Python与人工神经网络(8)——改进神经网络
2017-03-29 13:14
197 查看
花了三期的篇幅来改进我们的神经网络:第五期讨论了二次方程成本函数引起的训练变慢的问题,引入了交叉熵成本函数;第六期提到了过度拟合及其解决办法——正则化,并详细论述了L2正则化的原理;第七期主要概括的讲了其他的三种正则化方法,还有一些数据和初始权重设定的技巧。现在是时候改进神经网络的代码了。
但是在微信公众号贴代码和贴公式都是一个很蛋疼的事情,所以我不会在下面贴大段的代码。完整的代码在:https://git.oschina.net/zxhm/Neural-NetWork-and-Deep-Learning,其中src文件夹下的network2.py就是改进之后的代码,请关注这个系列文章的同学们自己去瞄瞄。下面我就对改进的地方做一个简单的说明,具体的还是得看代码。
这一次没有直接修改network.py的代码,而是新建了一个network2.py。第一个需要说明是初始化权重的方法,代码中有个default_weight_initializer()方法,实现了我们在第七期里说的1/√n的权重正态分布。当然代码里面也保留了原始的权重初始化方法,封装在default_weight_initializer()方法中。
第二个需要说明的地方是在代码中多了两个类,一个叫CrossEntropyCost,另一个叫QuadraticCost,很明显第一个是使用了交叉熵成本函数,第二个是使用了二次方程成本函数。这两个类里面都有两个静态方法,fn方法就是实现了成本函数,delta方法实现了第四期中提到的δ值的计算。另外在CrossEntropyCost的fn方法中,调用了一个numpy.nan_to_num的东西,是为了保证当得到的值非常接近于0时,Numpy能过正确处理。
第三点就是因为有交叉熵成本函数的引入和权重初始化的不同,类Network的构造函数会变化,不管是参数还是内容。
第四点是作者为了检测我们的神经网络的运行情况,对训练数据和验证数据的识别率和成本函数值都有监测,是否监测这些值的参数默认值都是false,可以在SGD方法中设置。
第五点是注意引入了L2正则化参数λ,注意一下他在代码里面作用的地方。
就这么多了,其他的都跟上一个版本的代码差不多。运行的时候,神经网络大小依然是[784,30,10],训练周期为30,随机梯度时每次随机选取十个进行计算,学习速率参数η值为0.5,正则化参数λ值为5.0,就可以开始训练了。
话说,有没有人想过这些参数是怎么来的。其实我猜作者写到这部分的时候也应该很蛋疼,因为他说是试出来的,目前这个领域的研究并没有特别好的成果,多半靠经验和试验,作者就此传授了一些经验给我们:
学习速率参数η:
所以学习速率,就是在随机梯度下降算法中下降的快慢,我们来看一个示例图:
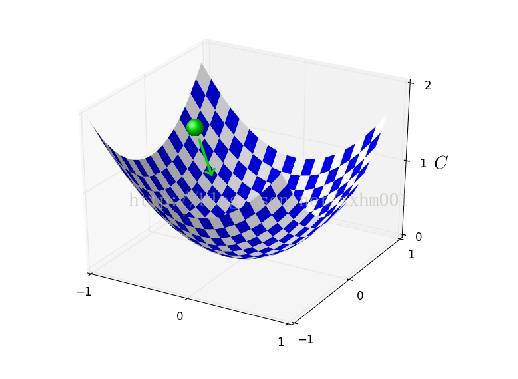
假设这个曲面就是成本函数,我们就在这个曲面内需要随机梯度下降,如果步子很小,那会非常稳妥,C会一直下降,直到最低点附近,但是代价就是训练速度很慢。如果步子太大,很容易一步就从这边越过了谷底,跨到了对面。所以在试的过程中,可以采取每次减少多少倍的方式,比如第一次是5,第二次是0.5,监测成本函数变化,如果训练的前几个周期稳步减小,那就差不多了,然后进行微调。
不过这么看,应该是前面的周期用大一点的η值,后面的周期用小一点的η值比较靠谱,在以后的章节我们会提到。
训练周期:
训练周期我之前在说过度拟合的时候有提到过,就是得监测识别率,如果开始停滞不前,就可以停了。不过这里一般不会一旦识别率不上升了就停止训练,会先观察个多少周期,比如10或者15,最后的训练周期原始加上这个观察期的。
正则化参数:
首先采用没有正则化的神经网络确定出η值,然后再来试λ值。针对这个问题,作者给的建议是从1开始,然后选取十倍的速率,增大或者减小,到差不多之后微调。
随机抽取计算梯度的个数:
这里可能需要补课,因为之前我没提到,就是为什么要随机抽取n个去算梯度,而不是一个个,一步一个脚印的算呢?因为Numpy矩阵求和贼快,而用循环算n次贼慢呀。所以这个参数跟η一样,选小了,训练就会比较慢,而选大了,可能训练一个周期才更新个三五次w值和b值,反馈不够明显。所以这方面的权衡,还是得自己去比较。作者在书里面说,他选个10,就是瞎选的( ╯□╰ )。
最后的最后,在确定这些参数的时候,一定不要用全部的数据试,用少量的就可以了,提高试验的速度。第二是一硬要用验证数据集,不要使用测试数据集,这个原因在讲过度拟合的那期说过,就不赘述了。
欢迎关注我的微信公众号获取最新文章:

但是在微信公众号贴代码和贴公式都是一个很蛋疼的事情,所以我不会在下面贴大段的代码。完整的代码在:https://git.oschina.net/zxhm/Neural-NetWork-and-Deep-Learning,其中src文件夹下的network2.py就是改进之后的代码,请关注这个系列文章的同学们自己去瞄瞄。下面我就对改进的地方做一个简单的说明,具体的还是得看代码。
这一次没有直接修改network.py的代码,而是新建了一个network2.py。第一个需要说明是初始化权重的方法,代码中有个default_weight_initializer()方法,实现了我们在第七期里说的1/√n的权重正态分布。当然代码里面也保留了原始的权重初始化方法,封装在default_weight_initializer()方法中。
第二个需要说明的地方是在代码中多了两个类,一个叫CrossEntropyCost,另一个叫QuadraticCost,很明显第一个是使用了交叉熵成本函数,第二个是使用了二次方程成本函数。这两个类里面都有两个静态方法,fn方法就是实现了成本函数,delta方法实现了第四期中提到的δ值的计算。另外在CrossEntropyCost的fn方法中,调用了一个numpy.nan_to_num的东西,是为了保证当得到的值非常接近于0时,Numpy能过正确处理。
第三点就是因为有交叉熵成本函数的引入和权重初始化的不同,类Network的构造函数会变化,不管是参数还是内容。
第四点是作者为了检测我们的神经网络的运行情况,对训练数据和验证数据的识别率和成本函数值都有监测,是否监测这些值的参数默认值都是false,可以在SGD方法中设置。
第五点是注意引入了L2正则化参数λ,注意一下他在代码里面作用的地方。
就这么多了,其他的都跟上一个版本的代码差不多。运行的时候,神经网络大小依然是[784,30,10],训练周期为30,随机梯度时每次随机选取十个进行计算,学习速率参数η值为0.5,正则化参数λ值为5.0,就可以开始训练了。
话说,有没有人想过这些参数是怎么来的。其实我猜作者写到这部分的时候也应该很蛋疼,因为他说是试出来的,目前这个领域的研究并没有特别好的成果,多半靠经验和试验,作者就此传授了一些经验给我们:
学习速率参数η:
所以学习速率,就是在随机梯度下降算法中下降的快慢,我们来看一个示例图:
假设这个曲面就是成本函数,我们就在这个曲面内需要随机梯度下降,如果步子很小,那会非常稳妥,C会一直下降,直到最低点附近,但是代价就是训练速度很慢。如果步子太大,很容易一步就从这边越过了谷底,跨到了对面。所以在试的过程中,可以采取每次减少多少倍的方式,比如第一次是5,第二次是0.5,监测成本函数变化,如果训练的前几个周期稳步减小,那就差不多了,然后进行微调。
不过这么看,应该是前面的周期用大一点的η值,后面的周期用小一点的η值比较靠谱,在以后的章节我们会提到。
训练周期:
训练周期我之前在说过度拟合的时候有提到过,就是得监测识别率,如果开始停滞不前,就可以停了。不过这里一般不会一旦识别率不上升了就停止训练,会先观察个多少周期,比如10或者15,最后的训练周期原始加上这个观察期的。
正则化参数:
首先采用没有正则化的神经网络确定出η值,然后再来试λ值。针对这个问题,作者给的建议是从1开始,然后选取十倍的速率,增大或者减小,到差不多之后微调。
随机抽取计算梯度的个数:
这里可能需要补课,因为之前我没提到,就是为什么要随机抽取n个去算梯度,而不是一个个,一步一个脚印的算呢?因为Numpy矩阵求和贼快,而用循环算n次贼慢呀。所以这个参数跟η一样,选小了,训练就会比较慢,而选大了,可能训练一个周期才更新个三五次w值和b值,反馈不够明显。所以这方面的权衡,还是得自己去比较。作者在书里面说,他选个10,就是瞎选的( ╯□╰ )。
最后的最后,在确定这些参数的时候,一定不要用全部的数据试,用少量的就可以了,提高试验的速度。第二是一硬要用验证数据集,不要使用测试数据集,这个原因在讲过度拟合的那期说过,就不赘述了。
欢迎关注我的微信公众号获取最新文章:

相关文章推荐
- Python与人工神经网络(10)——神经网络可以干什么
- Python与人工神经网络(2)——使用神经网络识别手写图像
- Python与人工神经网络:使用神经网络识别手写图像介绍
- Python实现单隐层神经网络
- 可变多隐层神经网络的python实现
- 神经网络python 实现
- 感知机学习python 神经网络设计教材P43
- python机器学习之神经网络(一)
- 十一行Python代码实现一个神经网络(第一部分)
- Python代码实现模拟退火算法Boltzman机神经网络权重调节
- Deep Learning 学习笔记(二):神经网络Python实现
- Python图像处理(14):神经网络分类器
- 人工神经网络入门(1) —— 单层人工神经网络应用示例
- python实现单隐层神经网络基本模型 推荐
- python keras (一个超好用的神经网络框架)的使用以及实例
- 径向基(RBF)神经网络python实现
- Python ——pyneurgen 神经网络代码
- 人工神经网络工具NeuroSolutions使用教程:NeuralExpert构建神经网络
- 关于神经网络算法的 Python例程
- Python实战之神经网络(1)