李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
2017-04-16 18:18
656 查看
台湾大学李宏毅老师的机器学习课程是一份非常好的ML/DL入门资料,李宏毅老师将课程录像上传到了YouTube,地址:NTUEE ML 2016 。
这篇文章是学习本课程第16-18课所做的笔记和自己的理解。
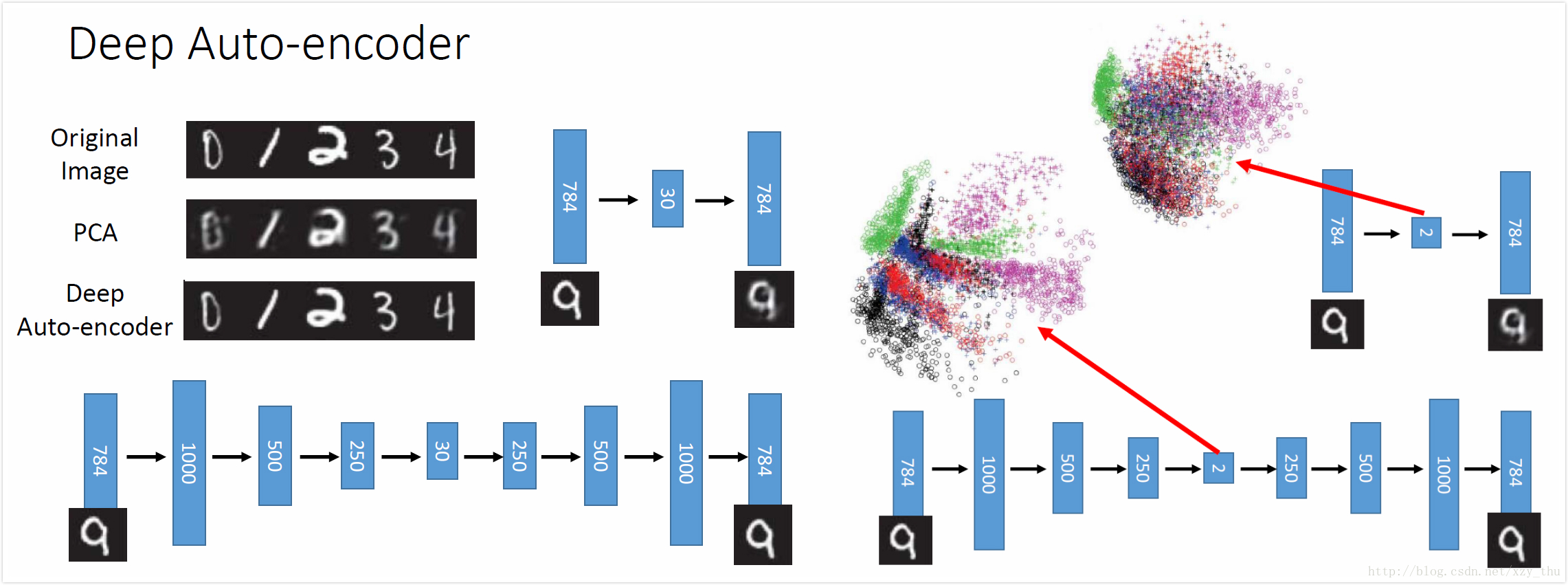
PCA降维可视为得到了精简表达code,图中input image已去均值。中间那层之所以叫瓶颈层是因为它很窄。
auto-encoder可以有多个隐层,中间的窄层的输出就是code。在PCA中前后系数是tie在一起的(可以减少参数数目,防止overfitting),但是并不必要,直接用BP训练即可。

下图是Hinton原始论文中的结果:PCA把784维降到30维再恢复到784维,deep auto-encoder结构见下。如果用PCA降到2维,则digits都混在一起,而deep auto-encoder降到2维可以把digits分开。
一种方法是词袋,但是这种方法中每个词都独立,不能知道语意。
要把语意考虑进来的话,要用Auto-encoder。词袋经过auto-encoder之后得到code。下图中不同颜色代表文档的不同种类。
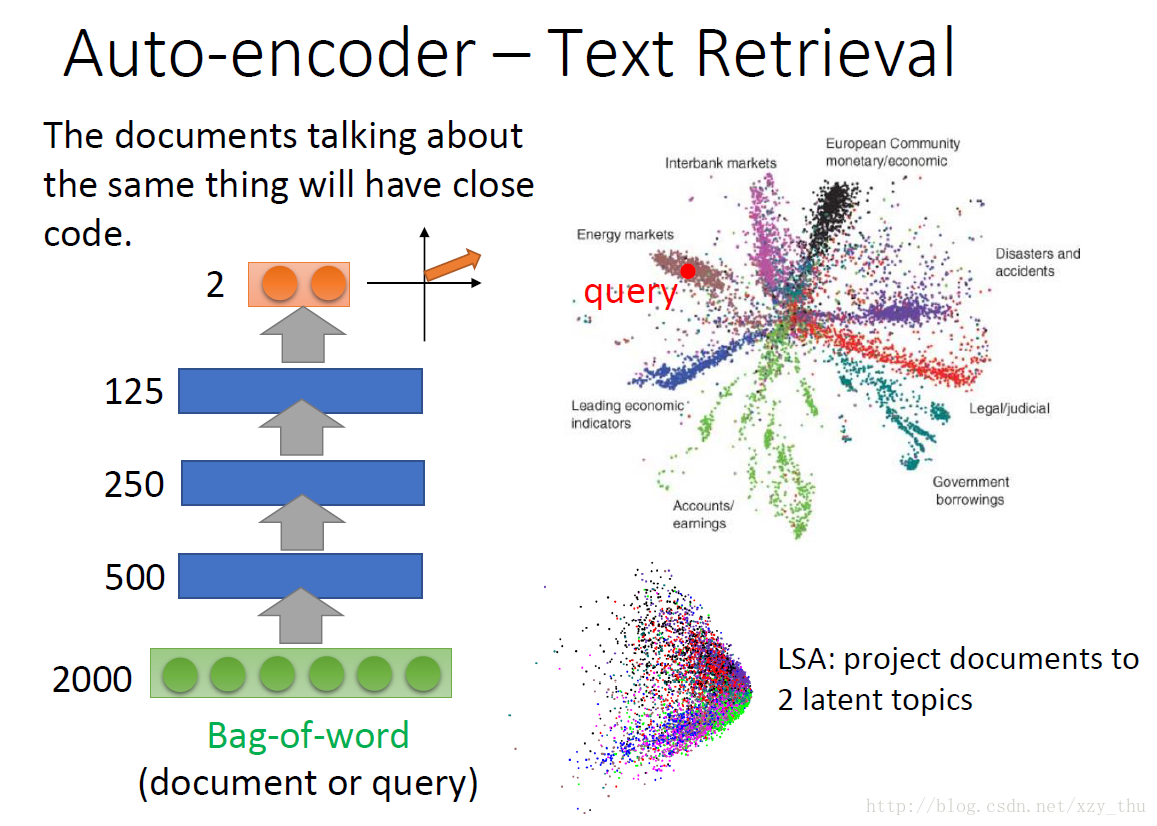
而把image经过auto-encoder变成code,基于code计算相似度,结果就会好很多。
预训练过程:

在训练第一个auto-encoder时,由于hidden layer的维数大于input维数,要加很强的正则项,e.g.对1000维的output做L1正则化(希望output稀疏)。否则hidden layer可能直接记住input,没有learn到任何东西。
在训练第二个auto-encoder时,要把database中所有digit都变成1000维vector。
以此类推,最后随机初始化输出层之前的权重。然后用BP做fine-tune(W1,W2,W3已经很好,微调即可)。
之前在训练较深的NN时要用到预训练,但是现在没必要了,因为训练技术进步了。
但在有大量unlabelled data、少量labelled data时仍需要预训练,可以先用大量无标注数据先把W1,W2,W3先learn好,最后的labelled data只需稍微调整weight就好。
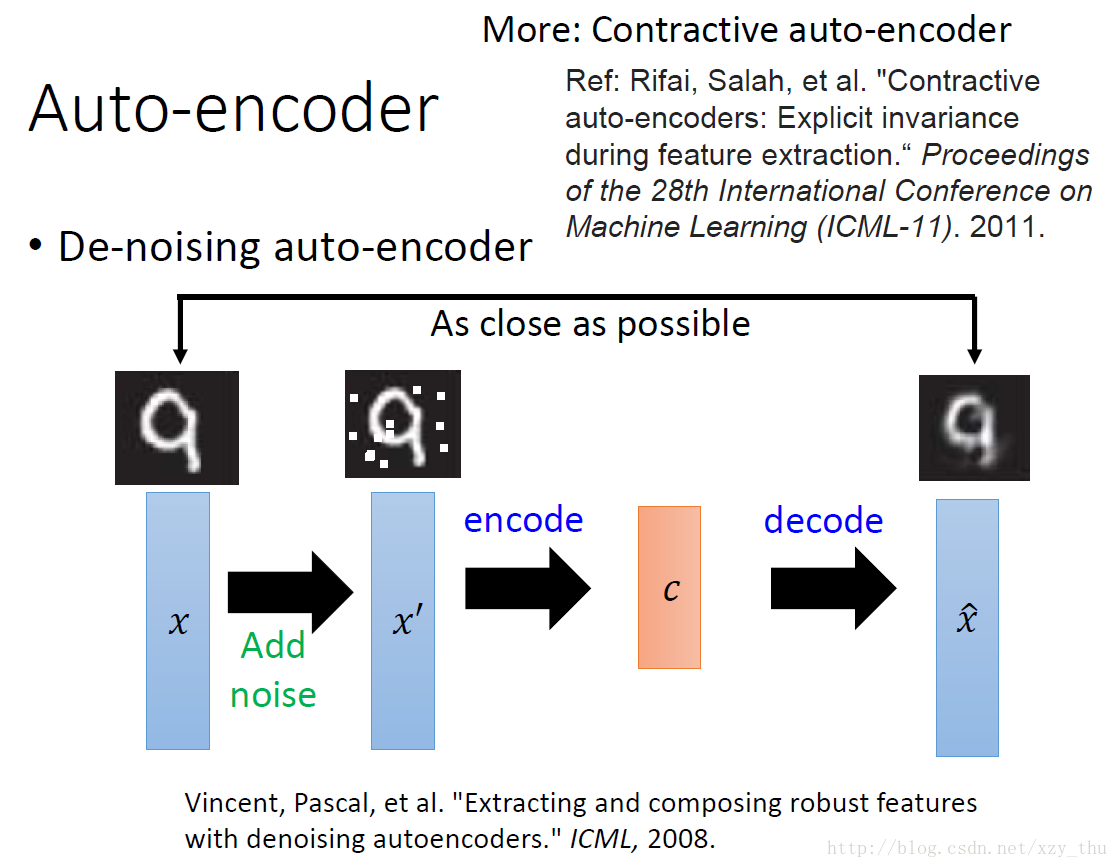
De-noising auto-encoder得到的结果会比较鲁棒。
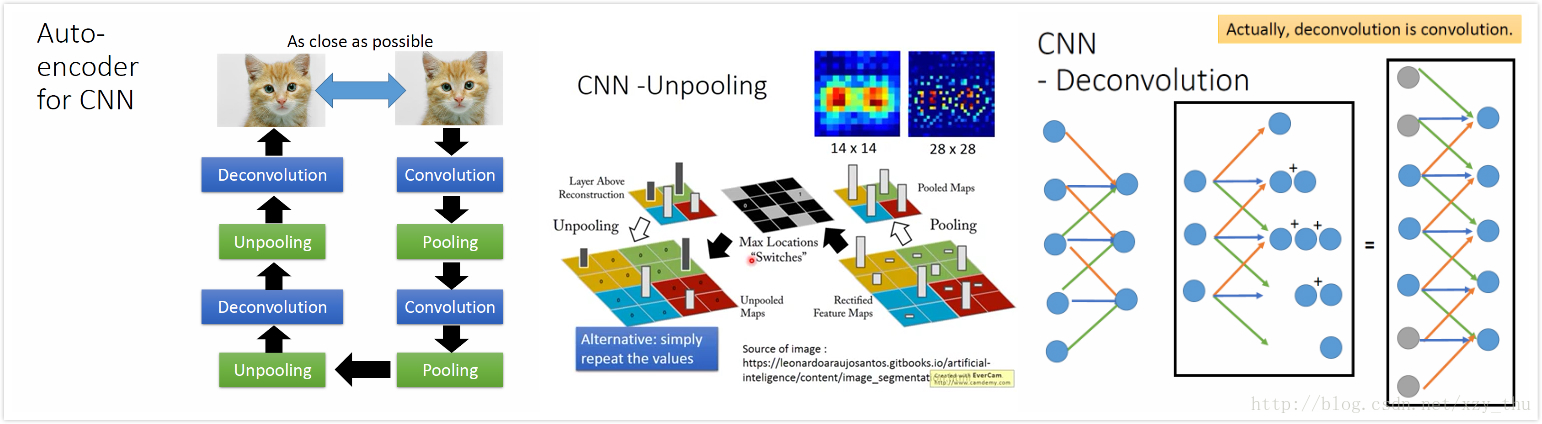
unpooling: 在pooling的时候记得从哪里取的值,unpooling的时候对应位置恢复,其余位置补0。
Keras中unpooling是直接把pooling后的每个值复制4份。
deconvolution: 其实就是convolution。

784维降到2维,根据vector的分布选择红框,在红框中等间隔采样,作为decoder的input,得到计算机生成的图片。
如果红框选错了位置,比如选在右下方,可能得不到数字。
“需知道vector分布”略麻烦,改进方法:加正则化。
在训练时,对code加L2正则化,这样code比较接近0。采样时在0附近采样,这样采样得到的vector比较有可能都对应数字。
用在图像上有一些tips: 如果RGB三个值相差不大,则得到的颜色灰灰的、不够明亮,可以把众多颜色聚成若干类然后做1-of-N encoding。
如果要计算机从空白开始画,要给一个随机数,以免每次画出来的都一样。
VAE的结构:
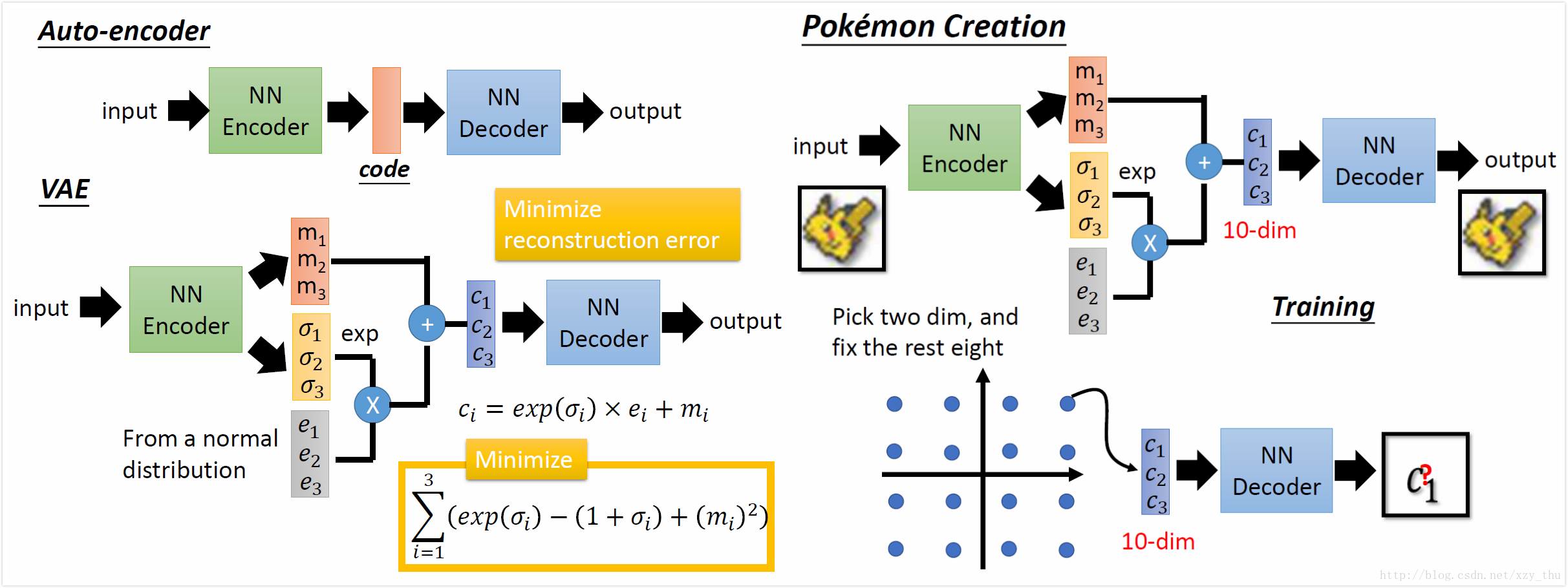
VAE得到的结果不太清楚。VAE与PixelRNN区别在于,理论上VAE可以控制要生成的image。
比如code是10维,固定其中8维、调整剩余2维,看结果,可以解读code的每个维度代表什么意思,从而每个维度就像拉杆一样可以有目的的调整。
用VAE写“诗”:先胡乱选两个句子,经过encoder得到这两个句子的code,在code space上是两个点,连接两点、等距采样、用decoder还原,得到一系列句子。
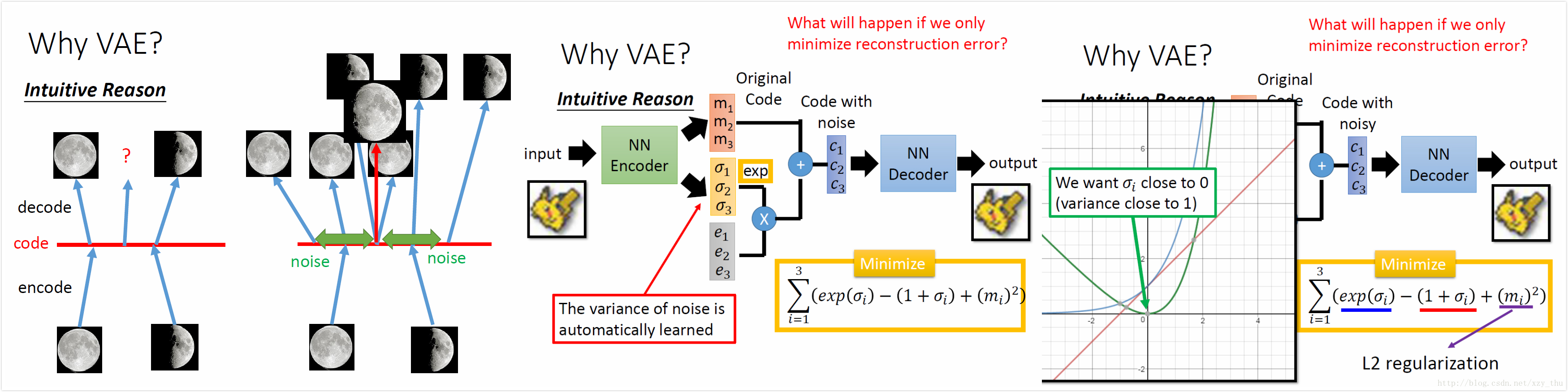
为什么要用VAE?一个intuitive的解释是,auto-encoder的encoder与decoder都是非线性的,很难预测问号处是一张介于满月与弦月之间的图像。VAE使得code加上noise之后还能恢复出来,这样问号处既希望恢复出满月、又希望恢复出弦月,最后得到介于满月与弦月之间的图像,既像满月又像弦月。
VAE是在encoder output上加noise,而De-noising auto-encoder是在encoder input上加noise。
如果只最小化重构误差,那么train出来的结果不会是预期的样子,因为variance是学出来的,会学成0。
exp是为了确保variance是正的,右下方的minimize是为了让variance不能太小,其中第一项为蓝色曲线、第二项为红色曲线、二者相减得绿色曲线,这样variance最小为1,第三项是L2正则化,希望参数稀疏避免过拟合。
从数学上解释,VAE是GMM的Distributed representation版本。
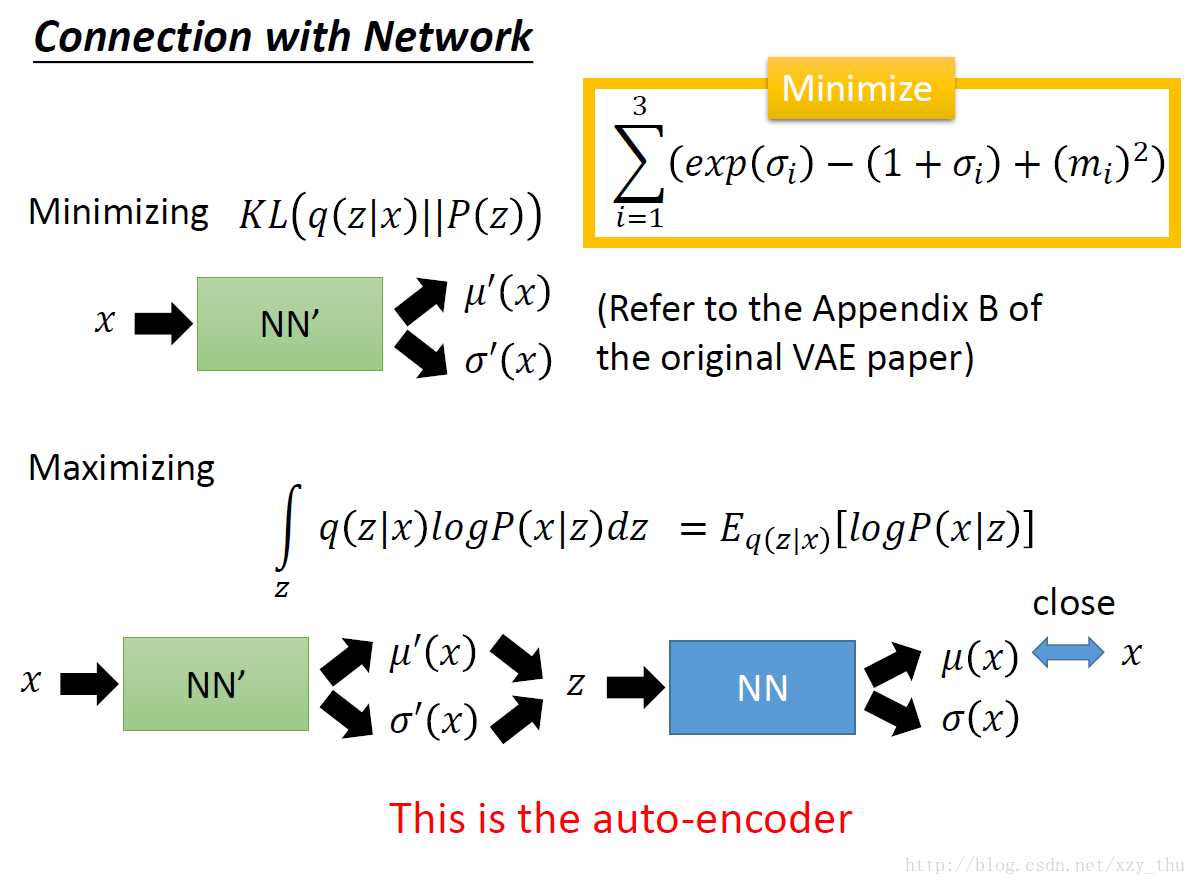
要最大化似然函数,似然函数可以拆成下界与KL距离。
下界与两个量有关:P(x|z),q(z|x),下界变大不一定使似然函数变大。要让KL最小,那么下界就是似然函数,得到q(z|x)=p(z|x).
下界又可以拆成两项(一个负的KL距离+一个积分),与网络联系起来:
最小化的那个式子就是要最小化这个KL距离,使得encoder产生的code z 的分布与normal distribution P(z) 越接近越好。

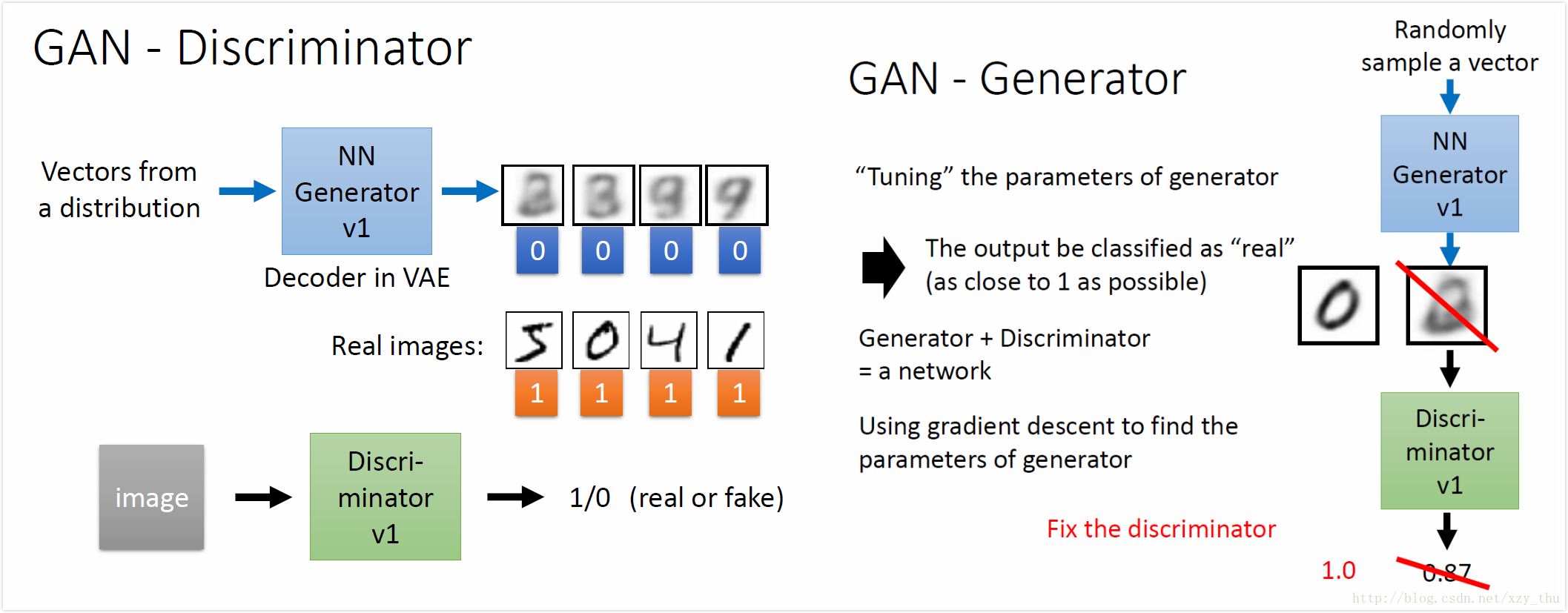
Discriminator判断image是Generator产生的还是real images, Generator根据Discriminator演化。
Generator从未看过real images, 产生的是database中没有见过的image。
训练:
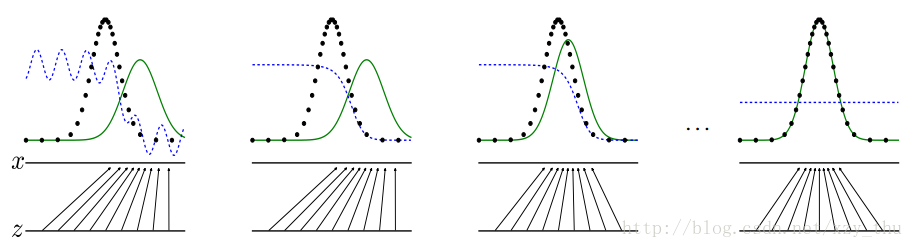
例子(黑点:real,绿线:Generator,蓝线:Discriminator):
实际中的问题:

Basic tutorial:
An introduction to Generative Adversarial Networks (with code in TensorFlow)
Image Completion with Deep Learning in TensorFlow
Generative Adversarial Nets in TensorFlow
李宏毅机器学习课程笔记
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
李宏毅机器学习课程笔记2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅机器学习课程笔记3:Backpropagation、”Hello world” of Deep Learning、Tips for Training DNN
李宏毅机器学习课程笔记4:CNN、Why Deep、Semi-supervised
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅机器学习课程笔记8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅机器学习课程笔记9:Recurrent Neural Network
李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning
这篇文章是学习本课程第16-18课所做的笔记和自己的理解。
Lecture 16: Unsupervised Learning - Auto-encoder
Auto-encoder
在手写数字识别任务中,想训练一个NN encoder,得到图像的精简表达。但做的是无监督学习,可以找到很多input image,但是不知道code该长什么样,所以没法learn。所以又提出一个NN decoder(也没法单独learn),把encoder与decoder连接在一起learn。PCA降维可视为得到了精简表达code,图中input image已去均值。中间那层之所以叫瓶颈层是因为它很窄。
auto-encoder可以有多个隐层,中间的窄层的输出就是code。在PCA中前后系数是tie在一起的(可以减少参数数目,防止overfitting),但是并不必要,直接用BP训练即可。
下图是Hinton原始论文中的结果:PCA把784维降到30维再恢复到784维,deep auto-encoder结构见下。如果用PCA降到2维,则digits都混在一起,而deep auto-encoder降到2维可以把digits分开。
Auto-encoder应用于文字处理
把文章变成一个code,得到vector space model,把查询词汇也变成一个vector,从而进行查询。一种方法是词袋,但是这种方法中每个词都独立,不能知道语意。
要把语意考虑进来的话,要用Auto-encoder。词袋经过auto-encoder之后得到code。下图中不同颜色代表文档的不同种类。
Auto-encoder应用于以图找图
如果基于像素计算图片之间相似度的话,得到的结果会比较差。比如,会得到迈克尔杰克逊的照片比较像马蹄铁。而把image经过auto-encoder变成code,基于code计算相似度,结果就会好很多。
Auto-encoder用于预训练DNN
为了在训练NN时找到一组好的初始值,要用到预训练。预训练过程:
在训练第一个auto-encoder时,由于hidden layer的维数大于input维数,要加很强的正则项,e.g.对1000维的output做L1正则化(希望output稀疏)。否则hidden layer可能直接记住input,没有learn到任何东西。
在训练第二个auto-encoder时,要把database中所有digit都变成1000维vector。
以此类推,最后随机初始化输出层之前的权重。然后用BP做fine-tune(W1,W2,W3已经很好,微调即可)。
之前在训练较深的NN时要用到预训练,但是现在没必要了,因为训练技术进步了。
但在有大量unlabelled data、少量labelled data时仍需要预训练,可以先用大量无标注数据先把W1,W2,W3先learn好,最后的labelled data只需稍微调整weight就好。
De-noising auto-encoder 与 Contractive auto-encoder
De-noising auto-encoder得到的结果会比较鲁棒。
Auto-encoder for CNN
unpooling: 在pooling的时候记得从哪里取的值,unpooling的时候对应位置恢复,其余位置补0。
Keras中unpooling是直接把pooling后的每个值复制4份。
deconvolution: 其实就是convolution。
用decoder生成image
784维降到2维,根据vector的分布选择红框,在红框中等间隔采样,作为decoder的input,得到计算机生成的图片。
如果红框选错了位置,比如选在右下方,可能得不到数字。
“需知道vector分布”略麻烦,改进方法:加正则化。
在训练时,对code加L2正则化,这样code比较接近0。采样时在0附近采样,这样采样得到的vector比较有可能都对应数字。
Lecture 17: Unsupervised Learning - Deep Generative Model (Part I)
OpenAI写的关于Generative Models的科普文章[链接]中引用了费曼的一句话:凡我不能创造的,我都没有理解。对AI也是如此。PixelRNN
根据前面的像素预测接下来的像素。PixelRNN不仅work,而且在各种生成方法中PixelRNN产生的图是最清晰的。用在图像上有一些tips: 如果RGB三个值相差不大,则得到的颜色灰灰的、不够明亮,可以把众多颜色聚成若干类然后做1-of-N encoding。
如果要计算机从空白开始画,要给一个随机数,以免每次画出来的都一样。
Variational Autoencoder (VAE)
把auto-encoder中的decoder拿出来,随便产生一个vector作为code输入到decoder,得到一张image,这样做performance通常不一定很好,要改用VAE。VAE的结构:
VAE得到的结果不太清楚。VAE与PixelRNN区别在于,理论上VAE可以控制要生成的image。
比如code是10维,固定其中8维、调整剩余2维,看结果,可以解读code的每个维度代表什么意思,从而每个维度就像拉杆一样可以有目的的调整。
用VAE写“诗”:先胡乱选两个句子,经过encoder得到这两个句子的code,在code space上是两个点,连接两点、等距采样、用decoder还原,得到一系列句子。
Lecture 18: Unsupervised Learning - Deep Generative Model (Part II)
Variational Autoencoder (VAE)
Why VAE?
为什么要用VAE?一个intuitive的解释是,auto-encoder的encoder与decoder都是非线性的,很难预测问号处是一张介于满月与弦月之间的图像。VAE使得code加上noise之后还能恢复出来,这样问号处既希望恢复出满月、又希望恢复出弦月,最后得到介于满月与弦月之间的图像,既像满月又像弦月。
VAE是在encoder output上加noise,而De-noising auto-encoder是在encoder input上加noise。
如果只最小化重构误差,那么train出来的结果不会是预期的样子,因为variance是学出来的,会学成0。
exp是为了确保variance是正的,右下方的minimize是为了让variance不能太小,其中第一项为蓝色曲线、第二项为红色曲线、二者相减得绿色曲线,这样variance最小为1,第三项是L2正则化,希望参数稀疏避免过拟合。
从数学上解释,VAE是GMM的Distributed representation版本。
要最大化似然函数,似然函数可以拆成下界与KL距离。
下界与两个量有关:P(x|z),q(z|x),下界变大不一定使似然函数变大。要让KL最小,那么下界就是似然函数,得到q(z|x)=p(z|x).
下界又可以拆成两项(一个负的KL距离+一个积分),与网络联系起来:
最小化的那个式子就是要最小化这个KL距离,使得encoder产生的code z 的分布与normal distribution P(z) 越接近越好。
VAE的问题
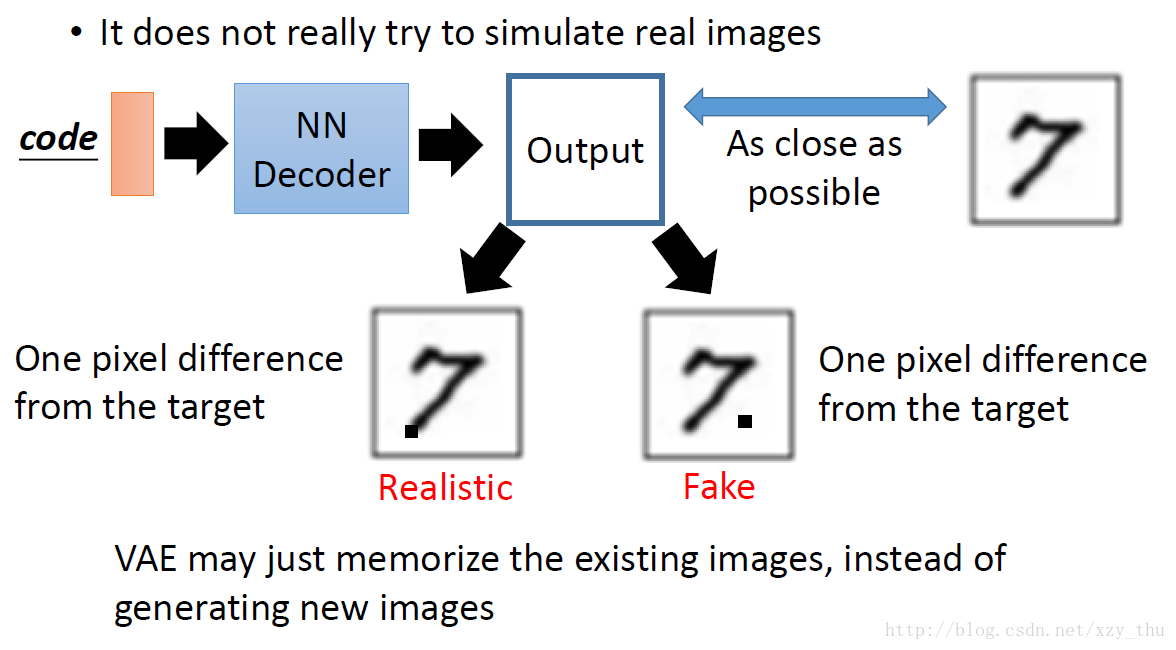
VAE只是模仿,没有创造,对VAE来讲下图中output的两张image一样好,这是不合理的。Generative Adversarial Network (GAN)
用拟态的演化来类比GAN。Discriminator判断image是Generator产生的还是real images, Generator根据Discriminator演化。
Generator从未看过real images, 产生的是database中没有见过的image。
训练:
例子(黑点:real,绿线:Generator,蓝线:Discriminator):
实际中的问题:
Basic tutorial:
An introduction to Generative Adversarial Networks (with code in TensorFlow)
Image Completion with Deep Learning in TensorFlow
Generative Adversarial Nets in TensorFlow
李宏毅机器学习课程笔记
李宏毅机器学习课程笔记1:Regression、Error、Gradient Descent
李宏毅机器学习课程笔记2:Classification、Logistic Regression、Brief Introduction of Deep Learning
李宏毅机器学习课程笔记3:Backpropagation、”Hello world” of Deep Learning、Tips for Training DNN
李宏毅机器学习课程笔记4:CNN、Why Deep、Semi-supervised
李宏毅机器学习课程笔记5:Unsupervised Learning - Linear Methods、Word Embedding、Neighbor Embedding
李宏毅机器学习课程笔记6:Unsupervised Learning - Auto-encoder、PixelRNN、VAE、GAN
李宏毅机器学习课程笔记7:Transfer Learning、SVM、Structured Learning - Introduction
李宏毅机器学习课程笔记8:Structured Learning - Linear Model、Structured SVM、Sequence Labeling
李宏毅机器学习课程笔记9:Recurrent Neural Network
李宏毅机器学习课程笔记10:Ensemble、Deep Reinforcement Learning

相关文章推荐
- [机器学习入门] 李宏毅机器学习笔记-1(Learning Map 课程导览图)
- 【李宏毅老师机器学习课程笔记】第一课:What is Machine Learning, Deep Learning and Structured Learning?
- 李宏毅MLDS课程笔记9:Generative Adversarial Network(GAN)
- [机器学习入门] 李弘毅机器学习笔记-17(Unsupervised Learning: Deep Auto-encoder;无监督学习:深度自动编码器)
- 李宏毅《机器学习》卷积神经网络课程笔记
- 机器学习之&&Andrew Ng课程复习--- 学习笔记(第三课)
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
- Coursera台大机器学习课程笔记4 -- Training versus Testing
- Coursera台大机器学习课程笔记5 -- Theory of Generalization
- 加州理工学院公开课:机器学习与数据挖掘课程笔记(一)学习问题
- Coursera台大机器学习课程笔记3 – 机器学习的可能性
- 斯坦福机器学习课程笔记(第五讲)
- Coursera台大机器学习基础课程学习笔记2 -- 机器学习的分类
- Coursera台大机器学习课程笔记6 -- The VC Dimension
- Andrew Ng 《机器学习》课程笔记
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
- Coursera台大机器学习基础课程学习笔记2 -- 机器学习的分类
- SparseAutoEncoder 稀疏编码详解(Andrew ng课程系列)
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
- Coursera台大机器学习课程笔记7 -- Noise and Error