ROC,AUC,PR,AP介绍及python绘制
2017-04-19 17:46
302 查看
这里介绍一下如题所述的四个概念以及相应的使用python绘制曲线:
参考博客:http://kubicode.me/2016/09/19/Machine%20Learning/AUC-Calculation-by-Python/?utm_source=tuicool&utm_medium=referral
一般我们在评判一个分类模型的好坏时,一般使用MAP值来衡量,MAP越接近1,模型效果越好;


更详细的可参考:http://www.cnblogs.com/pinard/p/5993450.html
准确率pr就是找得对,召回率rc就是找得全。
大概就是你问问一个模型,这堆东西是不是某个类的时候,准确率就是 它说是,这东西就确实是的概率吧,召回率就是, 它说是,但它漏说了(1-召回率)这么多。
(这里的P=FN+TP;N=TN+FP;而这里recall=tp rate;上述链接里的特异性其实就是fp rate)
AUC和AP分别是ROC和PR曲线下面积,map就是每个类的ap的平均值;python代码(IDE是jupyter notebook):
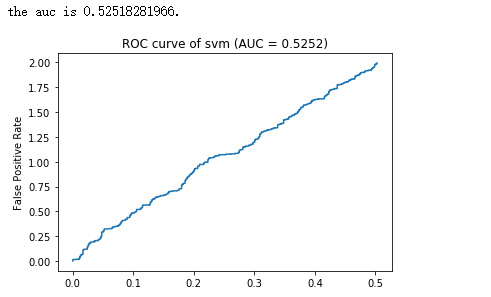
结果:
这里的.txt文件格式如:http://kubicode.me/img/AUC-Calculation-by-Python/evaluate_result.txt
形式为:

PS:该txt文件表示的意思是,比如对于第一行就是说:有一个样本得分为0.86...,并被预测为负样本;倒数第一行就是说,这么多测试样本中,有一个样本得分为0.45...,并被预测为正样本;
注意:绘制ROC和PR曲线时都是设定不同的阈值来获得对应的坐标,从而画出曲线
代码中:
代码中首先使用
对于PR曲线也一样,只不过横坐标换成

,纵坐标换成

,AP是其曲线下面积;
上面的python代码针对二分类模型,但针对多分类模型时一样,即对于每个类都将其看做正样本,其他类看成负样本来画曲线,这样有多少类就画多少条相应的曲线,MAp值即为各类ap值的平均值;
参考博客:http://kubicode.me/2016/09/19/Machine%20Learning/AUC-Calculation-by-Python/?utm_source=tuicool&utm_medium=referral
一般我们在评判一个分类模型的好坏时,一般使用MAP值来衡量,MAP越接近1,模型效果越好;
更详细的可参考:http://www.cnblogs.com/pinard/p/5993450.html
准确率pr就是找得对,召回率rc就是找得全。
大概就是你问问一个模型,这堆东西是不是某个类的时候,准确率就是 它说是,这东西就确实是的概率吧,召回率就是, 它说是,但它漏说了(1-召回率)这么多。
(这里的P=FN+TP;N=TN+FP;而这里recall=tp rate;上述链接里的特异性其实就是fp rate)
AUC和AP分别是ROC和PR曲线下面积,map就是每个类的ap的平均值;python代码(IDE是jupyter notebook):
#绘制二分类ROC曲线
import pylab as pl
%matplotlib inline
from math import log,exp,sqrt
evaluate_result = "D:/python_sth/1.txt"
db = []
pos , neg = 0 , 0
with open(evaluate_result , 'r') as fs:
for line in fs:
nonclk , clk , score = line.strip().split('\t')
nonclk = int(nonclk)
clk = int(clk)
score = float(score)
db.append([score , nonclk , clk])
pos += clk
neg += nonclk
db = sorted(db , key = lambda x:x[0] , reverse = True) #降序
#计算ROC坐标点
xy_arr = []
tp , fp = 0. , 0.
for i in range(len(db)):
tp += db[i][2]
fp += db[i][1]
xy_arr.append([tp/neg , fp/pos])
#计算曲线下面积即AUC
auc = 0.
prev_x = 0
for x ,y in xy_arr:
if x != prev_x:
auc += (x - prev_x) * y
prev_x = x
print "the auc is %s."%auc
x = [_v[0] for _v in xy_arr]
y = [_v[1] for _v in xy_arr]
pl.title("ROC curve of %s (AUC = %.4f)" % ('svm' , auc))
pl.ylabel("False Positive Rate")
pl.plot(x ,y)
pl.show()结果:
这里的.txt文件格式如:http://kubicode.me/img/AUC-Calculation-by-Python/evaluate_result.txt
形式为:
PS:该txt文件表示的意思是,比如对于第一行就是说:有一个样本得分为0.86...,并被预测为负样本;倒数第一行就是说,这么多测试样本中,有一个样本得分为0.45...,并被预测为正样本;
注意:绘制ROC和PR曲线时都是设定不同的阈值来获得对应的坐标,从而画出曲线
代码中:
nonclick:未点击的数据,可以看做负样本的数量
clk:点击的数量,可以看做正样本的数量
score:预测的分数,以该分数为group进行正负样本的预统计可以减少
AUC的计算量
代码中首先使用
db = sorted(db , key = lambda x:x[0] , reverse = True) 进行降序排序,然后将每一个从小到大的得分值作为阈值,每次得到一个fpr和tpr(因为最后得分大于阈值,就认为它是正样本,所以若.txt中得分为某一个阈值时nonclk为非0的数,而clk是0,则认为nonclk的值大小的样本是fp样本),最后画出曲线;
对于PR曲线也一样,只不过横坐标换成
,纵坐标换成
,AP是其曲线下面积;
上面的python代码针对二分类模型,但针对多分类模型时一样,即对于每个类都将其看做正样本,其他类看成负样本来画曲线,这样有多少类就画多少条相应的曲线,MAp值即为各类ap值的平均值;

相关文章推荐
- ROC,AUC,PR,AP及python绘制
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC<转>
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍-准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍-准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍-准确率、召回率、F1、mAP、ROC、AUC
- ROC和AUC介绍以及如何计算AUC
- how to draw Opencv face detection Adaboost ROC/PR (绘制方法)
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍-准确率、召回率、F1、mAP、ROC、AUC
- ROC和AUC介绍以及如何计算AUC
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍 - 准确率、召回率、F1、mAP、ROC、AUC
- 信息检索(IR)的评价指标介绍-准确率、召回率、F1、mAP、ROC、AUC
- ROC和AUC介绍以及如何计算AUC
- ROC和AUC介绍以及如何计算AUC