神经网络基础 - PyBrain机器学习包的使用
2017-04-14 11:41
447 查看
神经网络基础 - PyBrain机器学习包的使用
PyBrain = Python-Based Reinforcement Learning, Artificial Intelligence and Neural Network,是一个基于Python的以神经网络为核心的机器学习包。这里我们用它来实现一个基本的BP神经网络。安装准备
PyBrain安装十分简单(只是要提前装好依赖包numpy,scipy,nose等):由于PyBrain托管在GitHub上,可直接使用git命令来获取最新版本:
git clone git://github.com/pybrain/pybrain.git "指定路径"
进入指定路径,运行安装命令:
python setup.py install
安装可能需要权限。
更多安装信息可参考官方主页-Installation.
数据准备
这里我们采用UCI著名数据集Iris Data Set.其数据集的简述如下:
输入:鸢尾花的四个属性(连续值) 1. sepal length in cm 2. sepal width in cm 3. petal length in cm 4. petal width in cm 输出:鸢尾花的品种(分类值) -- Iris Setosa -- Iris Versicolour -- Iris Virginica 过程:由输入预测输出 其他: 样本量:150,每类样本量平均。 缺失值:无
下面是一些数据示例:
5.1,3.5,1.4,0.2,Iris-setosa 4.9,3.0,1.4,0.2,Iris-setosa ... 7.0,3.2,4.7,1.4,Iris-versicolor 6.4,3.2,4.5,1.5,Iris-versicolor ... 6.3,3.3,6.0,2.5,Iris-virginica 5.8,2.7,5.1,1.9,Iris-virginica ...
模型学习 - 基于PyBrain
查看完整代码数据预处理
这里要采用BP神经网络(多层前馈神经网络)来构建IRIS预测模型(分类器),先对数据进行分析。读取并查看数据:
已安装的sklearn包自带iris数据集,并且已将输出类型从字符串(Iris-setosa,Iris-versicolor,Iris-virginica)转化为离散数(0,1,2),方便计算操作。
数据归一化处理:
数据共有4个输入属性(特征),一个输出类别标签,各属性单位均是cm(连续值、同度量),故不考虑进行归一化处理。
进一步分析:
通过可视化可以对数据进行相关性检验。同时查看数据点及标签分散情况,从而对分类难度和分类器维度有一个初步的感知。
下图所示为采用matplotlib绘制的前两个属性的散点图:

从这些图中可以得出线性不可分等基本认识。
独热编码:
由于输出为离散标称值,考虑采用独热编码(one hot encoding)将其转换为数值变量。pybrain自带独热编码函数datasets.ClassificationDataSet_convertToOneOfMany()。编码前后输出变量示意如下:
编码前:
[[1], [2], [1], [0]]
编码后:
[[0, 1, 0], [0, 0, 1], [0, 1, 0], [1, 0, 0]]
可以看到编码后,神经网络的输出从1维变到3维,所以输出节点数设为3,为了让输出映射类别标签,可采用softmax函数作为输出层的激活函数。
程序示例:
下面是读取数据并进行编码的程序示例(包括训练集测试集的划分):
''' preparation of data ''' from sklearn import datasets iris_ds = datasets.load_iris() X, y = iris_ds.data, iris_ds.target label = ['Iris-setosa', 'Iris-versicolor', 'Iris-virginica'] from pybrain.datasets import ClassificationDataSet # 4 input attributes, 1 output with 3 class labels ds = ClassificationDataSet(4, 1, nb_classes=3, class_labels=label) for i in range(len(y)): ds.appendLinked(X[i], y[i]) ds.calculateStatistics() # split training, testing, validation data set (proportion 4:1) tstdata_temp, trndata_temp = ds.splitWithProportion(0.25) tstdata = ClassificationDataSet(4, 1, nb_classes=3, class_labels=label) for n in range(0, tstdata_temp.getLength()): tstdata.appendLinked( tstdata_temp.getSample(n)[0], tstdata_temp.getSample(n)[1] ) trndata = ClassificationDataSet(4, 1, nb_classes=3, class_labels=label) for n in range(0, trndata_temp.getLength()): trndata.appendLinked( trndata_temp.getSample(n)[0], trndata_temp.getSample(n)[1] ) # one hot encoding trndata._convertToOneOfMany() tstdata._convertToOneOfMany()
BP网络训练
采用pybrain包训练BP神经网络模型的基本步骤如下:初始化网络(设置层数、每层节点数、每层激活函数等),示例代码如下:
from pybrain.tools.shortcuts import buildNetwork # 4 input nodes, 3 output node each represent one class # here we set 5 hidden layer nodes. # SoftmaxLayer(0/1) for multi-label output activation function n_h = 5 net = buildNetwork(4, n_h, 3, outclass = SoftmaxLayer)
初始化训练子(如训练模型对象,训练集等),进行训练(设置迭代次数(epoch参数),批处理或流处理(batchlearning参数)),示例代码如下:
# standard(incremental) BP algorithm: trainer = BackpropTrainer(net, trndata) trainer.trainEpochs(1)
上述代码是采用一次数据集遍历的**标准BP算法**,若采用多次迭代直至收敛的**累积BP算法**,示例代码如下(50次迭代,标准梯度下降):
# accumulative BP algorithm: trainer = BackpropTrainer(net, trndata, batchlearning=True) err_train, err_valid = trainer.trainUntilConvergence(maxEpochs=500)
模型验证
直接在测试集上进行预测,计算输出精度(累积BP算法下可查看收敛曲线):'''
test of model
'''
# convergence curve
import matplotlib.pyplot as plt
plt.plot(err_train,'b',err_valid,'r')
plt.show()
# model testing
from pybrain.utilities import percentError
tstresult = percentError( trainer.testOnClassData(), tstdata['target'] )
print("epoch: %4d" % trainer.totalepochs, " test error: %5.2f%%" % tstresult)标准BP算法在IRIS测试集上的精度结果如下所示:
epoch: 1 test error: 0.88%
可以看出,错误率<1%,说明该模型精度表现良好(和数据集本身高维可分也有很大的关系)。
累积BP算法下,得出参数收敛曲线如下图所示:
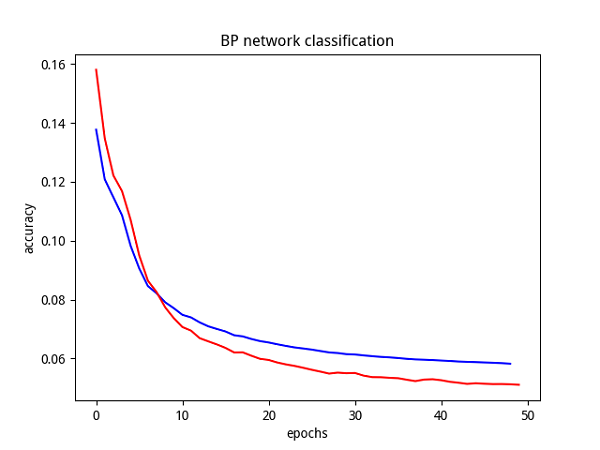
可以看出,累积BP算法的参数收敛良好,预测精度结果比标准BP算法还要好一些。
但是,采用datetime测试程序运行时间,可以看出累积BP算法远远大于标准BP算法。
总结
采用pybrain可以轻松实现一些基本的神经网络模型,方便了神经网络的实现练习。ps.这个包本身的运行效率貌似也不是特别高。
参考
本文内容主要参考了官方文档:PyBrain官方文档主页

相关文章推荐
- 机器学习中使用的神经网络(三)
- 神经网络的表达式 机器学习基础(3)
- 机器学习之深入理解神经网络理论基础、BP算法及其Python实现
- 机器学习系列直播--使用对抗神经网络(GANs)生成猫
- 基于神经网络的机器学习基础
- 机器学习中使用的神经网络(四)
- 机器学习中使用的神经网络第九讲笔记
- 机器学习 —— 基础整理(八)循环神经网络的BPTT算法步骤整理;梯度消失与梯度爆炸
- stanford coursera 机器学习编程作业 exercise 3(使用神经网络 识别手写的阿拉伯数字(0-9))
- 人工智能,机器学习,神经网络,深度学习之基础概念
- 机器学习中使用的神经网络(六) --第二课
- 机器学习中使用的神经网络第六讲笔记
- 机器学习中使用的神经网络第二讲笔记
- 机器学习的大局观:使用神经网络和TensorFlow来对文本分类
- 机器学习中使用的神经网络(一)
- 机器学习中使用的神经网络(七)
- 机器学习中使用的神经网络第四讲笔记
- 机器学习中使用的神经网络第五讲笔记
- 机器学习中使用的神经网络第二讲笔记:神经网络的结构和感知机
- 机器学习中使用的神经网络第一讲笔记:Introduction