TensorFlow实战12:实现基于LSTM的语言模型
2017-04-15 15:18
816 查看
1.LSTM的语言模型简介
LSTM(Long Short Term Memory),用来处理有时序联系的信息效果非常明显,在很多情况下,卷积神经网络虽然处理图片增加了其空间特征的联系,但是对于图片与图片之间的联系性并不是很强,所以对于视频或者是自然语言处理前后的关联性并不是很好。
对于一些简单的问题,可能只需要最后输入的少量时序信息即可解决问题。但对于复杂问题,可能需要更早的一些信息,甚至是时间序列的开头信息,但间隔太久的信息RNN无法捕获的,所以LSTM的发明就是为了解决这个问题。
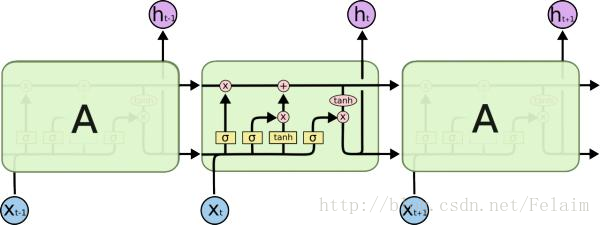
如上图所示,LSTM包括了四层神经网络,圆圈是point-wise的操作,比如向量加法、点乘等。小矩形代表一层可学习参数的神经网络。LSTM单元上面的那条直线代表了LSTM的状态state,它会贯穿所有连接在一起的LSTM单元,从第一个LSTM单元一直流向最后一个LSTM单元,其中只有少量的线性干预和改变。状态state在这条隧道中传递时,LSTM单元可以对其添加或者删减信息,这些对信息流的修改操作由LSTM中的Gates控制。这些Gates中包含了一个Sigmoid层和一个向量的点乘的操作,这个Sigmoid层的输出时0到1之间的值,它直接控制了信息传递的比例。如果为0则代表不允许信息传递,如果为1,则表示信息全部通过。每个LSTM单元包含3个这样的Gates,用来维护和控制单元的状态信息。凭借对状态信息的储存和修改,LSTM单元就可以实现长程记忆。
详细的关于RNN和LSTM的信息可以查看http://colah.github.io/posts/2015-08-Understanding-LSTMs/
2.LSTM的语言模型的代码实现
这里和之前有些不一样,需要下载一些数据集,并且要用一些现成的代码来处理数据,所以会稍微有些繁琐。
我只想说这个编辑器有bug,回车会自动把代码删除。。。这是什么鬼?O(∩_∩)O
LSTM(Long Short Term Memory),用来处理有时序联系的信息效果非常明显,在很多情况下,卷积神经网络虽然处理图片增加了其空间特征的联系,但是对于图片与图片之间的联系性并不是很强,所以对于视频或者是自然语言处理前后的关联性并不是很好。
对于一些简单的问题,可能只需要最后输入的少量时序信息即可解决问题。但对于复杂问题,可能需要更早的一些信息,甚至是时间序列的开头信息,但间隔太久的信息RNN无法捕获的,所以LSTM的发明就是为了解决这个问题。
如上图所示,LSTM包括了四层神经网络,圆圈是point-wise的操作,比如向量加法、点乘等。小矩形代表一层可学习参数的神经网络。LSTM单元上面的那条直线代表了LSTM的状态state,它会贯穿所有连接在一起的LSTM单元,从第一个LSTM单元一直流向最后一个LSTM单元,其中只有少量的线性干预和改变。状态state在这条隧道中传递时,LSTM单元可以对其添加或者删减信息,这些对信息流的修改操作由LSTM中的Gates控制。这些Gates中包含了一个Sigmoid层和一个向量的点乘的操作,这个Sigmoid层的输出时0到1之间的值,它直接控制了信息传递的比例。如果为0则代表不允许信息传递,如果为1,则表示信息全部通过。每个LSTM单元包含3个这样的Gates,用来维护和控制单元的状态信息。凭借对状态信息的储存和修改,LSTM单元就可以实现长程记忆。
详细的关于RNN和LSTM的信息可以查看http://colah.github.io/posts/2015-08-Understanding-LSTMs/
2.LSTM的语言模型的代码实现
这里和之前有些不一样,需要下载一些数据集,并且要用一些现成的代码来处理数据,所以会稍微有些繁琐。
wget http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz tar xvf simple-examples.tgz git clone https://github.com/tensorflow/models.git cd models/tutorials/rnn/ptb
#coding:utf-8
#导入常用的库,模型中的PTB reader主要是借助它读取数据内容,并把单词转为唯一的数字编码,以便神经网络处理
from __future__ import division
import time
import numpy as np
import tensorflow as tf
import reader
#定义语言模型处理输入数据的class
class PTBInput(object):
def __init__(self, config, data, name = None):
self.batch_size = batch_size = config.batch_size
self.num_steps = num_steps = config.num_steps
self.epoch_size = ((len(data) // batch_size) - 1) // num_steps
self.input_data, self.targets = reader.ptb_producer(data, batch_size, num_steps, name = name)
#定义语言模型的class,PTBModel
class PTBModel(object):
def __init__(self, is_training, config, input_):
self._input = input_
batch_size = input_.batch_size
num_steps = input_.num_steps
size = config.hidden_size
vocab_size = config.vocab_size
#设置默认的LSTM单元
def lstm_cell():
return tf.contrib.rnn.BasicLSTMCell(size, forget_bias = 0.0, state_is_tuple = True)
attn_cell = lstm_cell
if is_training and config.keep_prob < 1:
def attn_cell():
return tf.contrib.rnn.DropoutWrapper(lstm_cell(), output_keep_prob = config.keep_prob)
cell = tf.contrib.rnn.MultiRNNCell([attn_cell() for _ in range(config.num_layers)], state_is_tuple = True)
self._initial_state = cell.zero_state(batch_size, tf.float32)
#创建网络的词嵌入的部分
with tf.device("/cpu:0"):
embedding = tf.get_variable("embedding", [vocab_size, size], dtype = tf.float32)
inputs = tf.nn.embedding_lookup(embedding, input_.input_data)
if is_training and config.keep_prob < 1:
inputs = tf.nn.dropout(inputs, config.keep_prob)
#定义输出
outputs = []
state = self._initial_state
with tf.variable_scope("RNN"):
for time_step in range(num_steps):
if time_step > 0:tf.get_variable_scope().reuse_variables()
(cell_output, state) = cell(inputs[:, time_step, :], state)
outputs.append(cell_output)
output = tf.reshape(tf.concat(outputs, 1), [-1, size])
softmax_w = tf.get_variable("softmax_w", [size, vocab_size], dtype = tf.float32)
softmax_b = tf.get_variable("softmax_b", [vocab_size], dtype = tf.float32)
logits = tf.matmul(output, softmax_w) + softmax_b
loss = tf.contrib.legacy_seq2seq.sequence_loss_by_example([logits], [tf.reshape(input_.targets, [-1])],
[tf.ones([batch_size * num_steps], dtype = tf.float32)])
self._cost = cost = tf.reduce_sum(loss) / batch_size
self._final_state = state
if not is_training:
return
#定义学习率,优化器等
self._lr = tf.Variable(0.0, trainable = False)
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(cost, tvars), config.max_grad_norm)
optimizer = tf.train.GradientDescentOptimizer(self._lr)
self._train_op = optimizer.apply_gradients(zip(grads, tvars),
global_step = tf.contrib.framework.get_or_create_global_step())
self._new_lr = tf.placeholder(tf.float32, shape = [], name = "new_learning_rate")
self._lr_update = tf.assign(self._lr, self._new_lr)
def assign_lr(self, session, lr_value):
session.run(self._lr_update, feed_dict = {self._new_lr: lr_value})
#利用@property装饰器可以将返回变量设为只读
@property
def input(self):
return self._input
@property
def initial_state(self):
return self._initial_state
@property
def cost(self):
return self._cost
@property
def final_state(self):
return self._final_state
@property
def lr(self):
return self._lr
@property
def train_op(self):
return self._train_op
#定义小的训练模型参数
class SmallConfig(object):
init_scale = 0.1
learning_rate = 1.0
max_grad_norm = 5
num_layers = 2
num_steps = 20
hidden_size = 200
max_epoch = 4
max_max_epoch = 13
keep_prob = 1.0
lr_decay = 0.5
batch_size = 20
vocab_size = 10000
#定义中等的训练模型参数
class MediumConfig(object):
init_scale = 0.05
learning_rate = 1.0
max_grad_norm = 5
num_layers = 2
num_steps = 35
hidden_size = 650
max_epoch = 6
max_max_epoch = 39
keep_prob = 0.5
lr_decay = 0.8
batch_size = 20
vocab_size = 10000
#定义大的训练模型参数
class LargeConfig(object):
init_scale = 0.04
learning_rate = 1.0
max_grad_norm = 10
num_layers = 2
num_steps = 35
hidden_size = 1500
max_epoch = 14
max_max_epoch = 55
keep_prob = 0.35
lr_decay = 1 / 1.15
batch_size = 20
vocab_size = 10000
#定义测试时的训练模型
class TestConfig(object):
init_scale = 0.1
learning_rate = 1.0
max_grad_norm = 1
num_layers = 1
num_steps = 2
hidden_size = 2
max_epoch = 1
max_max_epoch = 1
keep_prob = 1.0
lr_decay = 0.5
batch_size = 20
vocab_size = 10000
#定义训练一个epoch数据的函数
def run_epoch(session, model, eval_op = None, verbose = False):
start_time = time.time()
costs = 0.0
iters = 0
state = session.run(model.initial_state)
fetches = {
"cost": model.cost,
"final_state": model.final_state,
}
if eval_op is not None:
fetches["eval_op"] = eval_op
for step in range(model.input.epoch_size):
feed_dict = {}
for i, (c, h) in enumerate(model.initial_state):
feed_dict[c] = state[i].c
feed_dict[h] = state[i].h
vals = session.run(fetches, feed_dict)
cost = vals["cost"]
state = vals["final_state"]
costs += cost
# print cost
iters += model.input.num_steps
if verbose and step % (model.input.epoch_size // 10) == 10:
print ("%.3f perplexity: %.3f speed : %.0f wps"
%(step * 1.0 / model.input.epoch_size, np.exp(costs / iters),
iters * model.input.batch_size / (time.time() - start_time)))
return np.exp(costs / iters)
#直接读取解压数据
raw_data = reader.ptb_raw_data('simple-examples/data/')
train_data, valid_data, test_data, _ = raw_data
config = SmallConfig()
eval_config = SmallConfig()
eval_config.batch_size = 1
eval_config.num_steps = 1
#创建图
with tf.Graph().as_default():
initializer = tf.random_uniform_initializer(-config.init_scale, config.init_scale)
with tf.name_scope("Train"):
train_input = PTBInput(config = config, data = train_data, name = 'TrainInput')
with tf.variable_scope("Model", reuse = None, initializer = initializer):
m = PTBModel(is_training = True, config = config, input_ = train_input)
with tf.name_scope("Valid"):
valid_input = PTBInput(config = config, data = valid_data, name = "ValidInput")
with tf.variable_scope("Model", reuse = True, initializer = initializer):
mvalid = PTBModel(is_training = False, config = config, input_ = valid_input)
with tf.name_scope("Test"):
test_input = PTBInput(config = eval_config, data = test_data, name = "TestInput")
with tf.variable_scope("Model", reuse = True, initializer = initializer):
mtest = PTBModel(is_training = False, config = eval_config, input_ = test_input)
#创建训练的管理器
sv = tf.train.Supervisor()
with sv.managed_session() as session:
for i in range(config.max_max_epoch):
lr_decay = config.lr_decay ** max(i + 1 - config.max_epoch, 0.0)
m.assign_lr(session, config.learning_rate * lr_decay)
print("Epoch: %d Learning rate: %.3f" %(i + 1, session.run(m.lr)))
train_perplexity = run_epoch(session, m, eval_op = m.train_op, verbose = True)
print("Epoch: %d Train Perplexity: %.3f" %(i + 1, train_perplexity))
valid_perplexity = run_epoch(session, mvalid)
print("Epoch: %d valid Perplexity: %.3f" %(i + 1, valid_perplexity))
test_perplexity = run_epoch(session, mtest)
print("Test Perplexity: %.3f" %test_perplexity)我只想说这个编辑器有bug,回车会自动把代码删除。。。这是什么鬼?O(∩_∩)O

相关文章推荐
- Tensorflow实战学习(三十五)【实现基于LSTM语言模型】
- Tensorflow实战-实现基于LSTM的语言模型
- TensorFlow实现基于LSTM的语言模型
- Tensorflow实例:实现基于LSTM的语言模型
- TensorFlow实现经典深度学习网络(6):TensorFlow实现基于LSTM的语言模型
- tensorflow38《TensorFlow实战》笔记-07-02 TensorFlow实现基于LSTM的语言模型 code
- 基于循环神经网络实现基于字符的语言模型(char-level RNN Language Model)-tensorflow实现
- 学习笔记TF035:实现基于LSTM语言模型
- 深度学习之六,基于RNN(GRU,LSTM)的语言模型分析与theano代码实现
- 使用循环神经网络实现语言模型——源自《TensorFlow:实战Goole深度学习框架》
- 学习笔记TF035:实现基于LSTM语言模型
- TensorFlow-10-基于 LSTM 建立一个语言模型
- TensorFlow-Bitcoin-Robot:一个基于 TensorFlow LSTM 模型的 Bitcoin 价格预测机器人
- 我用 tensorflow 实现的“一个神经聊天模型”:一个基于深度学习的聊天机器人
- 基于负采样的skip-garm的语言模型实现-R
- R语言实战实现基于用户的简单的推荐系统(数量较少)
- MXNet官方文档教程(3):基于多层LSTM的字符级语言模型
- tensorflow 学习笔记12 循环神经网络RNN LSTM结构实现MNIST手写识别
- 我用 tensorflow 实现的“一个神经聊天模型”:一个基于深度学习的聊天机器人
- tensorflow实例:实现word2vec语言模型