用python写一个简单的爬虫功能
2017-04-15 11:26
218 查看
我先假设你用的是Mac,然后Mac都预装了python2.x,然后呢,你有了python没用,你得有库.没库怎么干活?怎么安装库呢?
python界也有个类似于我们iOS开发里
首先配置python环境,安装
2
3
1
2
3
然后你们打开terminal敲入下面这个命令.
1
然后就会自动帮你安装
好的我们随意打开网页
你看到的是这些东西.
图片链接就在li这个标签下地img标签里.现在我们需要做的就是尝试着把这种类型的li从所有html中分离出来.我们可以看到li这个标签有个属性叫做class,这个属性的值是class=”span3”,我们把这段话li class=”span3”
搜索一下,我们发现有20个结果.恰巧,我们这个页面的图片也只有20个,那么可以确定的是我们找到了区别于其他标签的唯一性.
再仔细分析下,img这个标签在li这个标签里有且只有一个.那么,也就是说,我们先搜索出所有符合条件的li标签,然后找到里面的img标签就可以找到所有的图片链接了.
然后看代码.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
我们来一句一句分析下.其实python的语法超级简单.
凡是
分别说明我们的环境是python,编码是
然后
导入
然后
1
这句很简单,就是读取网页的html.然后把值赋给html这个变量.python里声明变量前面不用加任何东西,不用加声明语句和变量类型,就连
我们获取了网页的html之后呢,声明了一个
1
这句话的意思就是,寻找html中所有
注意这个
1
这句话基本和oc里的遍历数组语法完全一样.就是遍历liResult里的每一个变量.那么每一个变量就是一个标签.
1
这句的意思就是,获取
这里定义了一个变量
赋给我们的变量
2
3
1
2
3
这两句,第一句是设置一个文件存放地址,第二句用urllib这个库的urlretrieve这个方法下载我们的图片,并且把图片放到刚才的路径里.
好了,万事具备了,我们现在跑一下我们的脚本
1
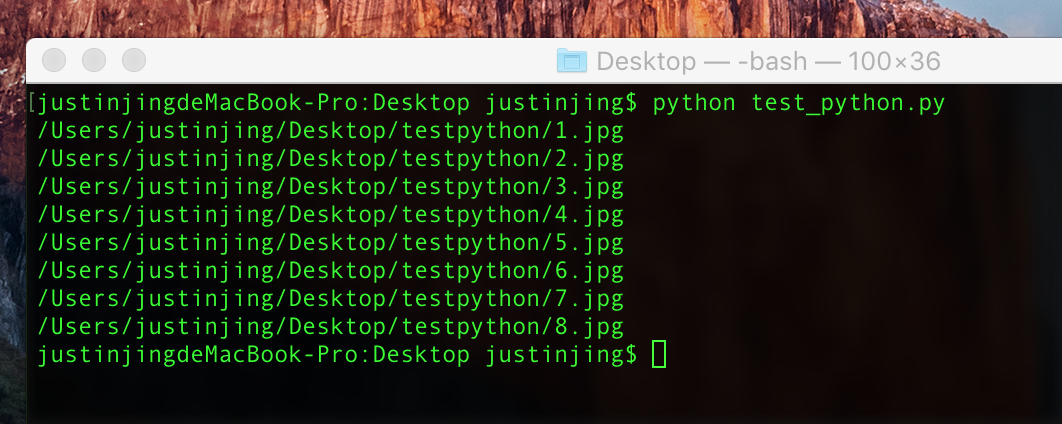
好了,我们的图片就下载完了.
然后在看看下载的内容:
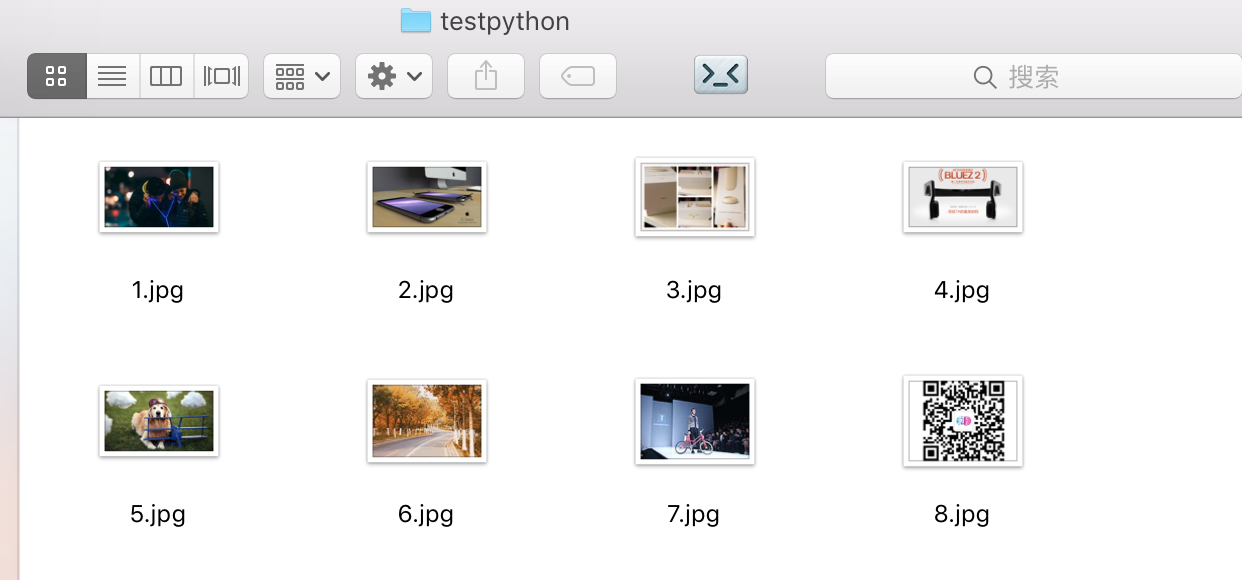
python界也有个类似于我们iOS开发里
cocoapods的东西,这个东西叫做
pip.
pip和
cocoapods用起来的命令都极其类似,我们只需要两个库,一个叫做
urllib2,一个叫做
Beautifulsoup.
urllib2是干什么的呢?它的作用就是把网页down下来,然后你就可以分析网页了.
Beautifulsoup干什么的呢?你用
urllib2把网页down下来了之后,里面都是
html+css什么的,你想要从乱七八糟的一堆html里面找到正确的图片链接那可不是件简单的事,据我这几天的学习,做法无非
两个,
一个是自己写正则表达式然后用一个叫
re的python库,
另一个是使用
lxml解析
xpath.这两个说实话都不太好用,一个正则就够你吃一壶的.后来我搜索了很久,发现了一个库叫做
Beautifulsoup,用这个库解析
html超级好用.
首先配置python环境,安装
pip:
curl -O http://python-distribute.org/distribute_setup.py udo python distribute_setup.py 回车然后输入密码 sudo easy_install pip1
2
3
1
2
3
然后你们打开terminal敲入下面这个命令.
pip install BeautifulSoup1
1
然后就会自动帮你安装
BeautifulSoup这个东西了.
urllib2因为是自带的,所以不用你下载了.
好的我们随意打开网页
http://www.pcpop.com/doc/1/1279/1279531.shtml,直接右键打开源文件.
你看到的是这些东西.
图片链接就在li这个标签下地img标签里.现在我们需要做的就是尝试着把这种类型的li从所有html中分离出来.我们可以看到li这个标签有个属性叫做class,这个属性的值是class=”span3”,我们把这段话li class=”span3”
搜索一下,我们发现有20个结果.恰巧,我们这个页面的图片也只有20个,那么可以确定的是我们找到了区别于其他标签的唯一性.
再仔细分析下,img这个标签在li这个标签里有且只有一个.那么,也就是说,我们先搜索出所有符合条件的li标签,然后找到里面的img标签就可以找到所有的图片链接了.
然后看代码.
#!/usr/bin/python
#-*- coding: utf-8 -*-
#encoding=utf-8
import urllib2
import urllib
import os
from BeautifulSoup import BeautifulSoup
def getAllImageLink():
html = urllib2.urlopen('http://www.pcpop.com/doc/1/1279/1279531.shtml').read()
soup = BeautifulSoup(html)
liResult = soup.findAll('img',attrs={"width":"175"})
#print liResult 方便调试
count = 0;
for image in liResult:
count += 1
link = image.get('src')
imageName = count
filesavepath = '/Users/justinjing/Desktop/testpython/%s.jpg' % imageName
urllib.urlretrieve(link,filesavepath)
print filesavepath
if __name__ == '__main__':
getAllImageLink()12
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
我们来一句一句分析下.其实python的语法超级简单.
凡是
#打头的就是python里面的注释语句类似于oc里的
//.
分别说明我们的环境是python,编码是
utf-8
然后
import了四个库,分别是
urllib2,
urllib,
os,和
Beautifulsoup库.
导入
Beautifulsoup库的方式和其他三个不太一样.我暂时也不清楚为什么python用这种导入方式,不过照猫画虎就行了.
然后
def打头的就是定义一个函数,python里面是
不用分号做句与句的分隔符的.他用缩进来表示.与
def缩进一个
tab的都是函数体.
html = urllib2.urlopen('http://www.pcpop.com/doc/1/1279/1279531.shtml').read()11
这句很简单,就是读取网页的html.然后把值赋给html这个变量.python里声明变量前面不用加任何东西,不用加声明语句和变量类型,就连
JavaScript声明变量还要加个
var呢.
我们获取了网页的html之后呢,声明了一个
Beautifulsoup变量
soup,用来准备解析html.
liResult = soup.findAll('img',attrs={"width":"175"})11
这句话的意思就是,寻找html中所有
img标签,并且这个
img标签有个属性
width,
width的值是
175.
注意这个
findAll函数,有点常识的话你应该清楚,凡是带all的函数基本上返回的都是一个数组,所以我们
liResult这个变量实际上是一个数组.
for image in liResult:1
1
这句话基本和oc里的遍历数组语法完全一样.就是遍历liResult里的每一个变量.那么每一个变量就是一个标签.
link = image.get('src')11
这句的意思就是,获取
img标签里的
src属性,
src就是我们最想要的图片链接了.
这里定义了一个变量
count = 0,然后在 for 循环里面做递加
count += 1,最终把这个值
赋给我们的变量
imageName = count,以便后面使用。
filesavepath = '/Users/weihua0618/Desktop/testpython/%s.jpg' % imageName urllib.urlretrieve(link,filesavepath)1
2
3
1
2
3
这两句,第一句是设置一个文件存放地址,第二句用urllib这个库的urlretrieve这个方法下载我们的图片,并且把图片放到刚才的路径里.
好了,万事具备了,我们现在跑一下我们的脚本
python test_python.py1
1
好了,我们的图片就下载完了.
然后在看看下载的内容:

相关文章推荐
- 用python写一个简单的爬虫功能
- 用Python写一个简单的爬虫功能
- 一个简单的python爬虫程序
- python实现简单爬虫功能
- python实现简单爬虫功能
- python学习笔记:"爬虫+有道词典"实现一个简单的英译汉程序
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
- python实现简单爬虫功能
- 1. python实现简单爬虫功能
- 使用PYTHON3写了一个简单爬虫, 通过公司代理爬取ppt素材
- [python脚本]一个简单的web爬虫(1)
- python实现简单爬虫功能
- python实现简单爬虫功能
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫(转)
- 用Python 实现刷钻网上抢任务,并实现一个简单的限制使用时间的功能
- 实现一个简单的邮箱地址爬虫(python)
- [Python]网络爬虫(六):一个简单的百度贴吧的小爬虫
- python实现简单爬虫功能