Distributed System: DFS系列 -- NFS, AFS & HDFS(GFS)
2017-04-05 10:38
381 查看
分布式文件系统是分布式系统的基石,本文从较上层的高度对常见的三个分布式文件系统:NFS、AFS和HDFS进行介绍。
分布式文件系统有两大模式:
1) Remote Access Model.
在这种模式下,非本地文件不会复制到本地,所以对非本地文件的读取和修改,利用RPC进行。利用这种模式,可以减少对consistency的考虑(适用于对consistency要求高的场合),从而实现POSIX的要求:Strict one copy semantics. 这个标准又称为UNIX semantic:每次每个client读到的必须是最新的值。

NFS (Network File System)和HDFS用的都是这种模式。
2) Upload/ Download Model.
AFS(Andrew File System)用的是这种模式。所有非本地文件无论在读取还是修改,都首先会复制到本地。如果在本地进行了修改,则会在关闭了本地的文件后,更新服务器的文件。同时,通知其它的client,它们的文件不再是最新的。这种模式下,用的是session semantics: 不保证client读到的最新值。因为在修改文件内容的client关闭文件前,服务器是不会收到更新的内容的,也不会通知其它的client他们本地的文件已经过时了。
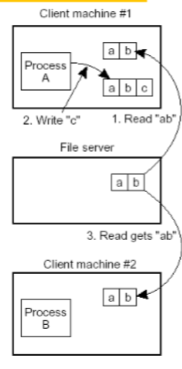
NFS (Networked File System)
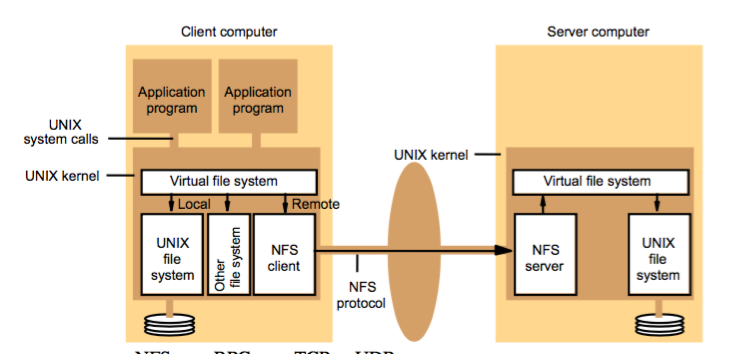
NFS是Linux上支持的分布式文件系统。最先由Sun公司开发,后来被广泛采用与Linux系统中。其表现为:可以把远程的文件夹mount在本地的文件系统的某个位置(挂载点)上。其不会复制远程的文件内容到本地,所有的读取和修改都是通过RPC(通过TCP或者UDP)进行。Windows的网上邻居采用的也是这个原理。
如下图的例子,people和users都是远程的文件夹,直接挂载在本地的文件树的student和staff节点(可以变一个名字)下:
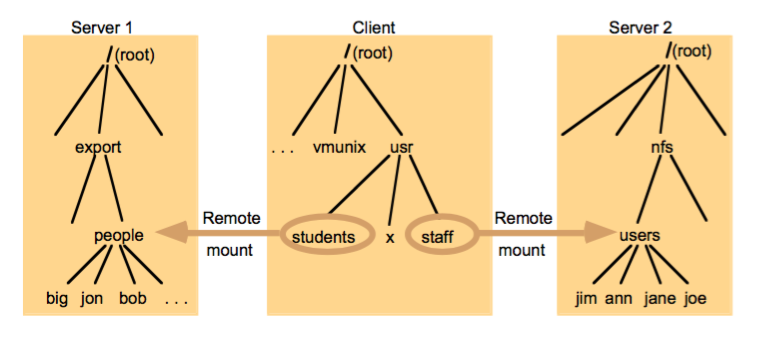
当linux进行系统调用,如read()的时候,系统发现students的实质是远程的people文件夹,便会把请求给NFS Client,接着进行RPC(Remote Procedure Call)去读取远程的文件夹(目录实质也是一种特殊的文件)内容。
AFS (Andrew File System)
Andrew File System的比起NFS的优点在于其的可拓展性(Scalability)。因为其把读或者写的文件都是复制到本地,所以在读比写更多的环境下,这种文件系统能大大地减少减少和服务器的交流(减少网络延时的影响),提高反应速度,所以能轻松应对更多的读请求。(可拓展性)。
由于其是upload/ download model的形式,所以是session semantics的。不能保证读到的是最新内容。
其运作机制如下:
对于系统调用,如open, read, write, close纷纷统一发送到kerne。其中,有可能会调用venus的只有open和close。其余的read和write对本地的copy进行。
如果是远程的文件,则首先看看有没有本地备份或者现在的call back promise是否valid。
这里需要通知Venus去读取远程文件分为两种情况:
1/ 没有本地的copy;
2/ 有本地的copy,但是call back promise 是 invalid,代表当前的copy已经过时了,服务器上有最新的需要重新获取。
否则,有本地备份且valid的call back promise的情况下,可以直接从本地的copy读取内容。
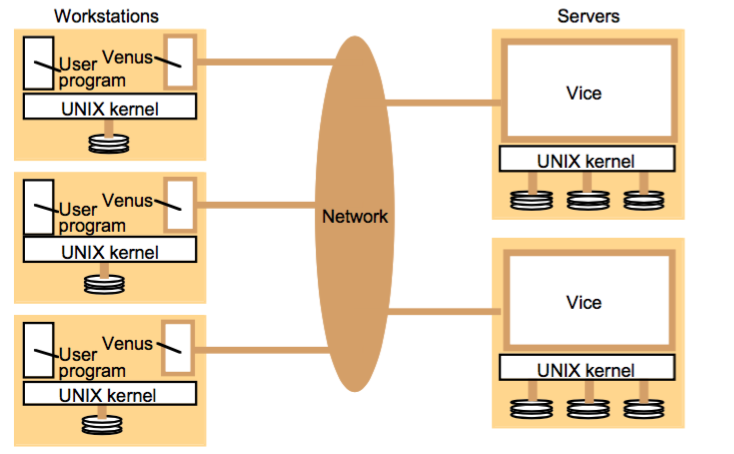
callback promise什么时候会Invalid呢?就是在某个client对本地的文件进行修改后,close之后,有更新的情况下,venus会给vice发送更新的通知并上传。Vice更新后,会给所有的client 发送callback promise cancel的信号,使得callback promise变为Invalid。
AFS在表面上和NFS无异,都是把远程的文件挂载在本地的文件系统。但是,其内部的作用机制是不同的。
HDFS - Hadoop Distributed File System (GFS)
HDFS是目前应用最广的分布式文件系统,其遵循的是UNIX semantic。每次读到的都是最新的value。其一致性的算法是PAXOS的投票机制,在ZooKeeper当中由Follower投票决定。
关于ZooKeeper的介绍在前述的ZooKeeper系列当中已经有介绍了,现在来说说HDFS的其它方面。
HDFS的理念是以数量代替质量。怎么说呢?我利用很多的一般的机器和三份Replication的策略,来代替数量少的极品机器的方式来保证Failure Rate。
其结构图如下:
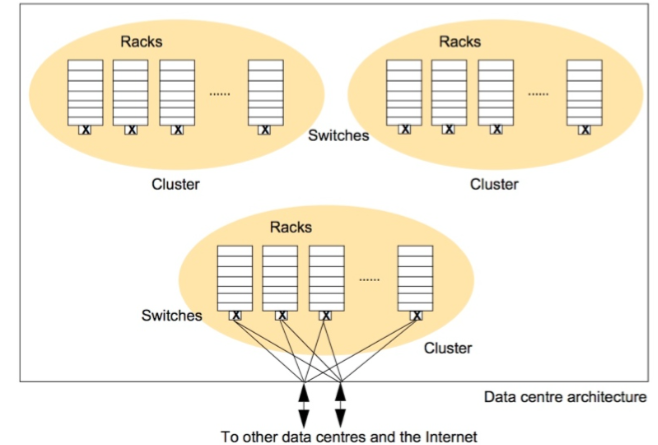
每个Data Center有很多的rack,每个rack有约30台机器。可以看出来,HDFS需要很多的一般机器来实现其复制容灾的性能。
Chunk为单位的存储方式:
HDFS当中,文件都被分为多个chunk,每个chunk是64MBytes. HDFS的策略是每个chunk均有3个replications,一般位于不同的physical nodes上。
HDFS的文件读取和写入:
由于HDFS是把所有的文件分成chunks的,那我需要读一个文件时候,怎么知道读哪些chunk呢?这就需要去问HDFS的Master了(NameNode)。它存着所有的文件及其对应的chunks的位置。每次读写文件的步骤如下:
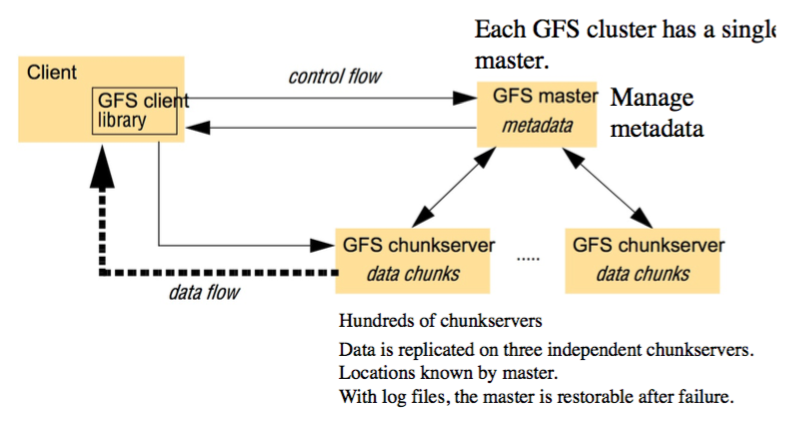
1) Client calls master with file name and chunk index.
2) Master returns chunk identifier and the locations of replicas.
3) Client makes call on a chunk server (Primary Chunk Server)for the chunk and it is processed sequentially with no caching. It may ask for and receive several chunks. (from Primary Chunk Server).
写也是类似的流程:
1) Client calls master with file name and chunk index.
2) Master returns chunk identifier and the locations of replicas. One is designated as the primary.
3) The client sends all data to all replicas. The primary coordinates with replicas to update files consistently across replicas.
分布式文件系统有两大模式:
1) Remote Access Model.
在这种模式下,非本地文件不会复制到本地,所以对非本地文件的读取和修改,利用RPC进行。利用这种模式,可以减少对consistency的考虑(适用于对consistency要求高的场合),从而实现POSIX的要求:Strict one copy semantics. 这个标准又称为UNIX semantic:每次每个client读到的必须是最新的值。
NFS (Network File System)和HDFS用的都是这种模式。
2) Upload/ Download Model.
AFS(Andrew File System)用的是这种模式。所有非本地文件无论在读取还是修改,都首先会复制到本地。如果在本地进行了修改,则会在关闭了本地的文件后,更新服务器的文件。同时,通知其它的client,它们的文件不再是最新的。这种模式下,用的是session semantics: 不保证client读到的最新值。因为在修改文件内容的client关闭文件前,服务器是不会收到更新的内容的,也不会通知其它的client他们本地的文件已经过时了。
NFS (Networked File System)
NFS是Linux上支持的分布式文件系统。最先由Sun公司开发,后来被广泛采用与Linux系统中。其表现为:可以把远程的文件夹mount在本地的文件系统的某个位置(挂载点)上。其不会复制远程的文件内容到本地,所有的读取和修改都是通过RPC(通过TCP或者UDP)进行。Windows的网上邻居采用的也是这个原理。
如下图的例子,people和users都是远程的文件夹,直接挂载在本地的文件树的student和staff节点(可以变一个名字)下:
当linux进行系统调用,如read()的时候,系统发现students的实质是远程的people文件夹,便会把请求给NFS Client,接着进行RPC(Remote Procedure Call)去读取远程的文件夹(目录实质也是一种特殊的文件)内容。
AFS (Andrew File System)
Andrew File System的比起NFS的优点在于其的可拓展性(Scalability)。因为其把读或者写的文件都是复制到本地,所以在读比写更多的环境下,这种文件系统能大大地减少减少和服务器的交流(减少网络延时的影响),提高反应速度,所以能轻松应对更多的读请求。(可拓展性)。
由于其是upload/ download model的形式,所以是session semantics的。不能保证读到的是最新内容。
其运作机制如下:
对于系统调用,如open, read, write, close纷纷统一发送到kerne。其中,有可能会调用venus的只有open和close。其余的read和write对本地的copy进行。
如果是远程的文件,则首先看看有没有本地备份或者现在的call back promise是否valid。
这里需要通知Venus去读取远程文件分为两种情况:
1/ 没有本地的copy;
2/ 有本地的copy,但是call back promise 是 invalid,代表当前的copy已经过时了,服务器上有最新的需要重新获取。
否则,有本地备份且valid的call back promise的情况下,可以直接从本地的copy读取内容。
callback promise什么时候会Invalid呢?就是在某个client对本地的文件进行修改后,close之后,有更新的情况下,venus会给vice发送更新的通知并上传。Vice更新后,会给所有的client 发送callback promise cancel的信号,使得callback promise变为Invalid。
AFS在表面上和NFS无异,都是把远程的文件挂载在本地的文件系统。但是,其内部的作用机制是不同的。
HDFS - Hadoop Distributed File System (GFS)
HDFS是目前应用最广的分布式文件系统,其遵循的是UNIX semantic。每次读到的都是最新的value。其一致性的算法是PAXOS的投票机制,在ZooKeeper当中由Follower投票决定。
关于ZooKeeper的介绍在前述的ZooKeeper系列当中已经有介绍了,现在来说说HDFS的其它方面。
HDFS的理念是以数量代替质量。怎么说呢?我利用很多的一般的机器和三份Replication的策略,来代替数量少的极品机器的方式来保证Failure Rate。
其结构图如下:
每个Data Center有很多的rack,每个rack有约30台机器。可以看出来,HDFS需要很多的一般机器来实现其复制容灾的性能。
Chunk为单位的存储方式:
HDFS当中,文件都被分为多个chunk,每个chunk是64MBytes. HDFS的策略是每个chunk均有3个replications,一般位于不同的physical nodes上。
HDFS的文件读取和写入:
由于HDFS是把所有的文件分成chunks的,那我需要读一个文件时候,怎么知道读哪些chunk呢?这就需要去问HDFS的Master了(NameNode)。它存着所有的文件及其对应的chunks的位置。每次读写文件的步骤如下:
1) Client calls master with file name and chunk index.
2) Master returns chunk identifier and the locations of replicas.
3) Client makes call on a chunk server (Primary Chunk Server)for the chunk and it is processed sequentially with no caching. It may ask for and receive several chunks. (from Primary Chunk Server).
写也是类似的流程:
1) Client calls master with file name and chunk index.
2) Master returns chunk identifier and the locations of replicas. One is designated as the primary.
3) The client sends all data to all replicas. The primary coordinates with replicas to update files consistently across replicas.

相关文章推荐
- Distributed System: DFS系列 -- NFS, AFS & HDFS(GFS)
- Distributed System: DFS系列 -- NFS, AFS & HDFS(GFS)
- Distributed System: DFS系列 -- NFS, AFS & HDFS(GFS)
- Distributed System: DFS系列 -- NFS, AFS & HDFS(GFS)
- Distributed System: DFS系列 -- NFS, AFS & HDFS(GFS)
- Distributed System: DFS系列 -- NFS, AFS & HDFS(GFS)
- 后端分布式系列:分布式存储-HDFS 与 GFS 的设计差异
- 【HDU】4514 - 湫湫系列故事——设计风景线(树的直径 & 并查集 & dfs)
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
- HDU - 4507 吉哥系列故事——恨7不成妻 (数位DP&记忆化dfs)好题
- hadoop学习笔记之<hadoop fs和hdfs dfs命令>
- Hadoop HDFS概念学习系列之hadoop里dfs和fs的区别(二十三)
- 【Twitter Storm系列】flume-ng+Kafka+Storm+HDFS 实时系统搭建<转>
- 后端分布式系列:分布式存储-HDFS 与 GFS 的设计差异
- 后端分布式系列:分布式存储-HDFS 与 GFS 的设计差异
- Distributed Systems笔记-NFS、AFS、GFS
- Red Hat® GFS vs. NFS: Improving performance and scalability
- UVa 524 Prime Ring Problem (数论&DFS)
- 【量化小讲堂-Python&Pandas系列08】通过逐笔数据计算主力资金流数据
- POJ2965 The Pilots Brothers' refrigerator (精妙方法秒杀DFS BFS)