使用多任务学习方法进行人脸特征点和属性检测
2017-04-02 21:31
302 查看
前言
这篇文章总结一下最近的工作,参考展鹏大神的14年论文
[ECCV2014]Facial Landmark Detection by MultiTask
15年的论文在14年的基础上做了进一步的优化,输入图像更大了,可以关注一下。
[IEEE15]Learning Deep Representation for Face Alignment with Auxiliary Attributes
一些细节
1、第四个卷积层可以使用locally connected layer代替,实现可参考贾扬清大神的回复https://github.com/BVLC/caffe/issues/837
2、每一个层后面都有一个激活层,包括预处理完数据之后。使用ReLU激活函数即可,landmark检测那路最后一处使用tanh激活函数
,因为坐标值可能为负值。文章中提到使用absolute tanh函数,这个问题水有点深,暂不讨论。
3、不同的任务共享同一个底部feature,这其实就是多任务学习的一个很神奇的地方。
4、使用z-score的方法进行输入图像预处理
5、像素点坐标都要除以40,使坐标转成[0,1]之间的浮点数,当然可以有负值和超过1的值。
准备工作
1、改造caffe以支持多标签。具体可参考https://zhuanlan.zhihu.com/p/22190532
2、训练数据准备
作者在官网上提供了一个MTFL的数据集,其中包含了10000张人脸和相应的属性。然后做增广处理,augmentation可以aggressive一点,有一小部分人脸没被框住也是可以接受的。三种增广方式:平移(平移后仍要包含大部分人脸区域)、旋转(±30度以内)、缩放(应有一部分图片的衣领露出来)。变换的尺度加一点随机性。当然也可以加入图像压缩率变换或者镜像旋转,具体可参考论文《Face
Alignment by Deep Convolutional Network with Adaptive Learning Rate》,也要感谢志文大神的帮助
数据是非常重要的,如果增广不够,landmark的损失降不到理想值而且最终loss曲线依然震荡的很厉害,当增广到130W数据时,5个点的landmark loss
4000
可以降到0.003,增广到270W时,可以降到0.0015以下,具体的说,假如5个点有一个点的x坐标偏移了1个像素,那么对应的loss就是(1/40)^2/2=0.0003125,五个点的x、y坐标分别偏移了1个像素,对应的loss:0.003125,我的试验最终是增广到了500W,landmark训练loss可以降到0.00065。
如果pose属性标的不好,会影响其他任务的准确度。训练数据生成lmdb时要进行shuffle处理。
实现
1、多任务权值的设置
分类任务如glass、male、smile、pose采用softmax损失层
回归任务landmark采用EuclideanLoss层
由于损失函数不一样,根据论文中的公式
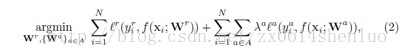
需要对任务的损失加一个

权重,我的实现是在landmark的EuclideanLoss层参数中设置loss
weight为1,glass、male、smile的loss weight设为0.1,pose的loss weight设为0.3。这些超参的设置是经验性的。
2、训练参数的设置
batch size: 256或者128
learning rate采用fixed的方式,base_lr: 0.003
weight decay: 0.0005
3、early-stop
没有完全按照论文的方式实现,在论文中,不同任务是依次停止的,在我的训练过程中,采用的是全部停止辅助任务的方式,因为我发现如果依次停止训练任务,被停止的任务精度会随着其他任务的训练产生明显的下降,而如果将所有辅助任务停止,虽然辅助任务的精度会随着landmark任务的训练下降,但是由于landmark的loss已经很小了,对底层权值的更新影响不会太大,因此精度下降的幅度还是可以接受的。
由于论文中的主任务是landmark的检测,因此牺牲辅助任务是合理的,而且没有辅助任务,主任务的损失不会下降到如此低的值。最初的实验只有主任务不加辅助任务时landmark的loss在0.004-0.01之间进行震荡,可以看到多任务约束带来的影响是很明显的。
在最后对landmark进行finetune训练前,需要将weight decay设置成0,即使是0.0005对网络权值的更新也是灾难性的。
4、68个点的训练
在训练68个点的检测过程中,要采用finetune的方法,前三层的参数保持一样,从第四层卷积层开始权值不一样了,而不是在InnerProduct layer之后。这也是一个很神奇的地方。
5点以及属性检测
5点在AFLW测试集上的测试情况

68点检测

68点在300-W测试集上的测试情况
以上就是本人最近的一个工作总结,让我感受到了深度学习方法的神奇之处,希望可以和各路大神共同探讨
这篇文章总结一下最近的工作,参考展鹏大神的14年论文
[ECCV2014]Facial Landmark Detection by MultiTask
15年的论文在14年的基础上做了进一步的优化,输入图像更大了,可以关注一下。
[IEEE15]Learning Deep Representation for Face Alignment with Auxiliary Attributes
一些细节
1、第四个卷积层可以使用locally connected layer代替,实现可参考贾扬清大神的回复https://github.com/BVLC/caffe/issues/837
2、每一个层后面都有一个激活层,包括预处理完数据之后。使用ReLU激活函数即可,landmark检测那路最后一处使用tanh激活函数
,因为坐标值可能为负值。文章中提到使用absolute tanh函数,这个问题水有点深,暂不讨论。
3、不同的任务共享同一个底部feature,这其实就是多任务学习的一个很神奇的地方。
4、使用z-score的方法进行输入图像预处理
5、像素点坐标都要除以40,使坐标转成[0,1]之间的浮点数,当然可以有负值和超过1的值。
准备工作
1、改造caffe以支持多标签。具体可参考https://zhuanlan.zhihu.com/p/22190532
2、训练数据准备
作者在官网上提供了一个MTFL的数据集,其中包含了10000张人脸和相应的属性。然后做增广处理,augmentation可以aggressive一点,有一小部分人脸没被框住也是可以接受的。三种增广方式:平移(平移后仍要包含大部分人脸区域)、旋转(±30度以内)、缩放(应有一部分图片的衣领露出来)。变换的尺度加一点随机性。当然也可以加入图像压缩率变换或者镜像旋转,具体可参考论文《Face
Alignment by Deep Convolutional Network with Adaptive Learning Rate》,也要感谢志文大神的帮助
数据是非常重要的,如果增广不够,landmark的损失降不到理想值而且最终loss曲线依然震荡的很厉害,当增广到130W数据时,5个点的landmark loss
4000
可以降到0.003,增广到270W时,可以降到0.0015以下,具体的说,假如5个点有一个点的x坐标偏移了1个像素,那么对应的loss就是(1/40)^2/2=0.0003125,五个点的x、y坐标分别偏移了1个像素,对应的loss:0.003125,我的试验最终是增广到了500W,landmark训练loss可以降到0.00065。
如果pose属性标的不好,会影响其他任务的准确度。训练数据生成lmdb时要进行shuffle处理。
实现
1、多任务权值的设置
分类任务如glass、male、smile、pose采用softmax损失层
回归任务landmark采用EuclideanLoss层
由于损失函数不一样,根据论文中的公式
需要对任务的损失加一个
权重,我的实现是在landmark的EuclideanLoss层参数中设置loss
weight为1,glass、male、smile的loss weight设为0.1,pose的loss weight设为0.3。这些超参的设置是经验性的。
2、训练参数的设置
batch size: 256或者128
learning rate采用fixed的方式,base_lr: 0.003
weight decay: 0.0005
3、early-stop
没有完全按照论文的方式实现,在论文中,不同任务是依次停止的,在我的训练过程中,采用的是全部停止辅助任务的方式,因为我发现如果依次停止训练任务,被停止的任务精度会随着其他任务的训练产生明显的下降,而如果将所有辅助任务停止,虽然辅助任务的精度会随着landmark任务的训练下降,但是由于landmark的loss已经很小了,对底层权值的更新影响不会太大,因此精度下降的幅度还是可以接受的。
由于论文中的主任务是landmark的检测,因此牺牲辅助任务是合理的,而且没有辅助任务,主任务的损失不会下降到如此低的值。最初的实验只有主任务不加辅助任务时landmark的loss在0.004-0.01之间进行震荡,可以看到多任务约束带来的影响是很明显的。
在最后对landmark进行finetune训练前,需要将weight decay设置成0,即使是0.0005对网络权值的更新也是灾难性的。
4、68个点的训练
在训练68个点的检测过程中,要采用finetune的方法,前三层的参数保持一样,从第四层卷积层开始权值不一样了,而不是在InnerProduct layer之后。这也是一个很神奇的地方。
5点以及属性检测
5点在AFLW测试集上的测试情况
68点检测
68点在300-W测试集上的测试情况
以上就是本人最近的一个工作总结,让我感受到了深度学习方法的神奇之处,希望可以和各路大神共同探讨

相关文章推荐
- 使用多任务学习方法进行人脸特征点和属性检测
- 结合OpenCV摄像头使用Dlib库进行人脸检测及标注特征点和提取人脸特征-Python
- AdaBoost中利用Haar特征进行人脸识别算法分析与总结2——级联分类器与检测过程 .
- 利用OpenCV的Haar特征目标检测方法进行人脸识别的尝试(一)
- 使用OpenCV进行人脸关键点检测
- opencv结合dlib进行人脸特征点的检测
- 使用Dlib库进行人脸检测,人脸对齐和人脸识别
- 对adaboost+haar特征进行人脸检测的原理的认识
- OpenCV之feature2d 模块. 2D特征框架(2)特征描述 使用FLANN进行特征点匹配 使用二维特征点(Features2D)和单映射(Homography)寻找已知物体 平面物体检测
- 使用Dlib库进行人脸检测与对齐
- python中使用OpenCV进行人脸检测的例子
- 使用滑动窗口进行人脸检测 Face detection with a sliding window
- AdaBoost中利用Haar特征进行人脸识别算法分析与总结2——级联分类器与检测过程
- AdaBoost中利用Haar特征进行人脸识别算法分析与总结2——级联分类器与检测过程
- 使用Dlib库进行68个人脸特征点检测
- 使用python+OpenCV进行人脸检测
- 利用Adaboost和LBP特征进行人脸检测
- 使用caffe的python接口进行特征提取和人脸验证
- 使用OpenCV进行人脸检测(Viola-Jones人脸检测方法)