Mybatis原理,优缺点,以及与Hibernate的比较
2017-04-24 18:20
806 查看
转自:http://blog.csdn.net/luanlouis/article/details/40422941
MyBatis参考资料官网:https://mybatis.github.io/mybatis-3/zh/index.html
MyBatis 是支持定制 化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手工设置参数以及抽取结果集。 MyBatis 使用简单的 XML 或注解来配置和映射基本体,将接口和 Java 的 POJOs(Plain Old Java Objects, 普通的 Java对象)映射成数据库中的记录。
原理详解:
MyBatis应用程序根据XML配置文件创建SqlSessionFactory,SqlSessionFactory在根据配置,配置来源于两个地方,一处是配置文件,一处是Java代码的注解,获取一个SqlSession。SqlSession包含了执行sql所需要的所有方法,可以通过SqlSession实例直接运行映射的sql语句,完成对数据的增删改查和事务提交等,用完之后关闭SqlSession。
mybatis本身就很小且简单。没有任何第三方依赖,最简单安装只要两个jar文件+配置几个sql映射文件易于学习,易于使用,通过文档和源代码,可以比较完全的掌握它的设计思路和实现。
2、灵活
mybatis不会对应用程序或者数据库的现有设计强加任何影响。 sql写在xml里,便于统一管理和优化。通过sql基本上可以实现我们不使用数据访问框架可以实现的所有功能,或许更多。
3、解除sql与程序代码的耦合
通过提供DAL层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。sql和代码的分离,提高了可维护性。
4、提供映射标签,支持对象与数据库的orm字段关系映射
5、提供对象关系映射标签,支持对象关系组建维护
6、提供xml标签,支持编写动态sql。
2、SQL语句依赖于数据库,导致数据库移植性差,不能更换数据库。
3、框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
4、二级缓存机制不佳
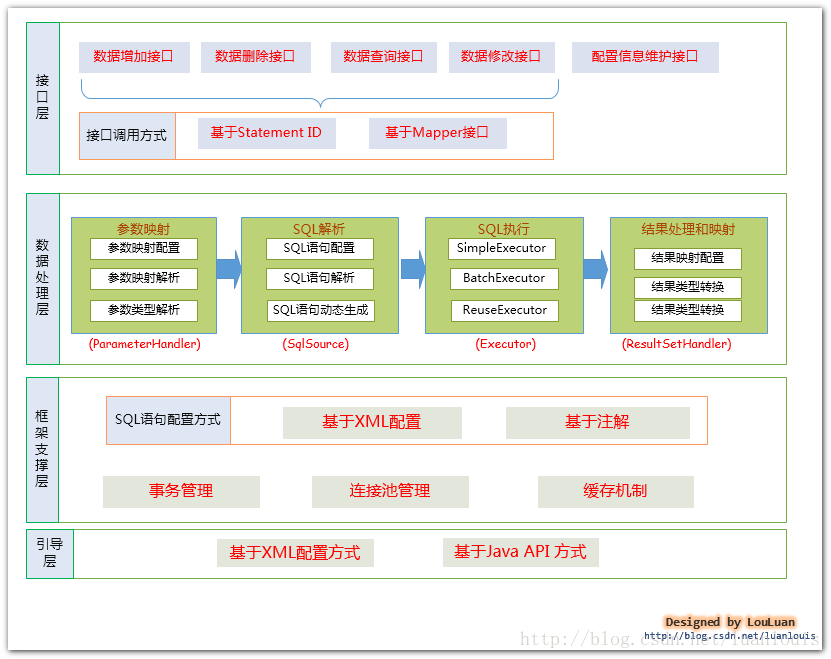
注:上图很大程度上参考了iteye
上的chenjc_it 所写的博文原理分析之二:框架整体设计 中的MyBatis架构体图,chenjc_it总结的非常好,赞一个!
MyBatis和数据库的交互有两种方式:
a.使用传统的MyBatis提供的API;
b. 使用Mapper接口
1.1.使用传统的MyBatis提供的API
这是传统的传递Statement Id 和查询参数给SqlSession对象,使用SqlSession对象完成和数据库的交互;MyBatis提供了非常方便和简单的API,供用户实现对数据库的增删改查数据操作,以及对数据库连接信息和MyBatis自身配置信息的维护操作。

上述使用MyBatis的方法,是创建一个和数据库打交道的SqlSession对象,然后根据Statement
Id 和参数来操作数据库,这种方式固然很简单和实用,但是它不符合面向对象语言的概念和面向接口编程的编程习惯。由于面向接口的编程是面向对象的大趋势,MyBatis为了适应这一趋势,增加了第二种使用MyBatis支持接口(Interface)调用方式。
1.2. 使用Mapper接口
MyBatis将配置文件中的每一个<mapper>节点抽象为一个 Mapper 接口,而这个接口中声明的方法和跟<mapper>节点中的<select|update|delete|insert>节点项对应,即<select|update|delete|insert>节点的id值为Mapper接口中的方法名称,parameterType值表示Mapper对应方法的入参类型,而resultMap值则对应了Mapper接口表示的返回值类型或者返回结果集的元素类型。
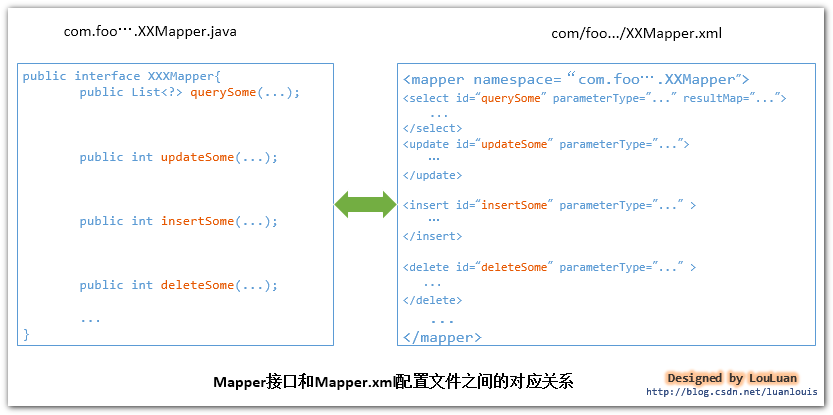
根据MyBatis的配置规范配置好后,通过SqlSession.getMapper(XXXMapper.class) 方法,MyBatis会根据相应的接口声明的方法信息,通过动态代理机制生成一个Mapper实例,我们使用Mapper接口的某一个方法时,MyBatis会根据这个方法的方法名和参数类型,确定Statement
Id,底层还是通过SqlSession.select("statementId",parameterObject);或者SqlSession.update("statementId",parameterObject);等等来实现对数据库的操作,(至于这里的动态机制是怎样实现的,我将准备专门一片文章来讨论,敬请关注~)
MyBatis引用Mapper接口这种调用方式,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是在于,面向接口的编程,使得用户在接口上可以使用注解来配置SQL语句,这样就可以脱离XML配置文件,实现“0配置”)。
a. 通过传入参数构建动态SQL语句;
b.可以使用拦截器重组SQL语句;(补充)
c.SQL语句的执行以及封装查询结果集成List<E>
2.1.参数映射和动态SQL语句生成
动态语句生成可以说是MyBatis框架非常优雅的一个设计,MyBatis通过传入的参数值,使用Ognl 来动态地构造SQL语句,使得MyBatis有很强的灵活性和扩展性。
参数映射指的是对于Java数据类型和jdbc数据类型之间的转换:这里有包括两个过程:查询阶段,我们要将java类型的数据,转换成jdbc类型的数据,通过preparedStatement.setXXX()来设值;另一个就是对resultset查询结果集的jdbcType数据转换成java数据类型。
(至于具体的MyBatis是如何动态构建SQL语句的,我将准备专门一篇文章来讨论,敬请关注~)
2.2. SQL语句的执行以及封装查询结果集成List<E>
动态SQL语句生成之后,MyBatis将执行SQL语句,并将可能返回的结果集转换成List<E> 列表。MyBatis在对结果集的处理中,支持结果集关系一对多和多对一的转换,并且有两种支持方式,一种为嵌套查询语句的查询,还有一种是嵌套结果集的查询。
3.
3.1. 事务管理机制
事务管理机制对于ORM框架而言是不可缺少的一部分,事务管理机制的质量也是考量一个ORM框架是否优秀的一个标准,对于数据管理机制我已经在我的博文《深入理解mybatis原理》
MyBatis事务管理机制 中有非常详细的讨论,感兴趣的读者可以点击查看。
3.2. 连接池管理机制
由于创建一个数据库连接所占用的资源比较大, 对于数据吞吐量大和访问量非常大的应用而言,连接池的设计就显得非常重要,对于连接池管理机制我已经在我的博文《深入理解mybatis原理》
Mybatis数据源与连接池 中有非常详细的讨论,感兴趣的读者可以点击查看。
3.3. 缓存机制
为了提高数据利用率和减小服务器和数据库的压力,MyBatis会对于一些查询提供会话级别的数据缓存,会将对某一次查询,放置到SqlSession中,在允许的时间间隔内,对于完全相同的查询,MyBatis会直接将缓存结果返回给用户,而不用再到数据库中查找。(至于具体的MyBatis缓存机制,我将准备专门一篇文章来讨论,敬请关注~)
3. 4. SQL语句的配置方式
传统的MyBatis配置SQL语句方式就是使用XML文件进行配置的,但是这种方式不能很好地支持面向接口编程的理念,为了支持面向接口的编程,MyBatis引入了Mapper接口的概念,面向接口的引入,对使用注解来配置SQL语句成为可能,用户只需要在接口上添加必要的注解即可,不用再去配置XML文件了,但是,目前的MyBatis只是对注解配置SQL语句提供了有限的支持,某些高级功能还是要依赖XML配置文件配置SQL语句。
4
引导层是配置和启动MyBatis配置信息的方式。MyBatis提供两种方式来引导MyBatis:基于XML配置文件的方式和基于JavaAPI的方式,读者可以参考我的另一片博文:Java
Persistence with MyBatis 3(中文版) 第二章 引导MyBatis
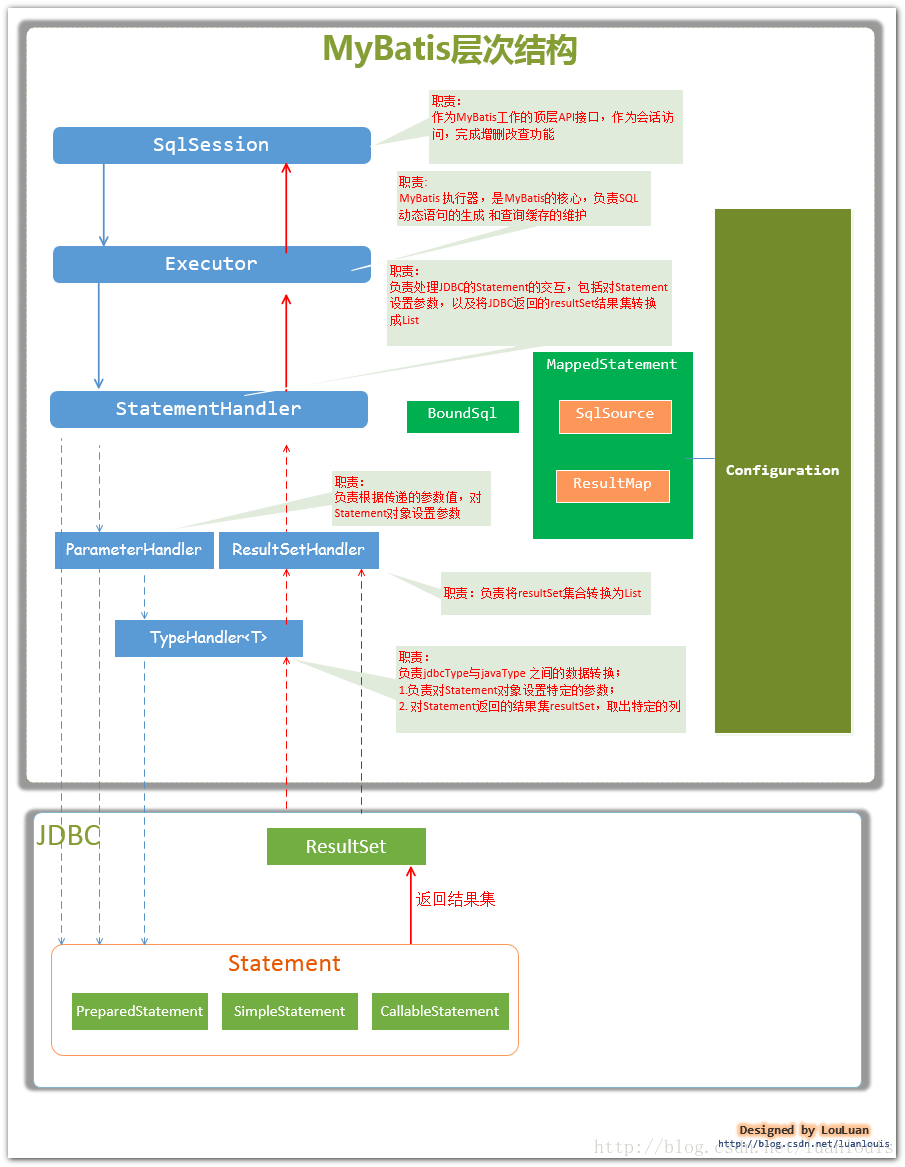
从MyBatis代码实现的角度来看,MyBatis的主要的核心部件有以下几个:
SqlSession 作为MyBatis工作的主要顶层API,表示和数据库交互的会话,完成必要数据库增删改查功能
Executor MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护
StatementHandler 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合。
ParameterHandler 负责对用户传递的参数转换成JDBC Statement 所需要的参数,
ResultSetHandler 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合;
TypeHandler 负责java数据类型和jdbc数据类型之间的映射和转换
MappedStatement MappedStatement维护了一条<select|update|delete|insert>节点的封装,
SqlSource 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回
BoundSql 表示动态生成的SQL语句以及相应的参数信息
Configuration MyBatis所有的配置信息都维持在Configuration对象之中。
(注:这里只是列出了我个人认为属于核心的部件,请读者不要先入为主,认为MyBatis就只有这些部件哦!每个人对MyBatis的理解不同,分析出的结果自然会有所不同,欢迎读者提出质疑和不同的意见,我们共同探讨~)
它们的关系如下图所示:
一、数据准备(非常熟悉和应用过MyBatis
1. 准备数据库数据,创建EMPLOYEES表,插入数据:
[sql] view
plain copy


--创建一个员工基本信息表
create table "EMPLOYEES"(
"EMPLOYEE_ID" NUMBER(6) not null,
"FIRST_NAME" VARCHAR2(20),
"LAST_NAME" VARCHAR2(25) not null,
"EMAIL" VARCHAR2(25) not null unique,
"SALARY" NUMBER(8,2),
constraint "EMP_EMP_ID_PK" primary key ("EMPLOYEE_ID")
);
comment on table EMPLOYEES is '员工信息表';
comment on column EMPLOYEES.EMPLOYEE_ID is '员工id';
comment on column EMPLOYEES.FIRST_NAME is 'first name';
comment on column EMPLOYEES.LAST_NAME is 'last name';
comment on column EMPLOYEES.EMAIL is 'email address';
comment on column EMPLOYEES.SALARY is 'salary';
--添加数据
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (100, 'Steven', 'King', 'SKING', 24000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (101, 'Neena', 'Kochhar', 'NKOCHHAR', 17000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (102, 'Lex', 'De Haan', 'LDEHAAN', 17000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (103, 'Alexander', 'Hunold', 'AHUNOLD', 9000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (104, 'Bruce', 'Ernst', 'BERNST', 6000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (105, 'David', 'Austin', 'DAUSTIN', 4800.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (106, 'Valli', 'Pataballa', 'VPATABAL', 4800.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (107, 'Diana', 'Lorentz', 'DLORENTZ', 4200.00);
2. 配置Mybatis的配置文件,命名为mybatisConfig.xml:
[html] view
plain copy
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<dataSource type="POOLED">
<property name="driver" value="oracle.jdbc.driver.OracleDriver" />
<property name="url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="username" value="louis" />
<property name="password" value="123456" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/louis/mybatis/domain/EmployeesMapper.xml"/>
</mappers>
</configuration>
3. 创建Employee实体Bean 以及配置Mapper配置文件
[java] view
plain copy
package com.louis.mybatis.model;
import java.math.BigDecimal;
public class Employee {
private Integer employeeId;
private String firstName;
private String lastName;
private String email;
private BigDecimal salary;
public Integer getEmployeeId() {
return employeeId;
}
public void setEmployeeId(Integer employeeId) {
this.employeeId = employeeId;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public BigDecimal getSalary() {
return salary;
}
public void setSalary(BigDecimal salary) {
this.salary = salary;
}
}
[html] view
plain copy
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.louis.mybatis.dao.EmployeesMapper" >
<resultMap id="BaseResultMap" type="com.louis.mybatis.model.Employee" >
<id column="EMPLOYEE_ID" property="employeeId" jdbcType="DECIMAL" />
<result column="FIRST_NAME" property="firstName" jdbcType="VARCHAR" />
<result column="LAST_NAME" property="lastName" jdbcType="VARCHAR" />
<result column="EMAIL" property="email" jdbcType="VARCHAR" />
<result column="SALARY" property="salary" jdbcType="DECIMAL" />
</resultMap>
<select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.lang.Integer" >
select
EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY
from LOUIS.EMPLOYEES
where EMPLOYEE_ID = #{employeeId,jdbcType=DECIMAL}
</select>
</mapper>
4. 创建eclipse 或者myeclipse 的maven项目,maven配置如下:
[html] view
plain copy
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>batis</groupId>
<artifactId>batis</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>batis</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.2.7</version>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc14</artifactId>
<version>10.2.0.4.0</version>
</dependency>
</dependencies>
</project>
5. 客户端代码:
[java] view
plain copy
package com.louis.mybatis.test;
import java.io.InputStream;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import com.louis.mybatis.model.Employee;
/**
* SqlSession 简单查询演示类
* @author louluan
*/
public class SelectDemo {
public static void main(String[] args) throws Exception {
/*
* 1.加载mybatis的配置文件,初始化mybatis,创建出SqlSessionFactory,是创建SqlSession的工厂
* 这里只是为了演示的需要,SqlSessionFactory临时创建出来,在实际的使用中,SqlSessionFactory只需要创建一次,当作单例来使用
*/
InputStream inputStream = Resources.getResourceAsStream("mybatisConfig.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(inputStream);
//2. 从SqlSession工厂 SqlSessionFactory中创建一个SqlSession,进行数据库操作
SqlSession sqlSession = factory.openSession();
//3.使用SqlSession查询
Map<String,Object> params = new HashMap<String,Object>();
params.put("min_salary",10000);
//a.查询工资低于10000的员工
List<Employee> result = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",params);
//b.未传最低工资,查所有员工
List<Employee> result1 = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary");
System.out.println("薪资低于10000的员工数:"+result.size());
//~output : 查询到的数据总数:5
System.out.println("所有员工数: "+result1.size());
//~output : 所有员工数: 8
}
}
plain copy
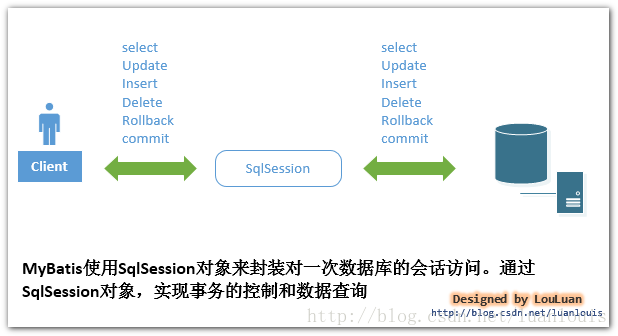
SqlSession sqlSession = factory.openSession();
MyBatis封装了对数据库的访问,把对数据库的会话和事务控制放到了SqlSession对象中。
2. 为SqlSession传递一个配置的Sql语句
[java] view
plain copy
List<Employee> result = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",params);
上述的"com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",是配置在EmployeesMapper.xml 的Statement
ID,params 是传递的查询参数。
让我们来看一下sqlSession.selectList()方法的定义:
[java] view
plain copy
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//1.根据Statement Id,在mybatis 配置对象Configuration中查找和配置文件相对应的MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
//2. 将查询任务委托给MyBatis 的执行器 Executor
List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
return result;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
MyBatis在初始化的时候,会将MyBatis的配置信息全部加载到内存中,使用org.apache.ibatis.session.Configuration实例来维护。使用者可以使用sqlSession.getConfiguration()方法来获取。MyBatis的配置文件中配置信息的组织格式和内存中对象的组织格式几乎完全对应的。上述例子中的
[html] view
plain copy
<select id="selectByMinSalary" resultMap="BaseResultMap" parameterType="java.util.Map" >
select
EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY
from LOUIS.EMPLOYEES
<if test="min_salary != null">
where SALARY < #{min_salary,jdbcType=DECIMAL}
</if>
</select>
加载到内存中会生成一个对应的MappedStatement对象,然后会以key="com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary" ,value为MappedStatement对象的形式维护到Configuration的一个Map中。当以后需要使用的时候,只需要通过Id值来获取就可以了。
从上述的代码中我们可以看到SqlSession的职能是:
SqlSession根据Statement ID, 在mybatis配置对象Configuration中获取到对应的MappedStatement对象,然后调用mybatis执行器来执行具体的操作。
plain copy
/**
* BaseExecutor 类部分代码
*
*/
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 1.根据具体传入的参数,动态地生成需要执行的SQL语句,用BoundSql对象表示
BoundSql boundSql = ms.getBoundSql(parameter);
// 2.为当前的查询创建一个缓存Key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@SuppressWarnings("unchecked")
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) throw new ExecutorException("Executor was closed.");
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 3.缓存中没有值,直接从数据库中读取数据
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear(); // issue #601
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache(); // issue #482
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//4. 执行查询,返回List 结果,然后 将查询的结果放入缓存之中
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
[java] view
plain copy
/**
*
*SimpleExecutor类的doQuery()方法实现
*
*/
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//5. 根据既有的参数,创建StatementHandler对象来执行查询操作
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//6. 创建java.Sql.Statement对象,传递给StatementHandler对象
stmt = prepareStatement(handler, ms.getStatementLog());
//7. 调用StatementHandler.query()方法,返回List结果集
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
上述的Executor.query()方法几经转折,最后会创建一个StatementHandler对象,然后将必要的参数传递给StatementHandler,使用StatementHandler来完成对数据库的查询,最终返回List结果集。
从上面的代码中我们可以看出,Executor的功能和作用是:
(1、根据传递的参数,完成SQL语句的动态解析,生成BoundSql对象,供StatementHandler使用;
(2、为查询创建缓存,以提高性能(具体它的缓存机制不是本文的重点,我会单独拿出来跟大家探讨,感兴趣的读者可以关注我的其他博文);
(3、创建JDBC的Statement连接对象,传递给StatementHandler对象,返回List查询结果。
4. StatementHandler对象负责设置Statement对象中的查询参数、处理JDBC返回的resultSet,将resultSet加工为List
接着上面的Executor第六步,看一下:prepareStatement() 方法的实现:
[java] view
plain copy
/**
*
*SimpleExecutor类的doQuery()方法实现
*
*/
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // 1.准备Statement对象,并设置Statement对象的参数 stmt = prepareStatement(handler, ms.getStatementLog()); // 2. StatementHandler执行query()方法,返回List结果 return handler.<E>query(stmt, resultHandler); } finally { closeStatement(stmt); } }
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection);
//对创建的Statement对象设置参数,即设置SQL 语句中 ? 设置为指定的参数
handler.parameterize(stmt);
return stmt;
}
以上我们可以总结StatementHandler对象主要完成两个工作:
(1. 对于JDBC的PreparedStatement类型的对象,创建的过程中,我们使用的是SQL语句字符串会包含
若干个? 占位符,我们其后再对占位符进行设值。
StatementHandler通过parameterize(statement)方法对Statement进行设值;
(2.StatementHandler通过List<E>
query(Statement statement, ResultHandler resultHandler)方法来完成执行Statement,和将Statement对象返回的resultSet封装成List;
plain copy
/**
* StatementHandler 类的parameterize(statement) 方法实现
*/
public void parameterize(Statement statement) throws SQLException {
//使用ParameterHandler对象来完成对Statement的设值
parameterHandler.setParameters((PreparedStatement) statement);
}
[java] view
plain copy
/**
*
*ParameterHandler类的setParameters(PreparedStatement ps) 实现
* 对某一个Statement进行设置参数
*/
public void setParameters(PreparedStatement ps) throws SQLException {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 每一个Mapping都有一个TypeHandler,根据TypeHandler来对preparedStatement进行设置参数
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) jdbcType = configuration.getJdbcTypeForNull();
// 设置参数
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
}
}
从上述的代码可以看到,StatementHandler 的parameterize(Statement) 方法调用了 ParameterHandler的setParameters(statement) 方法,
ParameterHandler的setParameters(Statement)方法负责 根据我们输入的参数,对statement对象的 ? 占位符处进行赋值。
6. StatementHandler 的List<E> query(Statement statement,
[java] view
plain copy
/**
* PreParedStatement类的query方法实现
*/
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 1.调用preparedStatemnt。execute()方法,然后将resultSet交给ResultSetHandler处理
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
//2. 使用ResultHandler来处理ResultSet
return resultSetHandler.<E> handleResultSets(ps);
}
[java] view
plain copy
/**
*ResultSetHandler类的handleResultSets()方法实现
*
*/
public List<Object> handleResultSets(Statement stmt) throws SQLException {
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
//将resultSet
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResulSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
从上述代码我们可以看出,StatementHandler的List<E> query(Statement statement, ResultHandler resultHandler)方法的实现,是调用了ResultSetHandler的handleResultSets(Statement)方法。ResultSetHandler的handleResultSets(Statement) 方法会将Statement语句执行后生成的resultSet结果集转换成List<E> 结果集:
[java] view
plain copy
//
// DefaultResultSetHandler 类的handleResultSets(Statement stmt)实现
//HANDLE RESULT SETS
//
public List<Object> handleResultSets(Statement stmt) throws SQLException {
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
//将resultSet
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResulSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
由于上述的过程时序图太过复杂,就不贴出来了,读者可以下载MyBatis源码, 使用Eclipse、Intellij IDEA、NetBeans 等IDE集成环境创建项目,Debug MyBatis源码,一步步跟踪MyBatis的实现,这样对学习MyBatis框架很有帮助~
Hibernate和Mybatis都是orm对象关系映射框架,都是用于将数据持久化的框架技术。
Hiberante较深度的封装了jdbc,对开发者写sql的能力要求的不是那么的高,我们只要通过hql语句操作对象即可完成对数据持久化的操作了。
另外hibernate可移植性好,如一个项目开始使用的是mysql数据库,但是随着业务的发展,现mysql数据库已经无法满足当前的绣球了,现在决定使用Oracle数据库,虽然sql标准定义的数据库间的sql语句差距不大,但是不同的数据库sql标准还是有差距的,那么我们手动修改起来会存在很大的困难,使用hibernate只需改变一下数据库方言即可搞定。用hibernate框架,数据库的移植变的非常方便。
但是hibernate也存在着诸多的不足,比如在实际开发过程中会生成很多不必要的sql语句耗费程序资源,优化起来也不是很方便,且对存储过程支持的也不够太强大。但是针对于hibernate它也提供了一些优化策略,比如说懒加载、缓存、策略模式等都是针对于它的优化方案。
Mybatis 也是对jdbc的封装,但是封装的没有hibernate那么深,我们可以再配置文件中写sql语句,可以根据需求定制sql语句,数据优化起来较hibernate容易很多。
Mybatis要求程序员写sql的能力要相对使用hibernate的开发人员要高的多,且可移植性也不是很好。
涉及到大数据的系统使用Mybatis比较好,因为优化较方便。涉及的数据量不是很大且对优化没有那么高,可以使用hibernate。
两者相同点
Hibernate与MyBatis都可以是通过SessionFactoryBuider由XML配置文件生成SessionFactory,然后由SessionFactory 生成Session,最后由Session来开启执行事务和SQL语句。其中SessionFactoryBuider,SessionFactory,Session的生命周期都是差不多的。
Hibernate和MyBatis都支持JDBC和JTA事务处理。
Mybatis优势
MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
MyBatis容易掌握,而Hibernate门槛较高。
Hibernate优势
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。
他人总结
Hibernate功能强大,数据库无关性好,O/R映射能力强,如果你对Hibernate相当精通,而且对Hibernate进行了适当的封装,那么你的项目整个持久层代码会相当简单,需要写的代码很少,开发速度很快,非常爽。
Hibernate的缺点就是学习门槛不低,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡取得平衡,以及怎样用好Hibernate方面需要你的经验和能力都很强才行。
iBATIS入门简单,即学即用,提供了数据库查询的自动对象绑定功能,而且延续了很好的SQL使用经验,对于没有那么高的对象模型要求的项目来说,相当完美。
iBATIS的缺点就是框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
针对高级查询,Mybatis需要手动编写SQL语句,以及ResultMap。而Hibernate有良好的映射机制,开发者无需关心SQL的生成与结果映射,可以更专注于业务流程。
MyBatis参考资料官网:https://mybatis.github.io/mybatis-3/zh/index.html
MyBatis 是支持定制 化 SQL、存储过程以及高级映射的优秀的持久层框架。MyBatis 避免了几乎所有的 JDBC 代码和手工设置参数以及抽取结果集。 MyBatis 使用简单的 XML 或注解来配置和映射基本体,将接口和 Java 的 POJOs(Plain Old Java Objects, 普通的 Java对象)映射成数据库中的记录。
原理详解:
MyBatis应用程序根据XML配置文件创建SqlSessionFactory,SqlSessionFactory在根据配置,配置来源于两个地方,一处是配置文件,一处是Java代码的注解,获取一个SqlSession。SqlSession包含了执行sql所需要的所有方法,可以通过SqlSession实例直接运行映射的sql语句,完成对数据的增删改查和事务提交等,用完之后关闭SqlSession。
优点:
1、简单易学mybatis本身就很小且简单。没有任何第三方依赖,最简单安装只要两个jar文件+配置几个sql映射文件易于学习,易于使用,通过文档和源代码,可以比较完全的掌握它的设计思路和实现。
2、灵活
mybatis不会对应用程序或者数据库的现有设计强加任何影响。 sql写在xml里,便于统一管理和优化。通过sql基本上可以实现我们不使用数据访问框架可以实现的所有功能,或许更多。
3、解除sql与程序代码的耦合
通过提供DAL层,将业务逻辑和数据访问逻辑分离,使系统的设计更清晰,更易维护,更易单元测试。sql和代码的分离,提高了可维护性。
4、提供映射标签,支持对象与数据库的orm字段关系映射
5、提供对象关系映射标签,支持对象关系组建维护
6、提供xml标签,支持编写动态sql。
缺点:
1、编写SQL语句时工作量很大,尤其是字段多、关联表多时,更是如此。2、SQL语句依赖于数据库,导致数据库移植性差,不能更换数据库。
3、框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
4、二级缓存机制不佳
MyBatis的框架设计
注:上图很大程度上参考了iteye
上的chenjc_it 所写的博文原理分析之二:框架整体设计 中的MyBatis架构体图,chenjc_it总结的非常好,赞一个!
1.接口层---和数据库交互的方式
MyBatis和数据库的交互有两种方式:a.使用传统的MyBatis提供的API;
b. 使用Mapper接口
1.1.使用传统的MyBatis提供的API
这是传统的传递Statement Id 和查询参数给SqlSession对象,使用SqlSession对象完成和数据库的交互;MyBatis提供了非常方便和简单的API,供用户实现对数据库的增删改查数据操作,以及对数据库连接信息和MyBatis自身配置信息的维护操作。
上述使用MyBatis的方法,是创建一个和数据库打交道的SqlSession对象,然后根据Statement
Id 和参数来操作数据库,这种方式固然很简单和实用,但是它不符合面向对象语言的概念和面向接口编程的编程习惯。由于面向接口的编程是面向对象的大趋势,MyBatis为了适应这一趋势,增加了第二种使用MyBatis支持接口(Interface)调用方式。
1.2. 使用Mapper接口
MyBatis将配置文件中的每一个<mapper>节点抽象为一个 Mapper 接口,而这个接口中声明的方法和跟<mapper>节点中的<select|update|delete|insert>节点项对应,即<select|update|delete|insert>节点的id值为Mapper接口中的方法名称,parameterType值表示Mapper对应方法的入参类型,而resultMap值则对应了Mapper接口表示的返回值类型或者返回结果集的元素类型。
根据MyBatis的配置规范配置好后,通过SqlSession.getMapper(XXXMapper.class) 方法,MyBatis会根据相应的接口声明的方法信息,通过动态代理机制生成一个Mapper实例,我们使用Mapper接口的某一个方法时,MyBatis会根据这个方法的方法名和参数类型,确定Statement
Id,底层还是通过SqlSession.select("statementId",parameterObject);或者SqlSession.update("statementId",parameterObject);等等来实现对数据库的操作,(至于这里的动态机制是怎样实现的,我将准备专门一片文章来讨论,敬请关注~)
MyBatis引用Mapper接口这种调用方式,纯粹是为了满足面向接口编程的需要。(其实还有一个原因是在于,面向接口的编程,使得用户在接口上可以使用注解来配置SQL语句,这样就可以脱离XML配置文件,实现“0配置”)。
2.数据处理层
数据处理层可以说是MyBatis的核心,从大的方面上讲,它要完成三个功能:a. 通过传入参数构建动态SQL语句;
b.可以使用拦截器重组SQL语句;(补充)
c.SQL语句的执行以及封装查询结果集成List<E>
2.1.参数映射和动态SQL语句生成
动态语句生成可以说是MyBatis框架非常优雅的一个设计,MyBatis通过传入的参数值,使用Ognl 来动态地构造SQL语句,使得MyBatis有很强的灵活性和扩展性。
参数映射指的是对于Java数据类型和jdbc数据类型之间的转换:这里有包括两个过程:查询阶段,我们要将java类型的数据,转换成jdbc类型的数据,通过preparedStatement.setXXX()来设值;另一个就是对resultset查询结果集的jdbcType数据转换成java数据类型。
(至于具体的MyBatis是如何动态构建SQL语句的,我将准备专门一篇文章来讨论,敬请关注~)
2.2. SQL语句的执行以及封装查询结果集成List<E>
动态SQL语句生成之后,MyBatis将执行SQL语句,并将可能返回的结果集转换成List<E> 列表。MyBatis在对结果集的处理中,支持结果集关系一对多和多对一的转换,并且有两种支持方式,一种为嵌套查询语句的查询,还有一种是嵌套结果集的查询。
3.
框架支撑层
3.1. 事务管理机制事务管理机制对于ORM框架而言是不可缺少的一部分,事务管理机制的质量也是考量一个ORM框架是否优秀的一个标准,对于数据管理机制我已经在我的博文《深入理解mybatis原理》
MyBatis事务管理机制 中有非常详细的讨论,感兴趣的读者可以点击查看。
3.2. 连接池管理机制
由于创建一个数据库连接所占用的资源比较大, 对于数据吞吐量大和访问量非常大的应用而言,连接池的设计就显得非常重要,对于连接池管理机制我已经在我的博文《深入理解mybatis原理》
Mybatis数据源与连接池 中有非常详细的讨论,感兴趣的读者可以点击查看。
3.3. 缓存机制
为了提高数据利用率和减小服务器和数据库的压力,MyBatis会对于一些查询提供会话级别的数据缓存,会将对某一次查询,放置到SqlSession中,在允许的时间间隔内,对于完全相同的查询,MyBatis会直接将缓存结果返回给用户,而不用再到数据库中查找。(至于具体的MyBatis缓存机制,我将准备专门一篇文章来讨论,敬请关注~)
3. 4. SQL语句的配置方式
传统的MyBatis配置SQL语句方式就是使用XML文件进行配置的,但是这种方式不能很好地支持面向接口编程的理念,为了支持面向接口的编程,MyBatis引入了Mapper接口的概念,面向接口的引入,对使用注解来配置SQL语句成为可能,用户只需要在接口上添加必要的注解即可,不用再去配置XML文件了,但是,目前的MyBatis只是对注解配置SQL语句提供了有限的支持,某些高级功能还是要依赖XML配置文件配置SQL语句。
4
引导层
引导层是配置和启动MyBatis配置信息的方式。MyBatis提供两种方式来引导MyBatis:基于XML配置文件的方式和基于JavaAPI的方式,读者可以参考我的另一片博文:JavaPersistence with MyBatis 3(中文版) 第二章 引导MyBatis
二、MyBatis的主要构件及其相互关系
从MyBatis代码实现的角度来看,MyBatis的主要的核心部件有以下几个:SqlSession 作为MyBatis工作的主要顶层API,表示和数据库交互的会话,完成必要数据库增删改查功能
Executor MyBatis执行器,是MyBatis 调度的核心,负责SQL语句的生成和查询缓存的维护
StatementHandler 封装了JDBC Statement操作,负责对JDBC statement 的操作,如设置参数、将Statement结果集转换成List集合。
ParameterHandler 负责对用户传递的参数转换成JDBC Statement 所需要的参数,
ResultSetHandler 负责将JDBC返回的ResultSet结果集对象转换成List类型的集合;
TypeHandler 负责java数据类型和jdbc数据类型之间的映射和转换
MappedStatement MappedStatement维护了一条<select|update|delete|insert>节点的封装,
SqlSource 负责根据用户传递的parameterObject,动态地生成SQL语句,将信息封装到BoundSql对象中,并返回
BoundSql 表示动态生成的SQL语句以及相应的参数信息
Configuration MyBatis所有的配置信息都维持在Configuration对象之中。
(注:这里只是列出了我个人认为属于核心的部件,请读者不要先入为主,认为MyBatis就只有这些部件哦!每个人对MyBatis的理解不同,分析出的结果自然会有所不同,欢迎读者提出质疑和不同的意见,我们共同探讨~)
它们的关系如下图所示:
三、从MyBatis一次select 查询语句来分析MyBatis的架构设计
一、数据准备(非常熟悉和应用过MyBatis
的读者可以迅速浏览此节即可)
1. 准备数据库数据,创建EMPLOYEES表,插入数据: [sql] view
plain copy
--创建一个员工基本信息表
create table "EMPLOYEES"(
"EMPLOYEE_ID" NUMBER(6) not null,
"FIRST_NAME" VARCHAR2(20),
"LAST_NAME" VARCHAR2(25) not null,
"EMAIL" VARCHAR2(25) not null unique,
"SALARY" NUMBER(8,2),
constraint "EMP_EMP_ID_PK" primary key ("EMPLOYEE_ID")
);
comment on table EMPLOYEES is '员工信息表';
comment on column EMPLOYEES.EMPLOYEE_ID is '员工id';
comment on column EMPLOYEES.FIRST_NAME is 'first name';
comment on column EMPLOYEES.LAST_NAME is 'last name';
comment on column EMPLOYEES.EMAIL is 'email address';
comment on column EMPLOYEES.SALARY is 'salary';
--添加数据
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (100, 'Steven', 'King', 'SKING', 24000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (101, 'Neena', 'Kochhar', 'NKOCHHAR', 17000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (102, 'Lex', 'De Haan', 'LDEHAAN', 17000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (103, 'Alexander', 'Hunold', 'AHUNOLD', 9000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (104, 'Bruce', 'Ernst', 'BERNST', 6000.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (105, 'David', 'Austin', 'DAUSTIN', 4800.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (106, 'Valli', 'Pataballa', 'VPATABAL', 4800.00);
insert into EMPLOYEES (EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY)
values (107, 'Diana', 'Lorentz', 'DLORENTZ', 4200.00);
2. 配置Mybatis的配置文件,命名为mybatisConfig.xml:
[html] view
plain copy
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC" />
<dataSource type="POOLED">
<property name="driver" value="oracle.jdbc.driver.OracleDriver" />
<property name="url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="username" value="louis" />
<property name="password" value="123456" />
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="com/louis/mybatis/domain/EmployeesMapper.xml"/>
</mappers>
</configuration>
3. 创建Employee实体Bean 以及配置Mapper配置文件
[java] view
plain copy
package com.louis.mybatis.model;
import java.math.BigDecimal;
public class Employee {
private Integer employeeId;
private String firstName;
private String lastName;
private String email;
private BigDecimal salary;
public Integer getEmployeeId() {
return employeeId;
}
public void setEmployeeId(Integer employeeId) {
this.employeeId = employeeId;
}
public String getFirstName() {
return firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getLastName() {
return lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public BigDecimal getSalary() {
return salary;
}
public void setSalary(BigDecimal salary) {
this.salary = salary;
}
}
[html] view
plain copy
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.louis.mybatis.dao.EmployeesMapper" >
<resultMap id="BaseResultMap" type="com.louis.mybatis.model.Employee" >
<id column="EMPLOYEE_ID" property="employeeId" jdbcType="DECIMAL" />
<result column="FIRST_NAME" property="firstName" jdbcType="VARCHAR" />
<result column="LAST_NAME" property="lastName" jdbcType="VARCHAR" />
<result column="EMAIL" property="email" jdbcType="VARCHAR" />
<result column="SALARY" property="salary" jdbcType="DECIMAL" />
</resultMap>
<select id="selectByPrimaryKey" resultMap="BaseResultMap" parameterType="java.lang.Integer" >
select
EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY
from LOUIS.EMPLOYEES
where EMPLOYEE_ID = #{employeeId,jdbcType=DECIMAL}
</select>
</mapper>
4. 创建eclipse 或者myeclipse 的maven项目,maven配置如下:
[html] view
plain copy
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>batis</groupId>
<artifactId>batis</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>batis</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.2.7</version>
</dependency>
<dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc14</artifactId>
<version>10.2.0.4.0</version>
</dependency>
</dependencies>
</project>
5. 客户端代码:
[java] view
plain copy
package com.louis.mybatis.test;
import java.io.InputStream;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import com.louis.mybatis.model.Employee;
/**
* SqlSession 简单查询演示类
* @author louluan
*/
public class SelectDemo {
public static void main(String[] args) throws Exception {
/*
* 1.加载mybatis的配置文件,初始化mybatis,创建出SqlSessionFactory,是创建SqlSession的工厂
* 这里只是为了演示的需要,SqlSessionFactory临时创建出来,在实际的使用中,SqlSessionFactory只需要创建一次,当作单例来使用
*/
InputStream inputStream = Resources.getResourceAsStream("mybatisConfig.xml");
SqlSessionFactoryBuilder builder = new SqlSessionFactoryBuilder();
SqlSessionFactory factory = builder.build(inputStream);
//2. 从SqlSession工厂 SqlSessionFactory中创建一个SqlSession,进行数据库操作
SqlSession sqlSession = factory.openSession();
//3.使用SqlSession查询
Map<String,Object> params = new HashMap<String,Object>();
params.put("min_salary",10000);
//a.查询工资低于10000的员工
List<Employee> result = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",params);
//b.未传最低工资,查所有员工
List<Employee> result1 = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary");
System.out.println("薪资低于10000的员工数:"+result.size());
//~output : 查询到的数据总数:5
System.out.println("所有员工数: "+result1.size());
//~output : 所有员工数: 8
}
}
二、SqlSession 的工作过程分析:
1. 开启一个数据库访问会话---创建SqlSession对象:
[java] viewplain copy
SqlSession sqlSession = factory.openSession();
MyBatis封装了对数据库的访问,把对数据库的会话和事务控制放到了SqlSession对象中。
2. 为SqlSession传递一个配置的Sql语句
的Statement Id和参数,然后返回结果:
[java] viewplain copy
List<Employee> result = sqlSession.selectList("com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",params);
上述的"com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary",是配置在EmployeesMapper.xml 的Statement
ID,params 是传递的查询参数。
让我们来看一下sqlSession.selectList()方法的定义:
[java] view
plain copy
public <E> List<E> selectList(String statement, Object parameter) {
return this.selectList(statement, parameter, RowBounds.DEFAULT);
}
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
//1.根据Statement Id,在mybatis 配置对象Configuration中查找和配置文件相对应的MappedStatement
MappedStatement ms = configuration.getMappedStatement(statement);
//2. 将查询任务委托给MyBatis 的执行器 Executor
List<E> result = executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
return result;
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
MyBatis在初始化的时候,会将MyBatis的配置信息全部加载到内存中,使用org.apache.ibatis.session.Configuration实例来维护。使用者可以使用sqlSession.getConfiguration()方法来获取。MyBatis的配置文件中配置信息的组织格式和内存中对象的组织格式几乎完全对应的。上述例子中的
[html] view
plain copy
<select id="selectByMinSalary" resultMap="BaseResultMap" parameterType="java.util.Map" >
select
EMPLOYEE_ID, FIRST_NAME, LAST_NAME, EMAIL, SALARY
from LOUIS.EMPLOYEES
<if test="min_salary != null">
where SALARY < #{min_salary,jdbcType=DECIMAL}
</if>
</select>
加载到内存中会生成一个对应的MappedStatement对象,然后会以key="com.louis.mybatis.dao.EmployeesMapper.selectByMinSalary" ,value为MappedStatement对象的形式维护到Configuration的一个Map中。当以后需要使用的时候,只需要通过Id值来获取就可以了。
从上述的代码中我们可以看到SqlSession的职能是:
SqlSession根据Statement ID, 在mybatis配置对象Configuration中获取到对应的MappedStatement对象,然后调用mybatis执行器来执行具体的操作。
3.MyBatis执行器Executor根据SqlSession传递的参数执行query()方法(由于代码过长,读者只需阅读我注释的地方即可):
[java] viewplain copy
/**
* BaseExecutor 类部分代码
*
*/
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
// 1.根据具体传入的参数,动态地生成需要执行的SQL语句,用BoundSql对象表示
BoundSql boundSql = ms.getBoundSql(parameter);
// 2.为当前的查询创建一个缓存Key
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
@SuppressWarnings("unchecked")
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) throw new ExecutorException("Executor was closed.");
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
// 3.缓存中没有值,直接从数据库中读取数据
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
deferredLoads.clear(); // issue #601
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
clearLocalCache(); // issue #482
}
}
return list;
}
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
//4. 执行查询,返回List 结果,然后 将查询的结果放入缓存之中
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
localCache.removeObject(key);
}
localCache.putObject(key, list);
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
[java] view
plain copy
/**
*
*SimpleExecutor类的doQuery()方法实现
*
*/
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
//5. 根据既有的参数,创建StatementHandler对象来执行查询操作
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
//6. 创建java.Sql.Statement对象,传递给StatementHandler对象
stmt = prepareStatement(handler, ms.getStatementLog());
//7. 调用StatementHandler.query()方法,返回List结果集
return handler.<E>query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
上述的Executor.query()方法几经转折,最后会创建一个StatementHandler对象,然后将必要的参数传递给StatementHandler,使用StatementHandler来完成对数据库的查询,最终返回List结果集。
从上面的代码中我们可以看出,Executor的功能和作用是:
(1、根据传递的参数,完成SQL语句的动态解析,生成BoundSql对象,供StatementHandler使用;
(2、为查询创建缓存,以提高性能(具体它的缓存机制不是本文的重点,我会单独拿出来跟大家探讨,感兴趣的读者可以关注我的其他博文);
(3、创建JDBC的Statement连接对象,传递给StatementHandler对象,返回List查询结果。
4. StatementHandler对象负责设置Statement对象中的查询参数、处理JDBC返回的resultSet,将resultSet加工为List
集合返回:
接着上面的Executor第六步,看一下:prepareStatement() 方法的实现:[java] view
plain copy
/**
*
*SimpleExecutor类的doQuery()方法实现
*
*/
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException { Statement stmt = null; try { Configuration configuration = ms.getConfiguration(); StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql); // 1.准备Statement对象,并设置Statement对象的参数 stmt = prepareStatement(handler, ms.getStatementLog()); // 2. StatementHandler执行query()方法,返回List结果 return handler.<E>query(stmt, resultHandler); } finally { closeStatement(stmt); } }
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection);
//对创建的Statement对象设置参数,即设置SQL 语句中 ? 设置为指定的参数
handler.parameterize(stmt);
return stmt;
}
以上我们可以总结StatementHandler对象主要完成两个工作:
(1. 对于JDBC的PreparedStatement类型的对象,创建的过程中,我们使用的是SQL语句字符串会包含
若干个? 占位符,我们其后再对占位符进行设值。
StatementHandler通过parameterize(statement)方法对Statement进行设值;
(2.StatementHandler通过List<E>
query(Statement statement, ResultHandler resultHandler)方法来完成执行Statement,和将Statement对象返回的resultSet封装成List;
5. StatementHandler 的parameterize(statement) 方法的实现:
[java] viewplain copy
/**
* StatementHandler 类的parameterize(statement) 方法实现
*/
public void parameterize(Statement statement) throws SQLException {
//使用ParameterHandler对象来完成对Statement的设值
parameterHandler.setParameters((PreparedStatement) statement);
}
[java] view
plain copy
/**
*
*ParameterHandler类的setParameters(PreparedStatement ps) 实现
* 对某一个Statement进行设置参数
*/
public void setParameters(PreparedStatement ps) throws SQLException {
ErrorContext.instance().activity("setting parameters").object(mappedStatement.getParameterMap().getId());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings != null) {
for (int i = 0; i < parameterMappings.size(); i++) {
ParameterMapping parameterMapping = parameterMappings.get(i);
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) { // issue #448 ask first for additional params
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
// 每一个Mapping都有一个TypeHandler,根据TypeHandler来对preparedStatement进行设置参数
TypeHandler typeHandler = parameterMapping.getTypeHandler();
JdbcType jdbcType = parameterMapping.getJdbcType();
if (value == null && jdbcType == null) jdbcType = configuration.getJdbcTypeForNull();
// 设置参数
typeHandler.setParameter(ps, i + 1, value, jdbcType);
}
}
}
}
从上述的代码可以看到,StatementHandler 的parameterize(Statement) 方法调用了 ParameterHandler的setParameters(statement) 方法,
ParameterHandler的setParameters(Statement)方法负责 根据我们输入的参数,对statement对象的 ? 占位符处进行赋值。
6. StatementHandler 的List<E> query(Statement statement,
ResultHandler resultHandler)方法的实现:
[java] viewplain copy
/**
* PreParedStatement类的query方法实现
*/
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
// 1.调用preparedStatemnt。execute()方法,然后将resultSet交给ResultSetHandler处理
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
//2. 使用ResultHandler来处理ResultSet
return resultSetHandler.<E> handleResultSets(ps);
}
[java] view
plain copy
/**
*ResultSetHandler类的handleResultSets()方法实现
*
*/
public List<Object> handleResultSets(Statement stmt) throws SQLException {
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
//将resultSet
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResulSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
从上述代码我们可以看出,StatementHandler的List<E> query(Statement statement, ResultHandler resultHandler)方法的实现,是调用了ResultSetHandler的handleResultSets(Statement)方法。ResultSetHandler的handleResultSets(Statement) 方法会将Statement语句执行后生成的resultSet结果集转换成List<E> 结果集:
[java] view
plain copy
//
// DefaultResultSetHandler 类的handleResultSets(Statement stmt)实现
//HANDLE RESULT SETS
//
public List<Object> handleResultSets(Statement stmt) throws SQLException {
final List<Object> multipleResults = new ArrayList<Object>();
int resultSetCount = 0;
ResultSetWrapper rsw = getFirstResultSet(stmt);
List<ResultMap> resultMaps = mappedStatement.getResultMaps();
int resultMapCount = resultMaps.size();
validateResultMapsCount(rsw, resultMapCount);
while (rsw != null && resultMapCount > resultSetCount) {
ResultMap resultMap = resultMaps.get(resultSetCount);
//将resultSet
handleResultSet(rsw, resultMap, multipleResults, null);
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
String[] resultSets = mappedStatement.getResulSets();
if (resultSets != null) {
while (rsw != null && resultSetCount < resultSets.length) {
ResultMapping parentMapping = nextResultMaps.get(resultSets[resultSetCount]);
if (parentMapping != null) {
String nestedResultMapId = parentMapping.getNestedResultMapId();
ResultMap resultMap = configuration.getResultMap(nestedResultMapId);
handleResultSet(rsw, resultMap, null, parentMapping);
}
rsw = getNextResultSet(stmt);
cleanUpAfterHandlingResultSet();
resultSetCount++;
}
}
return collapseSingleResultList(multipleResults);
}
由于上述的过程时序图太过复杂,就不贴出来了,读者可以下载MyBatis源码, 使用Eclipse、Intellij IDEA、NetBeans 等IDE集成环境创建项目,Debug MyBatis源码,一步步跟踪MyBatis的实现,这样对学习MyBatis框架很有帮助~
Hibernate和Mybatis都是orm对象关系映射框架,都是用于将数据持久化的框架技术。
Hiberante较深度的封装了jdbc,对开发者写sql的能力要求的不是那么的高,我们只要通过hql语句操作对象即可完成对数据持久化的操作了。
另外hibernate可移植性好,如一个项目开始使用的是mysql数据库,但是随着业务的发展,现mysql数据库已经无法满足当前的绣球了,现在决定使用Oracle数据库,虽然sql标准定义的数据库间的sql语句差距不大,但是不同的数据库sql标准还是有差距的,那么我们手动修改起来会存在很大的困难,使用hibernate只需改变一下数据库方言即可搞定。用hibernate框架,数据库的移植变的非常方便。
但是hibernate也存在着诸多的不足,比如在实际开发过程中会生成很多不必要的sql语句耗费程序资源,优化起来也不是很方便,且对存储过程支持的也不够太强大。但是针对于hibernate它也提供了一些优化策略,比如说懒加载、缓存、策略模式等都是针对于它的优化方案。
Mybatis 也是对jdbc的封装,但是封装的没有hibernate那么深,我们可以再配置文件中写sql语句,可以根据需求定制sql语句,数据优化起来较hibernate容易很多。
Mybatis要求程序员写sql的能力要相对使用hibernate的开发人员要高的多,且可移植性也不是很好。
涉及到大数据的系统使用Mybatis比较好,因为优化较方便。涉及的数据量不是很大且对优化没有那么高,可以使用hibernate。
两者相同点
Hibernate与MyBatis都可以是通过SessionFactoryBuider由XML配置文件生成SessionFactory,然后由SessionFactory 生成Session,最后由Session来开启执行事务和SQL语句。其中SessionFactoryBuider,SessionFactory,Session的生命周期都是差不多的。
Hibernate和MyBatis都支持JDBC和JTA事务处理。
Mybatis优势
MyBatis可以进行更为细致的SQL优化,可以减少查询字段。
MyBatis容易掌握,而Hibernate门槛较高。
Hibernate优势
Hibernate的DAO层开发比MyBatis简单,Mybatis需要维护SQL和结果映射。
Hibernate对对象的维护和缓存要比MyBatis好,对增删改查的对象的维护要方便。
Hibernate数据库移植性很好,MyBatis的数据库移植性不好,不同的数据库需要写不同SQL。
Hibernate有更好的二级缓存机制,可以使用第三方缓存。MyBatis本身提供的缓存机制不佳。
他人总结
Hibernate功能强大,数据库无关性好,O/R映射能力强,如果你对Hibernate相当精通,而且对Hibernate进行了适当的封装,那么你的项目整个持久层代码会相当简单,需要写的代码很少,开发速度很快,非常爽。
Hibernate的缺点就是学习门槛不低,要精通门槛更高,而且怎么设计O/R映射,在性能和对象模型之间如何权衡取得平衡,以及怎样用好Hibernate方面需要你的经验和能力都很强才行。
iBATIS入门简单,即学即用,提供了数据库查询的自动对象绑定功能,而且延续了很好的SQL使用经验,对于没有那么高的对象模型要求的项目来说,相当完美。
iBATIS的缺点就是框架还是比较简陋,功能尚有缺失,虽然简化了数据绑定代码,但是整个底层数据库查询实际还是要自己写的,工作量也比较大,而且不太容易适应快速数据库修改。
针对高级查询,Mybatis需要手动编写SQL语句,以及ResultMap。而Hibernate有良好的映射机制,开发者无需关心SQL的生成与结果映射,可以更专注于业务流程。

相关文章推荐
- Mybatis原理,优缺点,以及与Hibernate的比较
- LVS 三种工作模式原理、以及优缺点比较
- LVS 三种工作模式原理、以及优缺点比较
- LVS 三种工作模式原理、以及优缺点比较
- LVS 三种工作模式原理、以及优缺点比较
- ibatis与hibernate的优缺点以及实用性功能比较
- LVS 三种工作模式原理、以及优缺点比较
- Hibernate与 MyBatis的比较
- Ajax原理以及优缺点
- 常见加密算法分,用途,原理以及比较
- hibernate和mybatis的比较
- Hibernate VS MyBatis 区别 Hibernate3和MyBatis(iBatis)的执行效率比较
- Hibernate VS MyBatis 区别 Hibernate3和MyBatis(iBatis)的执行效率比较
- 解析xml的几种方法,他们的原理,比较 以及JAVA源码
- Hibernate与 MyBatis的比较
- jdbc与hibernate的优缺点比较
- hibernate数据状态以及更改数据状态的方法比较
- Hibernate和JDBC的区别以及它们各自的优缺点
- Hibernate与 MyBatis的比较
- Hibernate与 MyBatis的比较