMU的实现
关键在于实现一个查询表。
假设地址大小为32bit,下面将一个地址分成两部分 page address 和 page offset
如此一来,MMU中的查询表包含了 2^20个 大小为 32 bit 的项。每个项对应一个虚拟地址page和一个物理地址page,而项中的offset则完全相等对应。这样的一个查询表 只有 2^20 x 4 bytes = 4 Mbytes 大小。
在地址分配中,page才是基本单位。因此,malloc(1) 可能会直接分配了一个page大小(默认是4096byte)的内存——这也是为什么malloc(1)的指针可能可以向上额外移动了很长距离才产生 segmentation fault。
一个 page table 示例
Demand paging 按需分配地址
(1) 代码执行malloc时,实际上只是创建了一个page table item,valid-invalid bit 为 0,Frame # 为 NIL。当这个内存被访问时,会产生 page fault, page fault handling routine 就会运行,从物理内存中找到一个地址返回,再将valid-invalid bit 设为 1,Frame # 设为 对应的数字。
(2) 当物理内存被分配完时,系统会将物理内存中的一些内容复制 硬盘的swap area,然后将那些内容重写成需求的内存。同时,需要更新page table。
(3) 当一个进程访问它之前获取过的内存但是已经被放进swap area时,会产生page fault,尝试从swap area中将原本的内容重新加载到物理内存里,最后更新page table。
fork() 在内存方面的实现
Copy-on-write (COW) technique
fork()后得到的新进程并不会把所有物理内存都复制一遍,而是仅仅复制page table 并且将权限都改为保护性的权限。
直到进程访问了内存,将会产生page fault,并分配和复制真实的内存,最后改回权限。
Page replacement algorithms
目的:尽量减少 page fault 的次数,因此将复制到swap area 的 内存最好是将来也不常被访问的内容。
FIFO 先进先出算法
最早被swap in的内存也将是最早被swap out的内存
least recently- used (LRU) 最近最少使用算法
每个page都有一个age变量,每当被访问后 age 就重置为0,其他的page都加1 。需要时,就将age最大的page swap out。
Context-switch 中的 page table
context switch 时,如果每次都将 4M 大小的page table切换,效率会很低。
最佳做法是将page table放在main memory里,在TLB(Translation Lookaside Buffer)中缓存最近使用过的page。

相关文章推荐
- 我对C++11内存模型的一点理解(附面经)
- 深入理解JVM内存模型
- 理解JVM—JVM内存模型
- 深入理解JVM—JVM内存模型
- 【转】深入理解JVM—JVM内存模型
- 深入理解C++对象模型-对象的内存布局,vptr,vtable
- 深入理解JVM—JVM内存模型
- 深入理解JVM—JVM内存模型
- 深入理解Java String#intern() 内存模型
- 深入理解JVM内存模型
- 深入理解JVM -- 内存模型及内存溢出(OOM/Out of Memory)
- 深入理解Java虚拟机笔记--JVM内存模型及溢出问题总结
- C语言之指针专题三:理解指针要和内存四区模型和函数调用模型相结合
- 计算机内存模型 粗浅理解
- 深入理解Java虚拟机笔记---内存模型
- 深入理解JVM—JVM内存模型(很经典) (部分摘自 深入JAVA虚拟机 周志明著)
- 对 Java 内存模型的理解
- 深入理解JVM内存模型
- 深入浅出理解 | Java 内存模型
- 【Java】深入理解JVM内存模型