右值引用与移动构造函数的一点理解
2017-03-30 20:23
148 查看
说明:右值引用是c++11中的新特性,本来c++中是有一个左值引用的,引入右值引用后,多了很多概念,再看prime的时候,就觉得似乎让c++更繁琐了。偶然在知乎上看到这个话题,于是有了一点理解,遂记录于此。知乎链接
大象与冰箱
我们还是从大象与冰箱的故事说起。大象装入冰箱是一个很麻烦的过程,因为大象很大,假设可以装入冰箱。那么如何把大象装入另外一个冰箱。c++有2种方案:
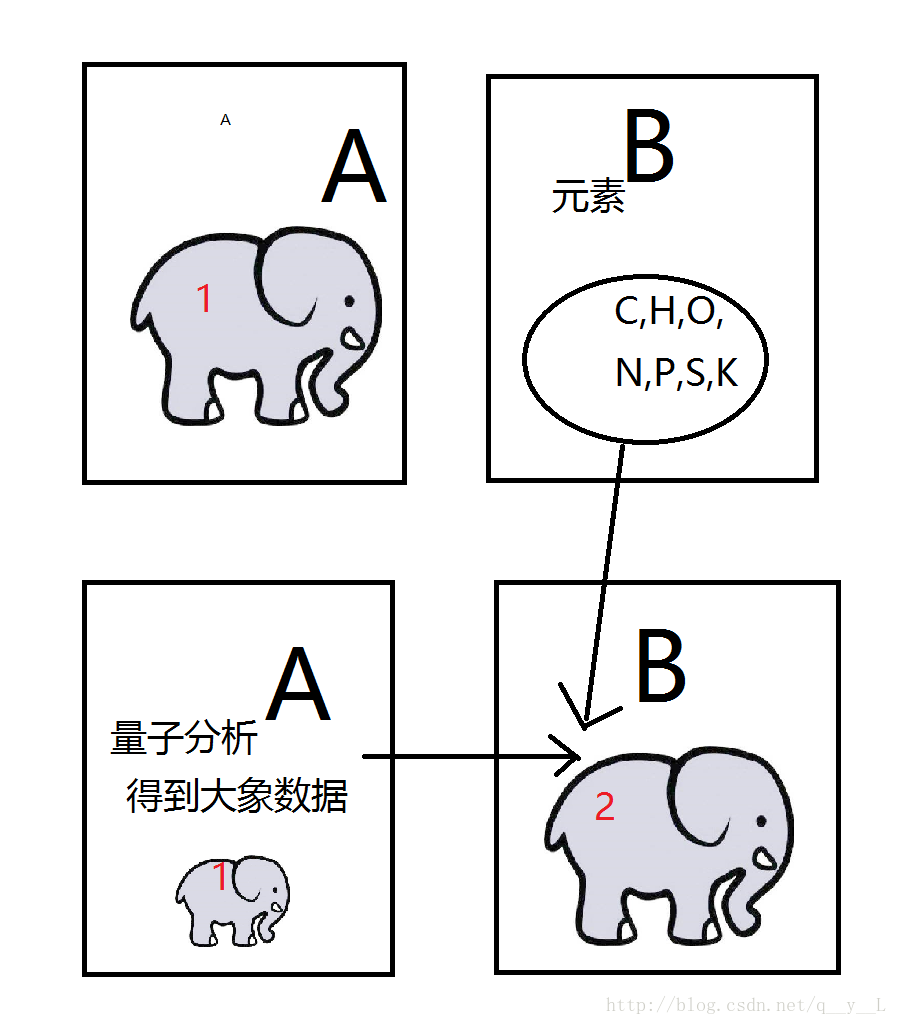
我们先利用量子技术分析冰箱A中大象的构造信息,然后在冰箱B利用量子技术利用碳,氢,氧、氮、……等元素合称,如果你愿意还可以利用量子技术将冰箱A中的大象瞬间湮灭。
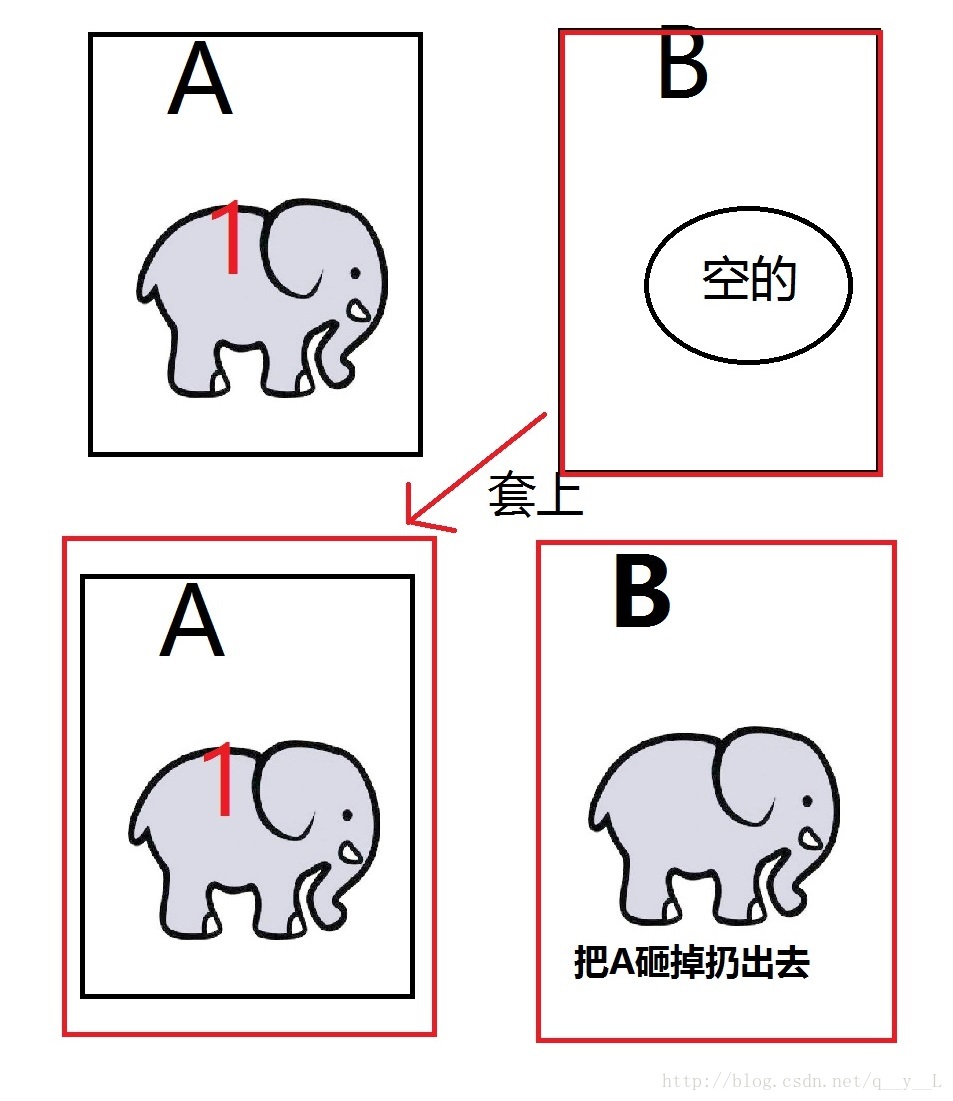
我们直接把冰箱A砸掉,然后再原地套上一个冰箱B(假设冰箱可以拼装),显然冰箱A不存在了。
上图:
方案一
方案二:
代码角度分析
先看一段代码:我们定义一个int形数组类vector,数据成员包括数组的长度size,以及数组的首地址pdata,还有一些相关的函数。
#include<iostream>
#include<cstring>
using namespace std;
//类的定义
class vector
{
public:
vector() :size(0), pdata(nullptr) {}//默认构造函数
vector(size_t len, int value) : size(len)//带参数的构造函数
{
pdata = new int[len];
memset(pdata, value, sizeof(int)*len);
}
vector(const vector&);//拷贝构造函数
vector(vector&& v);//移动构造函数
void print()//打印数组
{
for (size_t i = 0; i < size; i++)
cout << *(pdata + i) << " ";
}
~vector()//析构函数
{
cout << "deconstruction function called!" << endl;
}
private:
size_t size; //数组长度
int *pdata; //首地址
};
vector::vector(const vector& v)
{
size = v.size;
delete[] pdata;
pdata = new int[size];
memcpy(pdata, v.pdata, sizeof(int)*size);
cout << "copy construct fuction called!" << endl;
}
vector::vector(vector&& v) :size(v.size), pdata(v.pdata)
{
v.pdata = nullptr;
v.size = 0;
cout << "Move construct function called!" << endl;
}
int main()
{
vector v1(500000, 0);
//v1.print();
vector v2(v1);
//v1.print();
//v2.print();
return 0;
}代码很简单,一个类,主要看移动构造函数和拷贝构造函数,为了体现区别,我们特意在构造的时候申请500000个的大小。
运行上面的代码,会调用拷贝构造函数,虽然我们也编写了移动构造函数,但是,处于函数匹配的原则,
v2(v1)中的参数v1是左值,所以会采用拷贝构造函数,拷贝构造函数调用后,原对象v1依然存在。
为了调用移动构造函数,我们需要传递一个与原型匹配的右值参数,而标准库中提供了一个左值转右值的函数
std::move(),所以我们将刚才的语句重写为:
vector v2(move(v1));
那么就会调用移动构造函数。
好处是什么呢?
我们可以回想之前大象装冰箱的例子,方案一就是对于拷贝构造函数,我们进行深拷贝,获得的是大象的构造信息,然后自己造一个大象,这个过程有时候会很麻烦,因为实际使用中,我们需要拷贝的也许不是一头大象,而是整个动物园。然而在C++11以前,基本上都是这么干的。小孩子都知道,需要一个玩具车,不是先去分析玩具车,然后造出来,而是直接把喜欢的那个买回来,也就是商店的那个玩具车直接变到我家里来。同样,移动构造函数也是类似,假如我不需要原来的数据保存,我只需要这个数据,为什么一定要构造一个副本,而不是直接拿过来呢?这样岂不是会省事很多?也就是说,移动构造函数是反客为主,直接掌管原数据的所有权,并将原来的拥有者销毁掉。这样避免数据的复制,所以效率会提高。
分两次运行上面的代码,我们利用vs自带的性能分析工具来分析一下:
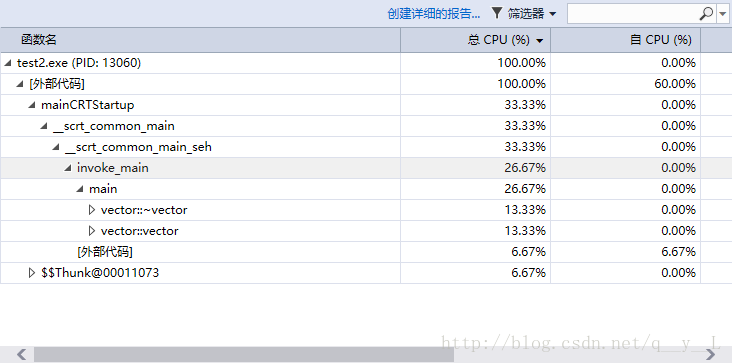
首先是拷贝构造函数:
然后是移动构造函数:
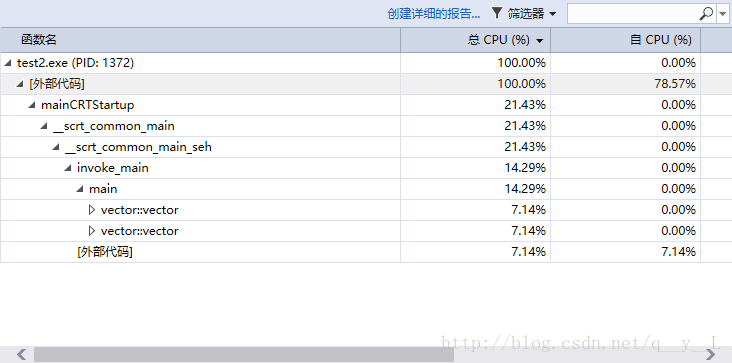
我们只需要关注main下面的数据,对比分析发现在拷贝构造函数中,主要是拷贝构造函数和析构函数,因为是深拷贝,所以需要释放v1,v2所包含的内存空间,而且在调用拷贝构造函数时也需要开辟一块较大的内存空间。而在移动构造函数版本中,主要是构造函数和移动构造函数操作,外部代码所占比例相对于拷贝构造函数来说有所上升,说明移动构造函数较为高效,所需cpu资源较少。
关于性能分析,可能解释不一定准确。若有错误,欢迎指出。

相关文章推荐
- 新概念“右值引用”和 ”移动构造函数”是怎么回事?
- C++ 学习笔记(13)拷贝构造函数、拷贝赋值运算符、移动构造函数、移动赋值运算符、析构函数、右值引用、引用限定符
- C++11学习笔记2---右值引用与移动构造函数
- C++新特性 右值引用 移动构造函数
- 看完这个你还不理解右值引用和移动构造 你就可以来咬我(上)
- C++11新特性,对象移动,右值引用,移动构造函数
- 看完这个你还不理解右值引用和移动构造 你就可以来咬我(下)
- 看完这个你还不理解右值引用和移动构造 你就可以来咬我(中)
- 右值引用与移动构造函数、移动赋值
- C++11新特性之0——移动语义、移动构造函数和右值引用
- 构造函数中泄漏this netbeans 一点理解
- c/s模式在移动便携系统应用的一点理解
- C++ 0x 之左值与右值、右值引用、移动语义、传导模板(转载)
- C++ 0x 之左值与右值、右值引用、移动语义、传导模板
- C++ 11右值引用的理解
- c++ 11学习笔记--右值引用和移动构造语义
- C++11线程指南(4)--右值引用与移动语义
- C++11新特性:右值引用和转移构造函数
- [C++] 右值引用:移动语义与完美转发(C++是一种扼杀生命的语言)
- C++的杂七杂八:我家的返回值才不可能这么傲娇(右值引用和移动语义)