BM字符串匹配算法解析
2017-04-06 15:28
190 查看
BM算法相比较KMP算法较容易理解,两个算法都是字符串的匹配算法,只不过KMP是前缀匹配算法,而BM 是后缀匹配算法,KMP主要依赖
首先说明一点,BM字符串比较算法是从模式串的末尾向前进行比较的,坏字符是当模式串与目标串比较单个字符,且目标串与模式串不匹配的那个目标串字符。那么此时模式串右边的字符已经完成匹配,这时就需要移动模式串,使得坏字符与模式串右边的字符相应匹配。这样子可以节省很多不需要的比较(好好想想);好后缀是目标串已经和模式串匹配上的那个后缀,同样,我们也可以把模式串向前移动,直到模式串中的某个子串与好后缀匹配,这样也是减少的不必要的比较,那么问题来了,到底是根据坏字符进行移动还是根据好后缀进行移动呢?其实比较一下两种方式移动的距离,选取距离最大的那种移动方式就可以了。
同KMP算法一样,BM算法也需要预处理出
坏字符:后移位数 = 坏字符的位置 - 模式串中的上一次出现位置(没有出现就是-1)
好后缀:后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置(没有出现也是-1)
”好后缀”的位置以最后一个字符为准。假定”ABCDEF”的”EF”是好后缀,则它的位置以”F”为准,即5(从0开始计算)。
如果”好后缀”在搜索词中只出现一次,则它的上一次出现位置为 -1。比如,”EF”在”ABCDEF”之中只出现一次,则它的上一次出现位置为-1(即未出现)。
如果”好后缀”有多个,则除了最长的那个”好后缀”,其他”好后缀”的上一次出现位置必须在头部。比如,假定”BABCDAB”的”好后缀”是”DAB”、”AB”、”B”,请问这时”好后缀”的上一次出现位置是什么?回答是,此时采用的好后缀是”B”,它的上一次出现位置是头部,即第0位。这个规则也可以这样表达:如果最长的那个”好后缀”只出现一次,则可以把搜索词改写成如下形式进行位置计算”(DA)BABCDAB”,即虚拟加入最前面的”DA”。
下面我们就来分析下代码。
注意,这是
注意,
注意,这个函数有三个部分,其中分别对应与三种情况:好后缀在前面的字符串中没有出现;好后缀在前面的字符串只出现的部分,其一定是出现在字符串开头;好后缀完整出现在前面的字符串。
那么很简单,第一种情况当然需要移动整个模式串的长度,第二种情况判断
最后贴上完整代码:
参考:
字符串匹配的Boyer-Mo
c77d
ore算法;作者: 阮一峰
算法代码参考;英文
next[], 而BM主要依赖
bs[], gs[]也就是我们常说的坏字符和好后缀。
首先说明一点,BM字符串比较算法是从模式串的末尾向前进行比较的,坏字符是当模式串与目标串比较单个字符,且目标串与模式串不匹配的那个目标串字符。那么此时模式串右边的字符已经完成匹配,这时就需要移动模式串,使得坏字符与模式串右边的字符相应匹配。这样子可以节省很多不需要的比较(好好想想);好后缀是目标串已经和模式串匹配上的那个后缀,同样,我们也可以把模式串向前移动,直到模式串中的某个子串与好后缀匹配,这样也是减少的不必要的比较,那么问题来了,到底是根据坏字符进行移动还是根据好后缀进行移动呢?其实比较一下两种方式移动的距离,选取距离最大的那种移动方式就可以了。
同KMP算法一样,BM算法也需要预处理出
gs[], bs[],那么根据上一段的描述,我们大致可以总结出坏字符和好后缀的移动规则:
坏字符:后移位数 = 坏字符的位置 - 模式串中的上一次出现位置(没有出现就是-1)
好后缀:后移位数 = 好后缀的位置 - 搜索词中的上一次出现位置(没有出现也是-1)
”好后缀”的位置以最后一个字符为准。假定”ABCDEF”的”EF”是好后缀,则它的位置以”F”为准,即5(从0开始计算)。
如果”好后缀”在搜索词中只出现一次,则它的上一次出现位置为 -1。比如,”EF”在”ABCDEF”之中只出现一次,则它的上一次出现位置为-1(即未出现)。
如果”好后缀”有多个,则除了最长的那个”好后缀”,其他”好后缀”的上一次出现位置必须在头部。比如,假定”BABCDAB”的”好后缀”是”DAB”、”AB”、”B”,请问这时”好后缀”的上一次出现位置是什么?回答是,此时采用的好后缀是”B”,它的上一次出现位置是头部,即第0位。这个规则也可以这样表达:如果最长的那个”好后缀”只出现一次,则可以把搜索词改写成如下形式进行位置计算”(DA)BABCDAB”,即虚拟加入最前面的”DA”。
下面我们就来分析下代码。
void preGetBs(char s[], int len, int bs[])
{
for (int i = 0; i < ASIZE; i++)
bs[i] = len;
for (int i = 0; i < len - 1; i++)
bs[s[i]] = len - i - 1;
}注意,这是
bs[]代表的是字符
c到模式串末尾的最短距离,首先初始化
bs[] = len,也就是说使得所有的坏字符移动的距离都是模式串的长度;从头到尾计算距离,且对于同一个字符来说,从头到为计算出来的距离会越来越短,直到最短距离。
void suffix(char s[], int len, int suff[])
{
suff[len - 1] = len;
int g = len - 1, f;
for (int i = len - 2; i >= 0; i--)
if (i > g && suff[len - 1 - (f - i)] < i - g)
suff[i] = suff[len - 1 - (f - i)];
else {
if (i < g)
g = i;
f = i;
while (g >= 0 && s[g] == s[len - 1 - (f - g)])
--g;
suff[i] = f - g;
}
}注意,
suff[]是这样的一个数组:
suff[i] = s表示
str[i - s + 1, i]≡
str[strlen(str) - s, strlen(str) - 1]。这是为了处理好后缀所做的准备。这个代码中给了很重要的一个优化,就是
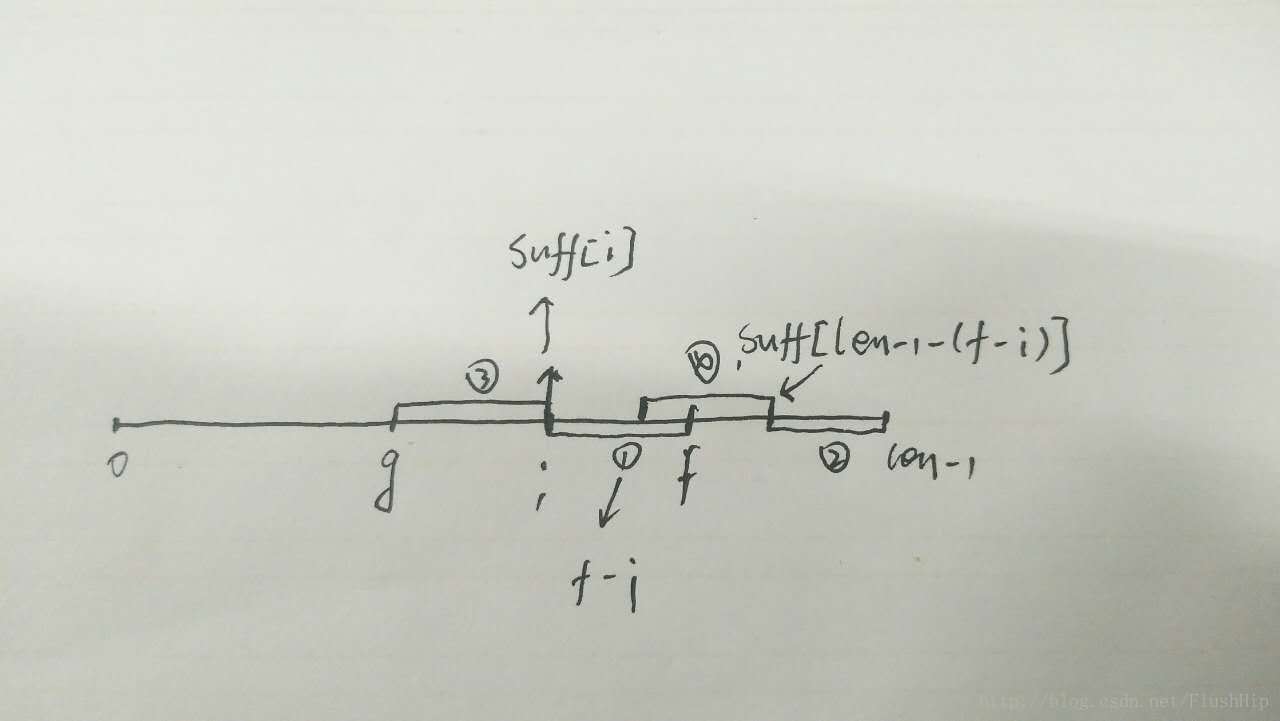
if (i > g && suff[len - 1 - (f - i)] < i - g) suff[i] = suff[len - 1 - (f - i)];看图片
f最近一次比较开始的地方,
g是模式串的指针,
i是当前位置.通过这张图片我们可以发现,
str[g,f]这段子串是和后缀相匹配的,那么当
i在
g和
f之间的时候,我们是不是可以利用已经比较过的结果来计算呢?答案是可以的,
str[g,i]当然是和后缀匹配的,那么我们只要看下
suff[len - 1 - (f - i)]的值是不是比
i - g大,如果大,那么说明
str[0,len - 1 - (f - i)]与后缀匹配的字符比
str[g, i]多,也就是说
g要继续向后移动来判断
g前面的字符是否有更多的字符与后缀匹配;如果小,很显然,直接可以
suff[i] = suff[len - 1 - (f - i)];看看图就应该明白了。
void preGetGs(char s[], int len, int gs[])
{
int i, j;
suffix(s, len, suff);
for (i = 0; i < len; i++)
gs[i] = len;
for (j = 0, i = len - 1; i >= 0; i--)
if (suff[i] == i + 1)
for (; j < len - 1 - i; j++)
if (gs[j] == len)
gs[j] = len - 1 -i;
for (i = 0; i <= len - 2; i++)
gs[len - 1 -suff[i]] = len - 1 - i;
}注意,这个函数有三个部分,其中分别对应与三种情况:好后缀在前面的字符串中没有出现;好后缀在前面的字符串只出现的部分,其一定是出现在字符串开头;好后缀完整出现在前面的字符串。
那么很简单,第一种情况当然需要移动整个模式串的长度,第二种情况判断
suff[i] == i + 1,如果成立那么,对于
str[i, len - 1 - i]这之间的位置,
gs[j] = len - 1 -i;,
if (suff[i] == i + 1)这条if语句是确保在第二种情况下,
gs[j]只会被赋值一次,第三种情况,也就是最普通的情况了。而且,这三种情况下对
gs[]的赋值只会越来越小,这样保证了正确性,因为在移动不同的距离都能使得字符串匹配上后缀的情况下,移动最少的距离会保证解的完整性。
最后贴上完整代码:
#include <stdio.h>
#include <string.h>
#include <algorithm>
#define ASIZE 256
#define MAX_LINE 1024 * 128
using namespace std;
char str[MAX_LINE], templet[MAX_LINE];
int Bs[MAX_LINE], Gs[MAX_LINE], suff[MAX_LINE];
void preGetBs(char s[], int len, int bs[]) { for (int i = 0; i < ASIZE; i++) bs[i] = len; for (int i = 0; i < len - 1; i++) bs[s[i]] = len - i - 1; }
void suffix(char s[], int len, int suff[]) { suff[len - 1] = len; int g = len - 1, f; for (int i = len - 2; i >= 0; i--) if (i > g && suff[len - 1 - (f - i)] < i - g) suff[i] = suff[len - 1 - (f - i)]; else { if (i < g) g = i; f = i; while (g >= 0 && s[g] == s[len - 1 - (f - g)]) --g; suff[i] = f - g; } }
void preGetGs(char s[], int len, int gs[]) { int i, j; suffix(s, len, suff); for (i = 0; i < len; i++) gs[i] = len; for (j = 0, i = len - 1; i >= 0; i--) if (suff[i] == i + 1) for (; j < len - 1 - i; j++) if (gs[j] == len) gs[j] = len - 1 -i; for (i = 0; i <= len - 2; i++) gs[len - 1 -suff[i]] = len - 1 - i; }
int main()
{
gets(str);
gets(templet);
/* predealing */
preGetBs(templet, strlen(templet), Bs);
preGetGs(templet, strlen(templet), Gs);
/* matching */
/* BM */
int i, j = 0, m = strlen(templet), n = strlen(str);
while (j + m <= n) {
for (i = m - 1; i >= 0 && templet[i] == str[i + j]; i--);
if (i < 0)
printf("%d\n", j), j += Bs[0];
else
j += max(Gs[i], Bs[str[i + j]] - (m - 1 - i));
}
return 0;
}
参考:
字符串匹配的Boyer-Mo
c77d
ore算法;作者: 阮一峰
算法代码参考;英文

相关文章推荐
- Boyer-Moore(BM)算法,文本查找,字符串匹配问题
- BM字符串匹配算法
- 字符串匹配算法-BM
- KMP字符串匹配算法解析
- 字符串匹配常见算法(BF,RK,KMP,BM,Sunday)
- sunday、kmp、 bm、 horspool字符串匹配算法 code
- BM字符串匹配算法
- BM和KMP字符串匹配算法学习
- BF,KMP,BM三种字符串匹配算法性能比较
- 字符串匹配算法 之 BM(Boyer-Moore)
- 字符串匹配(BF,BM,Sunday,KMP算法解析)
- BM(Boyer-Moore)字符串匹配算法的实现(一种有效常用的字符串匹配算法)
- KMP、BM、Sunday等字符串匹配算法及实现
- 几种字符串匹配算法性能简单实验对比
- 字符串匹配算法:KMP算法与BM算法比较
- kmp字符串匹配算法
- 字符串匹配算法-kmp
- 字符串匹配算法-有限状态机
- 字符串匹配(string matching)算法之一 (Naive and Rabin_Karp)
- 字符串匹配算法研究(二)