使用python进行爬虫下载网易云音乐
2017-03-31 16:04
453 查看
使用python进行爬虫(其实我最想知道的是怎么知道这个api地址的)
效果:
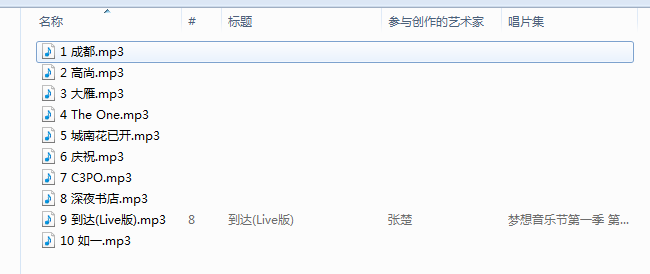
# -*- coding:utf-8 -*-
# Python 2.7
import urllib2
import urllib
import json
mv_id='4395559' #网易云音乐地址后面的id
url = "http://music.163.com/api/playlist/detail?id="+mv_id #对应网易云音乐地址 :http://music.163.com/#/discover/toplist?id=4395559
timeout=30 #设置超时时间
headers={
'User-Agent' : 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
req = urllib2.Request(url,None,headers) #添加请求报文头
res = urllib2.urlopen(req,None,timeout) #执行请求
html = res.read() #接收到的数据为str => str转json :json.loads(str)
musicList = json.loads(html)['result']['tracks'] #将str转json进行获取详细数据
for i in range(10): #循环遍历的数量 10 条数据
name = str(i+1)+' '+musicList[i]['name']+'.mp3'
link = musicList[i]['mp3Url'] #音乐下载地址
urllib.urlretrieve(link,'aaa\\'+name) # aaa\\为根目录下面的地址,需要自己建立
print (name+' success!')
print musicList效果:

相关文章推荐
- 使用python进行爬虫下载指定网站的图片
- 使用简易Python爬虫下载百度贴吧图片
- karloop介绍--hello world大家好,今天为大家介绍一款非常轻量级的的web开发框架,karloop框架。使用python开发 首先我们下载karloop源码进行安装。 源码地址 下载成
- Python使用BeautifulSoup进行爬虫
- Python---对html文件内容进行搜索取出特定URL地址字符串,保存成列表,并使用每个url下载图片,并保存到硬盘上,使用bs4,beautifulsoup模块
- Win10下python3和python2同时安装并解决pip共存问题 特别说明,本文是在Windows64位系统下进行的,32位系统请下载相应版本的安装包,安装方法类似。 使用python开
- 使用Python编写简单网络爬虫抓取视频下载资源
- 在macOS上使用Python+MySQL连接Tushare,进行股票数据下载
- python使用网易云音乐 api下载mv
- 使用python爬虫爬取迅雷侠下载,呵呵,你懂得
- 使用Python编写简单网络爬虫抓取视频下载资源
- 使用python进行下载地址转换
- 讲解Python的Scrapy爬虫框架使用代理进行采集的方法
- 使用Python编写简单网络爬虫抓取视频下载资源
- 解决Python爬虫在爬资源过程中使用urlretrieve函数下载文件不完全且避免下载时长过长陷入死循环,并在下载文件的过程中显示下载进度
- 使用Python实现下载网易云音乐的高清MV
- 【用Python写爬虫】获取html的方法【四】:使用urllib下载文件
- 使用python进行爬虫学习(一)
- python网络爬虫之使用scrapy下载文件
- Python3网络爬虫:Scrapy入门之使用ImagesPipline下载图片