Hadoop生态之Awesome系列

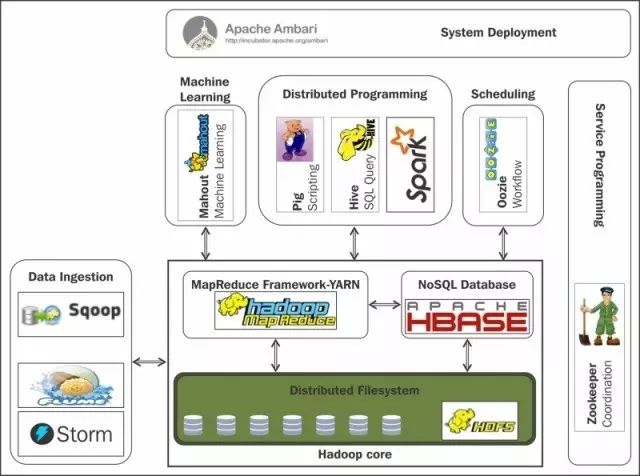
Hadoop,一个神圣的大数据分布式系统基础架构,LOGO是个黄色的大象,围绕Hadoop应运而生了五花八门的开源工具,Hadoop的整个生态圈那叫一个精彩纷呈,琳琅满目,眼花缭乱,争奇斗艳...如此也导致刚入门这个圈子的朋友,很容易得严重的技术学习、选型恐惧症。
如何玩转这头大象,让它飞起来,那必须对这个生态圈有个High Level的抽象了解,有哪些类型的框架?每个类型的框架有哪些类似开源产品?
本文不会对所有的技术框架进行详细的讲解,只是提供一个同步更新的列表,基于Github上的Awesome系列来展开,在英文的基础上做了翻译和一些场景的基本对比说明。

这是Awesome系列Hadoop及其生态资源的一览表。其他系列比如 Awesome PHP, Awesome Python大数据生态也有一份更完整的列表 Awesome Bigdata,中文翻译参见阿里云栖社区 《史上最全的“大数据”学习资源》
Awesome Hadoop
Hadoop
YARN作业调度
NoSQL
类SQL处理框架
数据管理
工作流、生命周期、治理
数据摄取和集成
领域专用语言DSL
开发库和工具
实时数据处理
分布式计算和编程
Packaging, Provisioning and Monitoring
Monitoring
Search
Security
Benchmark
Machine learning and Big Data analytics
Misc.
Resources
Websites
Presentations
Books
Hadoop and Big Data Events
Other Awesome Lists
Hadoop
Apache Hadoop - 分布式处理架构,结合了 Common工具、MapReduce(并行处理)、YARN(作业调度)和HDFS(分布式文件系统)
Apache Tez - Tez构建于Hadoop YARN之上,是一个通用的数据流编程框架。通过提供强力和灵活的引擎,执行任意DAG(有向无环图 Direct Acyclic Graph)类型作业,来批量或者交互式的处理数据。Tez已经被Hive、 Pig、其他Hadoop生态体系内的框架和一些商用软件(比如ETL工具)所采用,用以替换Hadoop MapReduce作为基础执行引擎/计算框架。
SpatialHadoop - SpatialHadoop是一个开源的MapReduce扩展,专门用于在ApacheHadoop集群上处理空间数据
GIS Tools for Hadoop - 为Hadoop框架提供大数据空间分析功能
Elasticsearch Hadoop - 通俗来讲就是,将具有海量数据存储和深度处理能力的Hadoop,与实时搜索和分析的Elasticsearch连接起来。https://www.elastic.co/products/hadoop
dumbo - Python模块,方便编写和运行Hadoop程序。
hadoopy - 用Cython编写的Python MapReduce库
mrjob - mrjob是一个Python 2.5+包,用以编写和运行Hadoop Streaming作业
pydoop - Pydoop提供了Hadoop API的Python包
hdfs-du - HDFS的交互式可视化的WEB UI, 来自twitter。
White Elephant - Hadoop日志的聚合和仪表盘,可视化Hadoop集群跨用户的使用情况UI,来自Linkedin
Kiji Project
Genie - Genie是Netflix开源的提供Hadoop, Hive, Pig作业和资源调度工具。
Apache Kylin - eBay开源的一款分布式分析引擎,可以在Hadoop支持的含量数据集上提供SQL接口和多维度的分析(OLAP)。 场景在预计算,用户指定dimensions和要计算的metric,kylin通过MR将结果保存在HBase中,后续读取直接读HBase。 适合那种业务清楚的知道自己要分析什么的场景。查询模式比较固定,只不过所查看的时间不同的场景。注意的点是要避免维度灾难。 其核心是Cube,cube是一种预计算技术,基本思路是预先对数据作多维索引,查询时只扫描索引而不访问原始数据从而提速。
Crunch - Go编写的工具包,用于ETL和特征提取
Apache Ignite - 分布式内存型计算平台
YARN作业调度
YARN是一个分布式的资源管理系统,用以提高分布式的集群环境下的资源利用率,这些资源包括内存、IO、网络、磁盘等。其产生的原因是为了解决原MapReduce框架的不足。新的 Hadoop MapReduce 框架命名为 MapReduceV2 或者叫 Yarn。
Apache Slider - Apache内部孵化的二级项目,目的是将用户的已有服务或者应用直接部署到YANR上。Slider自带了HBase On YARN,Storm On YARN 和Accumulo On YARN三个实现。
Apache Twill - Twill也是内部孵化项目,目前已经是顶级项目。它是为简化YARN上应用程序开发而成立的项目,该项目把与YARN相关的重复性的工作封装成库,使得用户可以专注于自己的应用程序逻辑。
mpich2-yarn - YARN上运行 MPICH2 程序,来自Alibaba。 (注:MPI 消息传递接口(Message Passing Interface)基于消息传递的并行程序,MPI并不是一种新的开发语言,它是一个定义了可以被C、C++和Fortran程序调用的函数库。 消息传递指的是并行执行的各个进程具有自己独立的堆栈和代码段,作为互不相关的多个程序独立执行,进程之间的信息交互完全通过显示地调用通信函数来完成。)
NoSQL
下一代数据库Not Only SQL,更多面向如下几点:非关系型,分布式,开源和水平扩展。
Apache HBase - Apache HBase 非典型的列式数据库,只是按照列族来分割文件,但是存储是Key-Value,必须基于RowId来查询才快。
Apache Phoenix - A SQL skin over HBase supporting secondary indices
happybase - A developer-friendly Python library to interact with Apache HBase.
Hannibal - Hannibal is tool to help monitor and maintain HBase-Clusters that are configured for manual splitting.
Haeinsa - Haeinsa is linearly scalable multi-row, multi-table transaction library for HBase
hindex - Secondary Index for HBase
Apache Accumulo - The Apache Accumulo™ sorted, distributed key/value store is a robust, scalable, high performance data storage and retrieval system.
OpenTSDB - The Scalable Time Series Database
Apache Cassandra
Apache Kudu - Kudu provides a combination of fast inserts/updates and efficient columnar scans to enable multiple real-time analytic workloads across a single storage layer, complementing HDFS and Apache HBase.
Kudu目标是很快的分析数据,其希望弥补HDFS和HBase之间的gap,前者是重离线批量,后者重在线随机。 整体而言,Kudu似乎想做一个集合OLTP/OLAP的东西,在线写入,高可用,可选的一致性,即时快速的扫描分析,但是目前感觉定位偏向OLAP。
Druid - Druid is an open-source analytics data store designed for business intelligence (OLAP) queries on event data. Druid provides low latency (real-time) data ingestion, flexible data exploration, and fast data aggregation. High-performance, column-oriented, distributed data store.
Druid是一个实时处理时序数据的Olap数据库,因为它的索引首先按照时间分片,查询的时候也是按照时间线去路由索引。 功能介于PowerDrill和Dremel之间,它几乎实现了Dremel的所有功能,并且从PowerDrill吸收一些有趣的数据格式。 用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。 数据集由三种组件构成, Timestamp列, Dimension列和Metric列(Druid Documentation)
类SQL处理框架
Apache Hive - The Apache Hive data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL
Hive是Facebook开源的一个数据仓库或者说基于类SQL语言的查询分析工具,用于读、写、管理位于分布式存储内的海量数据。 Hive背后可以选择不同的引擎,比如hive on tez, hive on mr, hive on yarn, hive on spark等; Hive也可以做其他框架的数据源比如spark on hive,和上面hive on spark的区别就是互为提供方而已。
Apache Phoenix A SQL skin over HBase supporting secondary indices
Phoenix 可以当做 HBase 的 SQL 驱动,完全JAVA编写。Phoenix 使得HBase支持通过 JDBC 的方式进行访问,并将你的 SQL 查询转成 HBase 的扫描和相应的动作。 让Hadoop为低延迟的应用程序提供OLTP和业务分析功能,支持二级索引。 可以与Hadoop产品集成,比如Spark, Hive, Pig, Flume, MapReduce。
Apache HAWQ (incubating) - Apache HAWQ is a Hadoop native SQL query engine that combines the key technological advantages of MPP database with the scalability and convenience of Hadoop
Lingual - SQL interface for Cascading (MR/Tez job generator)
Cloudera Impala
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,其本质上是一个MPP数据库(Massively Parallel Processing,适合小集群100以内,低并发的50左右的场景) Hive适合于长时间的批处理查询分析,而Impala适合于实时交互式SQL查询,Impala给数据分析人员提供了快速实验、验证想法的大数据分析工具。可以先使用hive进行数据转换处理,之后使用Impala在Hive处理后的结果数据集上进行快速的数据分析。
Presto - Distributed SQL Query Engine for Big Data. Open sourced by Facebook.
分布式大数据SQL查询引擎,Facebook开源产品。适用于交互式分析查询,数据量支持GB到PB字节。 JAVA8写的,代码质量非常高。设计:纯内存,没有容错,一个task失败就整个query fail。需要注意调整内存相关,线程数等参数,容易OOM。benchmark还行。支持标准SQL。 Presto背后所使用的执行模式与Hive有根本的不同,它没有使用MapReduce,大部分场景下比hive快一个数量级,其中的关键是所有的处理都在内存中完成。
Apache Tajo - Data warehouse system for Apache Hadoop
Apache Drill - Schema-free SQL Query Engine
Drill 是基于 Google Dremel的开源实现。 On a broader category level, Drill, Impala, Hive and Spark SQL all fit into the SQL-on-Hadoop category. But in terms of differentiation capabilities, Drill has the ability to allow data exploration on datasets without having to define any schema definitions upfront in the Hive metastore. Whether your data is text files, JSON files, or whatever other file formats, Drill is built to work with schema that is dynamic, as well as data that is complex. Drill differs from Impala in that it can handle nested data better, and it can also work with data without having to define schema definitions upfront. From a performance standpoint, Drill and Impala are targeting interactive use cases, so both are optimized in terms of performance and SLAs. 上述表达的Drill场景也就是schema-free这个特性。
Apache Trafodion
Apache Spack SQL - Spark SQL is Apache Spark's module for working with structured data. Seamlessly mix SQL queries with Spark programs. Connect to any data source the same way.
Run unmodified Hive queries on existing data. Connect through JDBC or ODBC. 基于Spark平台上的一个OLAP框架,本质上也是基于DAG的MPP,基本思路是增加机器来并行计算,从而提高查询速度。
数据管理
Apache Calcite - A Dynamic Data Management Framework
Apache Atlas - Metadata tagging & lineage capture suppoting complex business data taxonomies
Apache Parquet - Parquet源自于Google Dremel系统,不同于Drill是Dremel的完整开源实现, Parquet只是Dremel中的数据存储引擎。 Parquet最初的设计动机是存储嵌套式数据,比如Protocolbuffer,thrift,json等,将这类数据存储成列式格式,以方便对其高效压缩和编码,且使用更少的IO操作取出需要的数据,这也是Parquet相比于Apache ORC的优势,它能够透明地将Protobuf和thrift类型的数据进行列式存储,在Protobuf和thrift被广泛使用的今天,与Parquet进行集成,是一件非容易和自然的事情。 除了上述优势外,相比于ORC, Parquet没有太多其他可圈可点的地方,比如它不支持update操作(数据写成后不可修改),不支持ACID等。
工作流/生命周期/治理
Apache Oozie - Apache Oozie
Azkaban
Apache Falcon - Data management and processing platform
Apache NiFi - A dataflow system
Apache AirFlow - Airflow is a workflow automation and scheduling system that can be used to author and manage data pipelines
Luigi - Python package that helps you build complex pipelines of batch jobs
数据摄取和集成
Apache Flume - Apache Flume
Suro - Netflix's distributed Data Pipeline
Apache Sqoop - Apache Sqoop
Apache Kafka - Apache Kafka
Gobblin from LinkedIn - Universal data ingestion framework for Hadoop
领域专用语言DSL
DSL = Domain Specific Language
Apache Pig - Yahoo!出品,用于处理数据分析程序的高级查询语言
Apache DataFu - 由LinkedIn开发的针对Hadoop和Pig的用户定义的函数集合
vahara - Machine learning and natural language processing with Apache Pig
packetpig - Open Source Big Data Security Analytics
akela - Mozilla's utility library for Hadoop, HBase, Pig, etc.
seqpig - Simple and scalable scripting for large sequencing data set(ex: bioinfomation) in Hadoop
Lipstick - Pig workflow visualization tool. Introducing Lipstick on A(pache) Pig
PigPen - PigPen is map-reduce for Clojure, or distributed Clojure. It compiles to Apache Pig, but you don't need to know much about Pig to use it.
开发库和工具
Kite Software Development Kit - A set of libraries, tools, examples, and documentation
gohadoop - Native go clients for Apache Hadoop YARN.
Hue - A Web interface for analyzing data with Apache Hadoop.
Apache Zeppelin - A web-based notebook that enables interactive data analytics
Jumbune - Jumbune is an open-source product built for analyzing Hadoop cluster and MapReduce jobs.
Apache Thrift
Apache Avro - 数据序列化系统
Elephant Bird - Twitter's collection of LZO and Protocol Buffer-related Hadoop, Pig, Hive, and HBase code.
Spring for Apache Hadoop
hdfs - A native go client for HDFS
Oozie Eclipse Plugin - A graphical editor for editing Apache Oozie workflows inside Eclipse.
Hydrosphere Mist - a service for exposing Apache Spark analytics jobs and machine learning models as realtime, batch or reactive web services.
snakebite
实时数据处理
Apache Beam - 为统一的模型以及一套用于定义和执行数据处理工作流的特定SDK语言;
Apache Storm - Twitter流处理框架,也可用于YARN;
Apache Samza - 基于Kafka和YARN的流处理框架;
Apache Spark Streaming - 流处理框架。
Apache Flink - 针对流数据和批数据的分布式处理引擎,Java实现。link 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。 在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。 就框架本身与应用场景来说,Flink 更相似与 Storm,支持毫秒级计算,而Spark则只能支持秒级计算。
分布式计算和编程
Apache Spark - 内存集群计算框架,包括Spark SQL, Spark Streaming, MLlib机器学习和GraphX图计算等库
Spark Packages - A community index of packages for Apache Spark
SparkHub - A community site for Apache Spark
Apache Crunch - 一个简单的Java API,用于执行在普通的MapReduce实现时比较单调的连接、数据聚合等任务;
Cascading - Cascading is the proven application development platform for building data applications on Hadoop.
Apache Flink - 针对流数据和批数据的分布式处理引擎,Java实现。link 可以支持本地的快速迭代,以及一些环形的迭代任务。并且 Flink 可以定制化内存管理。 在这点,如果要对比 Flink 和 Spark 的话,Flink 并没有将内存完全交给应用层。这也是为什么 Spark 相对于 Flink,更容易出现 OOM 的原因(out of memory)。 就框架本身与应用场景来说,Flink 更相似与 Storm,支持毫秒级计算,而Spark则只能支持秒级计算
Apache Apex (incubating) - Enterprise-grade unified stream and batch processing engine.
Packaging, Provisioning and Monitoring
Apache Bigtop - Apache Bigtop: Packaging and tests of the Apache Hadoop ecosystem
Apache Ambari - Apache Ambari
Ganglia Monitoring System
ankush - A big data cluster management tool that creates and manages clusters of different technologies.
Apache Zookeeper - Apache Zookeeper
Apache Curator - ZooKeeper client wrapper and rich ZooKeeper framework
Buildoop - Hadoop Ecosystem Builder
Deploop - The Hadoop Deploy System
Jumbune - An open source MapReduce profiling, MapReduce flow debugging, HDFS data quality validation and Hadoop cluster monitoring tool.
inviso - Inviso is a lightweight tool that provides the ability to search for Hadoop jobs, visualize the performance, and view cluster utilization.
Search
ElasticSearch
Apache Solr
SenseiDB - Open-source, distributed, realtime, semi-structured database
Banana - Kibana port for Apache Solr
Search Engine Framework
Apache Nutch - Apache Nutch is a highly extensible and scalable open source web crawler software project.
Security
Apache Ranger - Ranger is a framework to enable, monitor and manage comprehensive data security across the Hadoop platform.
Apache Sentry - An authorization module for Hadoop
Apache Knox Gateway - A REST API Gateway for interacting with Hadoop clusters.
Project Rhino - Intel's open source effort to enhance the existing data protection capabilities of the Hadoop ecosystem to address security and compliance challenges, and contribute the code back to Apache.
Benchmark
Big Data Benchmark
HiBench
Big-Bench
hive-benchmarks
hive-testbench - Testbench for experimenting with Apache Hive at any data scale.
YCSB - The Yahoo! Cloud Serving Benchmark (YCSB) is an open-source specification and program suite for evaluating retrieval and maintenance capabilities of computer programs. It is often used to compare relative performance of NoSQL database management systems.
Machine learning and Big Data analytics
Apache Mahout
Oryx 2 - Lambda architecture on Spark, Kafka for real-time large scale machine learning
MLlib - MLlib is Apache Spark's scalable machine learning library.
R - R is a free software environment for statistical computing and graphics.
RHadoop including RHDFS, RHBase, RMR2, plyrmr
RHive RHive, for launching Hive queries from R
Apache Lens
Apache SINGA (incubating) - SINGA is a general distributed deep learning platform for training big deep learning models over large datasets
Misc.
Hive Plugins
UDF
http://nexr.github.io/hive-udf/
https://github.com/edwardcapriolo/hive_cassandra_udfs
https://github.com/livingsocial/HiveSwarm
https://github.com/ThinkBigAnalytics/Hive-Extensions-from-Think-Big-Analytics
https://github.com/karthkk/udfs
https://github.com/twitter/elephant-bird - Twitter
https://github.com/lovelysystems/ls-hive
https://github.com/stewi2/hive-udfs
https://github.com/klout/brickhouse
https://github.com/markgrover/hive-translate (PostgreSQL translate())
https://github.com/deanwampler/HiveUDFs
https://github.com/myui/hivemall (Machine Learning UDF/UDAF/UDTF)
https://github.com/edwardcapriolo/hive-geoip (GeoIP UDF)
https://github.com/Netflix/Surus
Storage Handler
https://github.com/dvasilen/Hive-Cassandra
https://github.com/yc-huang/Hive-mongo
https://github.com/balshor/gdata-storagehandler
https://github.com/karthkk/hive-hbase-json
https://github.com/sunsuk7tp/hive-hbase-integration
https://bitbucket.org/rodrigopr/redisstoragehandler
https://github.com/zhuguangbin/HiveJDBCStorageHanlder
https://github.com/chimpler/hive-solr
https://github.com/bfemiano/accumulo-hive-storage-manager
SerDe
https://github.com/rcongiu/Hive-JSON-Serde
https://github.com/mochi/hive-json-serde
https://github.com/ogrodnek/csv-serde
https://github.com/parag/HiveJsonSerde
https://github.com/electrum/hive-serde - JSON
https://github.com/karthkk/hive-hbase-json
Libraries and tools
https://github.com/forward3d/rbhive
https://github.com/synctree/activerecord-hive-adapter
https://github.com/hrp/sequel-hive-adapter
https://github.com/forward/node-hive
https://github.com/recruitcojp/WebHive
shib - WebUI for query engines: Hive and Presto
clive - Clojure library for interacting with Hive via Thrift
https://github.com/anjuke/hwi
https://code.google.com/a/apache-extras.org/p/hipy/
https://github.com/dmorel/Thrift-API-HiveClient2 (Perl - HiveServer2)
PyHive - Python interface to Hive and Presto
https://github.com/recruitcojp/OdbcHive
Hive-Sharp
HiveRunner - An Open Source unit test framework for hadoop hive queries based on JUnit4
Beetest - A super simple utility for testing Apache Hive scripts locally for non-Java developers.
Hive_test- Unit test framework for hive and hive-service
Flume Plugins
Flume MongoDB Sink
Flume HornetQ Channel
Flume MessagePack Source
Flume RabbitMQ source and sink
Flume UDP Source
Stratio Ingestion - Custom sinks: Cassandra, MongoDB, Stratio Streaming and JDBC
Flume Custom Serializers
Real-time analytics in Apache Flume
.Net FlumeNG Clients
Resources
Various resources, such as books, websites and articles.
Websites
Useful websites and articles
Hadoop Weekly
The Hadoop Ecosystem Table
Hadoop 1.x vs 2
Apache Hadoop YARN: Yet Another Resource Negotiator
Introducing Apache Hadoop YARN
Apache Hadoop YARN - Background and an Overview
Apache Hadoop YARN - Concepts and Applications
Apache Hadoop YARN - ResourceManager
Apache Hadoop YARN - NodeManager
Migrating to MapReduce 2 on YARN (For Users)
Migrating to MapReduce 2 on YARN (For Operators)
Hadoop and Big Data: Use Cases at Salesforce.com
All you wanted to know about Hadoop, but were too afraid to ask: genealogy of elephants.
What is Bigtop, and Why Should You Care?
Hadoop - Distributions and Commercial Support
Ganglia configuration for a small Hadoop cluster and some troubleshooting
Hadoop illuminated - Open Source Hadoop Book
NoSQL Database
10 Best Practices for Apache Hive
Hadoop Operations at Scale
AWS BigData Blog
Hadoop360
How to monitor Hadoop metrics
Presentations
Hadoop Summit Presentations - Slide decks from Hadoop Summit
Hadoop 24/7
An example Apache Hadoop Yarn upgrade
Apache Hadoop In Theory And Practice
Hadoop Operations at LinkedIn
Hadoop Performance at LinkedIn
Docker based Hadoop provisioning
Books
Hadoop: The Definitive Guide
Hadoop Operations
Apache Hadoop Yarn
HBase: The Definitive Guide
Programming Pig
Programming Hive
Hadoop in Practice, Second Edition
Hadoop in Action, Second Edition
Hadoop and Big Data Events
ApacheCon
Strata + Hadoop World
Hadoop Summit
Other Awesome Lists
Other amazingly awesome lists can be found in the awesome-awesomeness and awesome list.

点击【阅读原文】进入GitHub
本文分享自微信公众号 - 曲水流觞TechRill(TechRill)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

- Hadoop 生态组件初探系列之——HDFS
- 啃掉Hadoop系列笔记(01)-Hadoop框架的大数据生态
- Hadoop/spark安装实战(系列篇1)准备安装包
- 敏捷开发生态系统系列之一:序言及需求管理生态(客户价值导向-可工作软件-响应变化)
- 大数据-Hadoop生态(8)-HDFS的读写数据流程以及机架感知
- Vertica系列:Vertica和Hadoop的互操作性
- Hadoop入门系列(2) -- Hadoop运行环境搭建
- RHadoop实践系列文章
- Hadoop连载系列之四:数据收集分析系统Chukwa 推荐
- hadoop系列:zookeeper(1)——zookeeper单点和集群安装
- hadoop系列文档5-对官方MapReduce 过程的翻译(一)
- Hadoop系列之一:大数据存储及处理平台产生的背景
- Hadoop运维记录系列(十七)
- 学习Hadoop不错的系列文章(转)
- 大数据技术hadoop入门理论系列之二—HDFS架构简介
- 2-1.HDFS原理(Hadoop系列day02)
- (三)hadoop系列之__CRT(SecureCRTPortable)的使用
- 分布式流水作业系统项目经理挂掉的处理办法(Hadoop模拟思考系列)
- Hadoop集群系列教程之我眼中的Hadoop(一)
- Hadoop系列之Aggregate用法