k最近邻算法(K-Nearest Neighbor)理解与python实现
2017-03-30 17:42
405 查看
numpy 模块参考教程:http://old.sebug.net/paper/books/scipydoc/index.html
一:什么是KNN算法?
kNN算法全称是k-最近邻算法(K-Nearest Neighbor)
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下边举例说明:
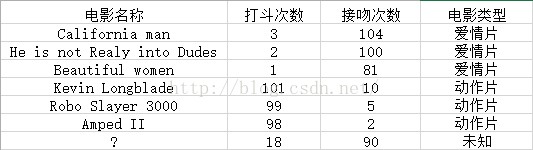
即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来,如下图

现在我们得到了样本集中与未知电影的距离,按照距离的递增顺序,可以找到k个距离最近的电影,假定k=3,则三个最靠近的电影是和he is not realy into Dudes,Beautiful women, California man kNN算法按照距离最近的三部电影类型决定未知电影类型,这三部都是爱情片,所以未知电影的类型也为爱情片
二:KNN算法的一般流程
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6---统计K-最近邻样本中每个类标号出现的次数
step.7---选择出现频率最大的类标号作为未知样本的类标号
三、KNN算法的Python代码实现
使用方法:进入kNN.py文件所在的目录,输入Python,依次输入
import kNN
group,labels = kNN.createDataSet()
kNN.classify0([0,0],group,lables,3)
在实际使用中,有几个问题是值得注意的:
1、K值的选取,选多大合适呢?
2、计算两者间距离,用哪种距离会更好呢(欧几里得距离等等几个)?
3、计算量太大怎么办?
4、假设样本中,类型分布非常不均,比如动作片电影有200部,但是爱情片电影只有20部,这样计算起来,即使不是动作片电影,也会因为动作片样本太多,导致k个最近邻居里有不少动作片电影,这样该怎么办呢?
没有万能的算法模型,只有最优的算法,要懂得合适利用算法。
一:什么是KNN算法?
kNN算法全称是k-最近邻算法(K-Nearest Neighbor)
kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下边举例说明:
即使不知道未知电影属于哪种类型,我们也可以通过某种方法计算出来,如下图
现在我们得到了样本集中与未知电影的距离,按照距离的递增顺序,可以找到k个距离最近的电影,假定k=3,则三个最靠近的电影是和he is not realy into Dudes,Beautiful women, California man kNN算法按照距离最近的三部电影类型决定未知电影类型,这三部都是爱情片,所以未知电影的类型也为爱情片
二:KNN算法的一般流程
step.1---初始化距离为最大值
step.2---计算未知样本和每个训练样本的距离
step.3---得到目前K个最临近样本中的最大距离maxdist
step.4---如果dist小于maxdist,则将该训练样本作为K-最近邻样本
step.5---重复步骤2、3、4,直到未知样本和所有训练样本的距离都算完
step.6---统计K-最近邻样本中每个类标号出现的次数
step.7---选择出现频率最大的类标号作为未知样本的类标号
三、KNN算法的Python代码实现
#encoding:utf-8
from numpy import *
import operator
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
def classify0(inX,dataSet,labels,k):
#返回“数组”的行数,如果shape[1]返回的则是数组的列数
dataSetSize = dataSet.shape[0]
#两个“数组”相减,得到新的数组
diffMat = tile(inX,(dataSetSize,1))- dataSet
#求平方
sqDiffMat = diffMat **2
#求和,返回的是一维数组
sqDistances = sqDiffMat.sum(axis=1)
#开方,即测试点到其余各个点的距离
distances = sqDistances **0.5
#排序,返回值是原数组从小到大排序的下标值
sortedDistIndicies = distances.argsort()
#定义一个空的字典
classCount = {}
for i in range(k):
#返回距离最近的k个点所对应的标签值
voteIlabel = labels[sortedDistIndicies[i]]
#存放到字典中
classCount[voteIlabel] = classCount.get(voteIlabel,0)+1
#排序 classCount.iteritems() 输出键值对 key代表排序的关键字 True代表降序
sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)
#返回距离最小的点对应的标签
return sortedClassCount[0][0]使用方法:进入kNN.py文件所在的目录,输入Python,依次输入
import kNN
group,labels = kNN.createDataSet()
kNN.classify0([0,0],group,lables,3)
在实际使用中,有几个问题是值得注意的:
1、K值的选取,选多大合适呢?
2、计算两者间距离,用哪种距离会更好呢(欧几里得距离等等几个)?
3、计算量太大怎么办?
4、假设样本中,类型分布非常不均,比如动作片电影有200部,但是爱情片电影只有20部,这样计算起来,即使不是动作片电影,也会因为动作片样本太多,导致k个最近邻居里有不少动作片电影,这样该怎么办呢?
没有万能的算法模型,只有最优的算法,要懂得合适利用算法。

相关文章推荐
- Python实现的最近最少使用算法
- K最近邻算法及其Python实现
- Python实现的最近最少使用算法
- 【算法分析】如何理解快慢指针?判断linked list中是否有环、找到环的起始节点位置。以Leetcode 141. Linked List Cycle, 142. Linked List Cycle II 为例Python实现
- 机器学习——k最近邻算法(K-Nearest Neighbor,Python实现)
- python实现K最近邻算法
- KNN (K最近邻接算法)python 语言下的简单实现
- 机器学习与数据挖掘-K最近邻(KNN)算法的实现(java和python版)
- KNN 算法的python实现 迭代训练方式,将最近的测试样例作为训练样例扩大训练集
- 机器学习实战_kNN算法python3.6实现与理解
- python机器学习案例教程――K最近邻算法的实现
- python实现的最近最少使用算法
- Python徒手实现识别手写数字—图像识别算法(K最近邻)
- 理解Logistic回归算法原理与Python实现
- k最近邻算法(KNN)的简介和python实现
- 数据挖掘10大算法(6)-K最近邻(KNN)算法的实现(java和python版)
- K最近邻结点算法(k-Nearest Neighbor algorithm)KNN——python简单实现
- 机器学习-简单的K最近邻算法及python实现
- 求婚拒绝算法(GS算法)的Python实现
- TEA 算法的 Python 实现