python_scrapy爬虫_jieba分词_数据可视化 阶段总结报告
2017-03-29 10:05
771 查看
第一次写于 20170328 23:36 寝室
python scrapy爬虫 搜狗微信 jieba分词 数据可视化 wordcloud_plotly
学习过程中参考过的文章或网站链接:
- Python 基础教程 -菜鸟教程
有哪些比较好的中文分词方案? -知乎
jieba分词 -github
10行Python代码的词云 -知乎
Python中除了matplotlib外还有哪些数据可视化的库? -知乎
https://plot.ly/python/
http://weixin.sogou.com/
我完成的完整工程文件:
python_weixin -https://github.com/RenjiaLu9527/python_weixin/
获取数据:使用python scrapy框架定制爬虫,爬取网站数据 并存入Mysql数据库
处理数据:使用python jieba分词模块,处理Mysql数据库中储存的微信文本并存入Mysql
数据可视化:使用plotly 和 wordcloud 将分词数据可视化
写总结
第一步中:scrapy资料比较多,勉强能做个能用的爬虫,代码模块化目前写的很乱,由于前个星期写的这个python文件,当时遇到的问题没有记录,在此就不多说;
部分代码 weixin_TextSpider类
爬虫运行了十几次,每次爬一遍‘搜狗微信 http://weixin.sogou.com/’,只能得到5k左右的文章,而且每隔两小时文章更新数量只有几百篇;所以我在三天的时间里共运行十几次,获取文章 89990篇文章;去重后剩下15667篇
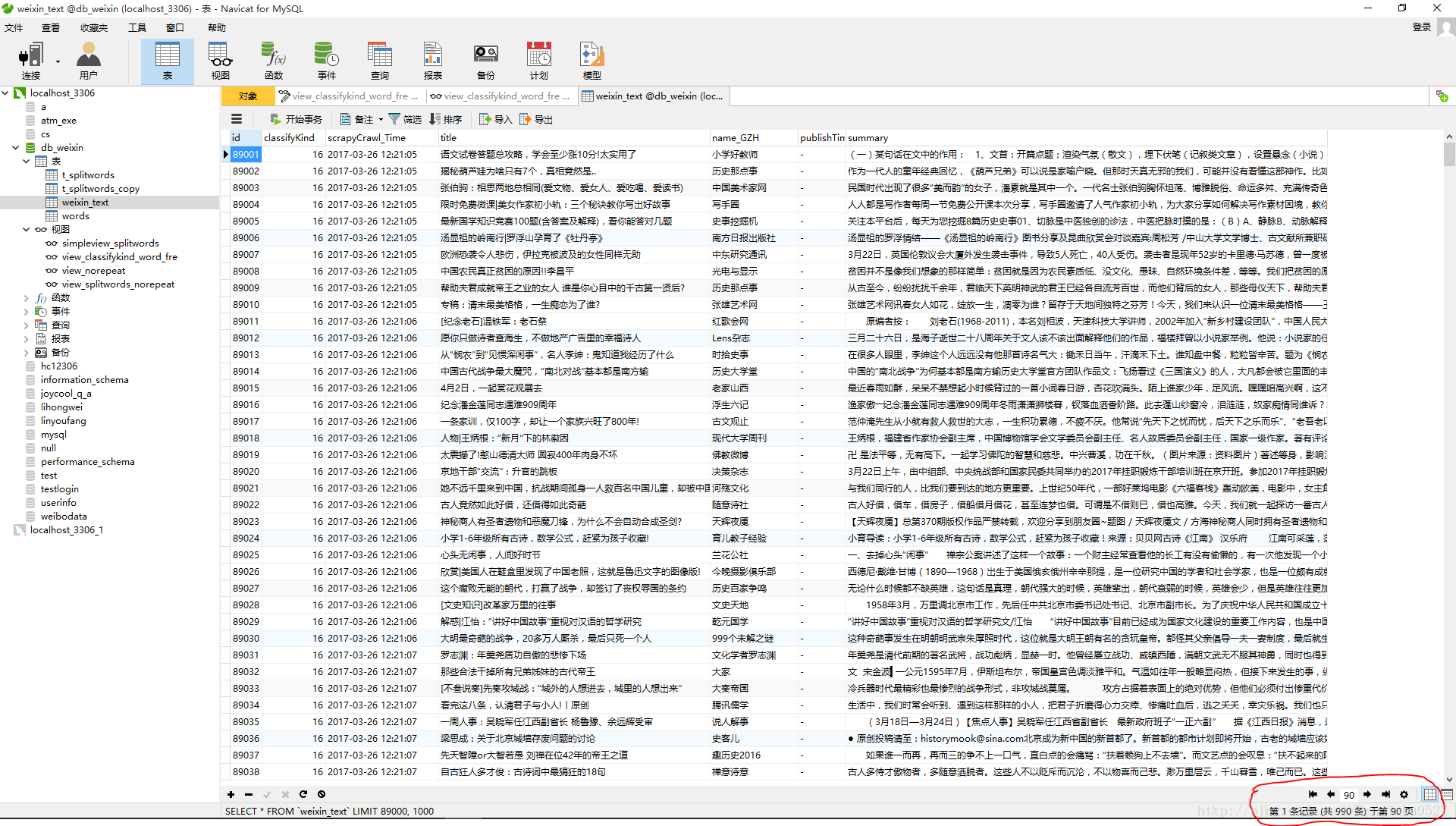
基于这15k篇原始数据开始分析;
数据库建表如下:

四个视图:

第一个视图弃用;
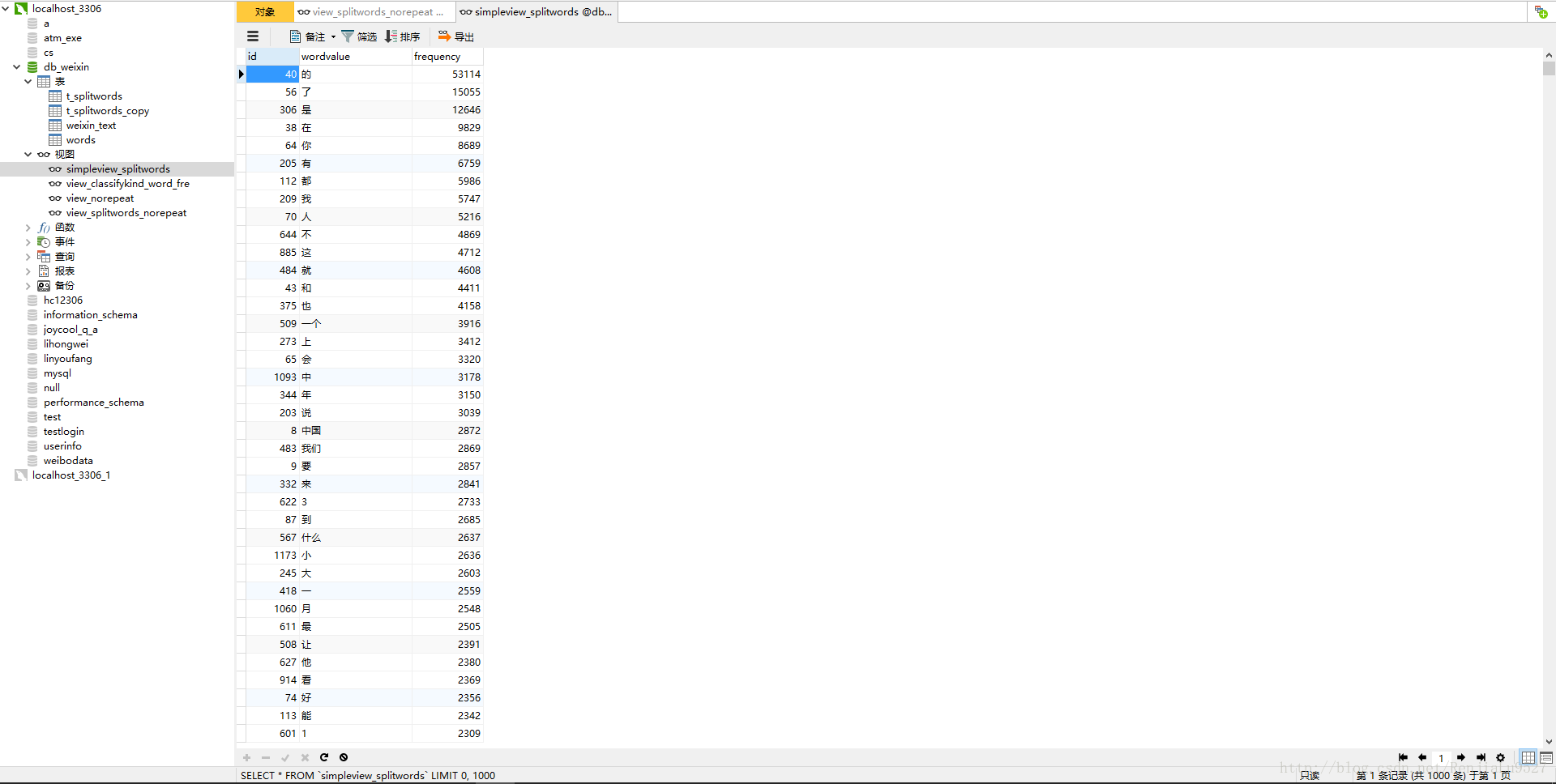
第二个视图:从 t_splitwords,和 weixin_text 两个表中按weixinText分类板块分组,并按frequency大小排序;可以查看每个分类板块 最多重复出现的词
第三个视图:weixin_Text 去重后的视图,去重条件如下:weixin_text.classifyKind, weixin_text.title, weixin_text.name_GZH, weixin_text.summary 根据这四个字段选出 不重复独一无二的 weixinText
第四个视图:表 t_splitwords(100w 条数据) 去重 并统计重复次数 以t_splitwords.value, t_splitwords.titleOrSummary, t_splitwords.partOfSpeech三个字段分组
其中 t_splitwords表数据量达到 100w ,一条简单的查询语句要运行几十秒,第一次接触这个量级,不得不开始注意数据库的查询优化
第二步调用jieba分词分析并存入mysql数据库
中文分词知乎的讨论:https://www.zhihu.com/question/19578687
我选用jieba分词
例子
输出
部分代码:utils_parseString.py 解析从mysql获取的微信文本并再次存入mysql
部分代码:utils_mysql.py 连接数据库工具函数集合
使用很简单,我先全模式分词再对其做词性分析,这里有重复分词的问题,这也是数据量这么大的原因,重复次数最多的都是单字,所以后面的可视化操作我略去了单字词条,只分析两个字符及以上的词
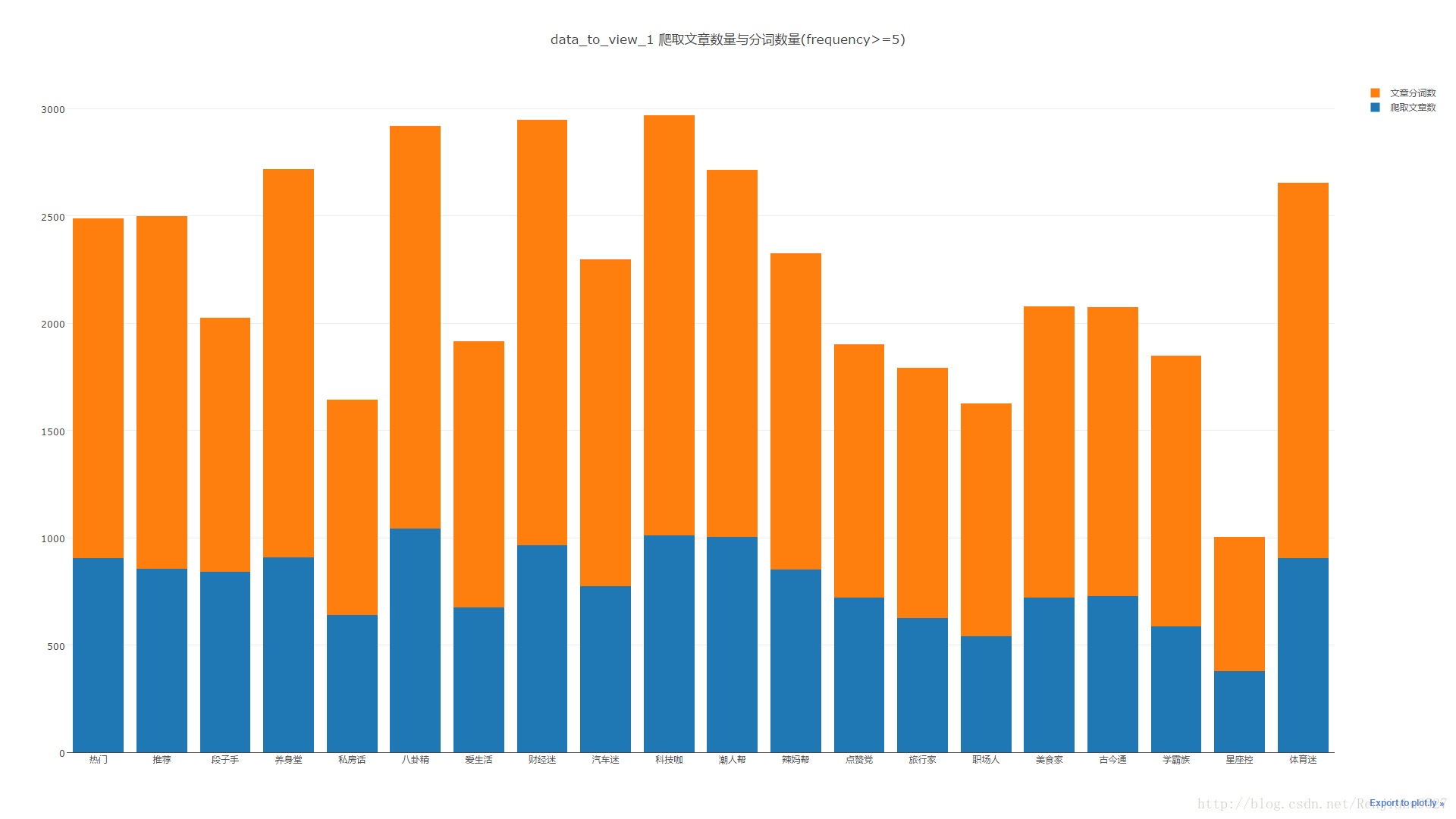
第三步: 数据可视化,
plotly数据可视化效果真不错,虽然看了官网也没有找到详细的属性介绍,目前只使用了其中bar类图
生成:https://plot.ly/~RenjiaLu/2/
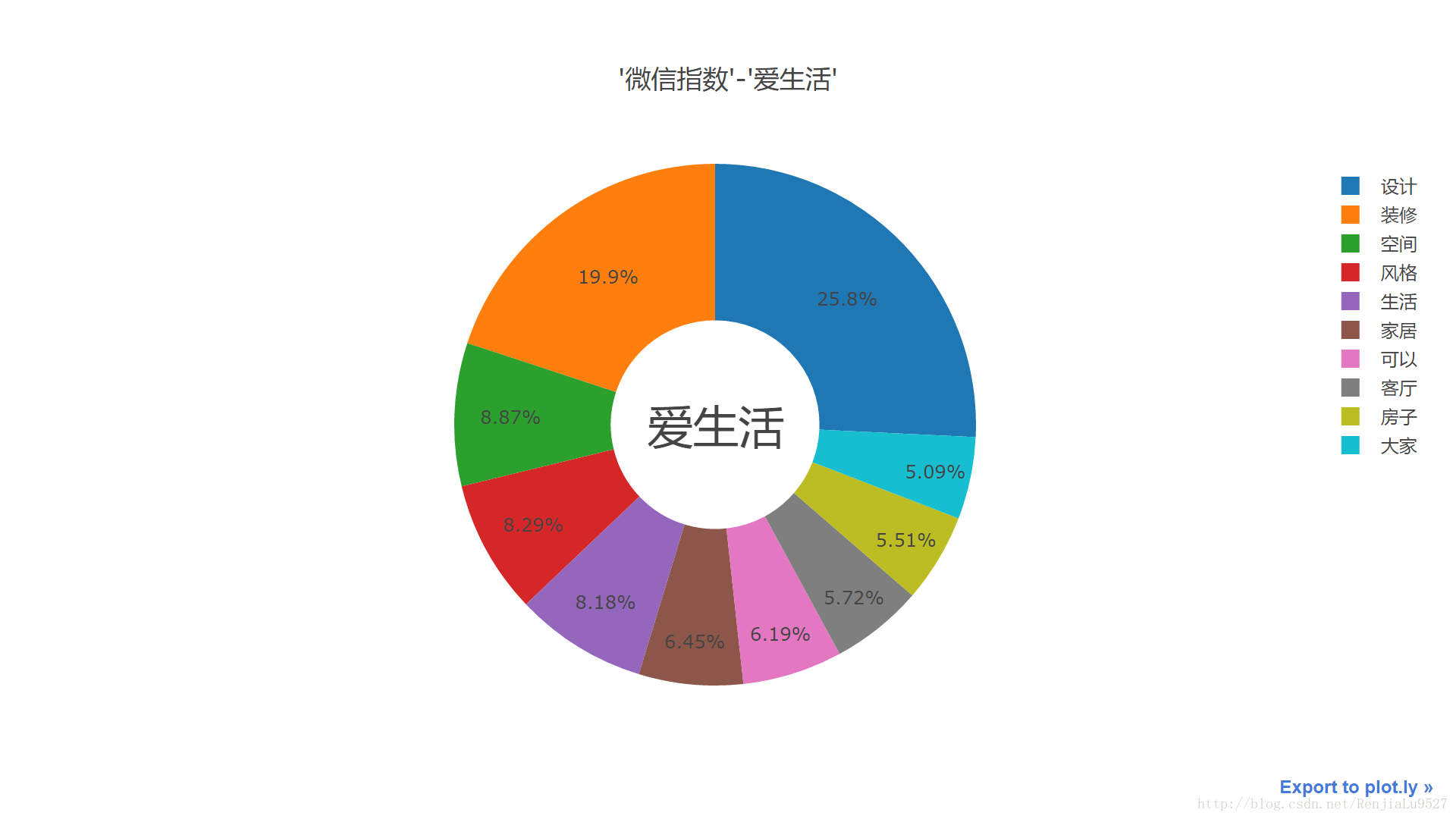
然后抽取这二十个分类板块中频度前十的词分析
这里取其中的三个分类,如图


代码已上传 github,见文章开头
词云 wordcloud 模块 genWordCloud.py
这里遇到的词云中文乱码的问题,我记录到了另一篇文章中http://blog.csdn.net/renjialu9527/article/details/65937731
贴上生成的词云


效果还可以
爬虫找数据-mysql建表建视图优化存取数据-python分析数据可视化操作
20170329 11:39
end
序言
关键词:python scrapy爬虫 搜狗微信 jieba分词 数据可视化 wordcloud_plotly
学习过程中参考过的文章或网站链接:
- Python 基础教程 -菜鸟教程
有哪些比较好的中文分词方案? -知乎
jieba分词 -github
10行Python代码的词云 -知乎
Python中除了matplotlib外还有哪些数据可视化的库? -知乎
https://plot.ly/python/
http://weixin.sogou.com/
我完成的完整工程文件:
python_weixin -https://github.com/RenjiaLu9527/python_weixin/
正文
这段时间学习的内容就是python爬虫、分词、以及数据可视化;以爬取‘搜狗微信’中的微信热门文章为例分析;这个小工程我将其分成三个部分:获取数据:使用python scrapy框架定制爬虫,爬取网站数据 并存入Mysql数据库
处理数据:使用python jieba分词模块,处理Mysql数据库中储存的微信文本并存入Mysql
数据可视化:使用plotly 和 wordcloud 将分词数据可视化
写总结
第一步中:scrapy资料比较多,勉强能做个能用的爬虫,代码模块化目前写的很乱,由于前个星期写的这个python文件,当时遇到的问题没有记录,在此就不多说;
部分代码 weixin_TextSpider类
# -*- coding: utf-8 -*-
# @Time : 2017/03/21 10:54
# @Author : RenjiaLu
import time
import scrapy
from scrapy import Request
from scrapy.spiders import Spider
from scrapy.selector import Selector
from scrapyspider.items import weixin_Text
global crawlNum #爬取数量
global outputfile
global SQL_StmtFile
global pageKind
global pageNum
str = time.strftime('%Y_%m_%d__%H_%M_%S',time.localtime(time.time()))
crawlNum = 21
outputfile = open("log_%s.txt"%str, "a+")
SQL_StmtFile = open("SQLstmt_%s.txt"%str, "a+")
pageKind = 0
pageNum = 0
SQL_StmtFile.w
4000
rite("USE db_weixin;\n")
class weixin_TextSpider(Spider):
name = 'weixin.sogou'
handle_httpstatus_list = [404, 500]
download_delay = 1
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
}
def start_requests(self):
url = 'http://weixin.sogou.com/'
#url="http://weixin.sogou.com/pcindex/pc/pc_3/15.html"
yield Request(url, headers=self.headers)
def parse(self, response):
global crawlNum
global outputfile
global SQL_StmtFile
global pageKind
global pageNum
item = weixin_Text()
try:
if response.status in self.handle_httpstatus_list:
outputfile.write(str(response.status))
raise Exception(Exception,response.status)
#outputfile.write(str(response.status))
if pageNum == 0 :
#第 0 页
weixinSelector = response.xpath('//ul[@class="news-list"]/li')
else:
#第 1+ 页
weixinSelector = response.xpath('//body//li')
if weixinSelector:
#获取到了 一个weeixin_Text的 List
for weixin in weixinSelector:
item['title'] = weixin.xpath(
'.//div[@class="txt-box"]/h3/a/text()').extract()[0].encode("utf-8").replace(",", ",").replace("\"","“").replace("\'","‘")
item['summary'] = weixin.xpath(
'.//p/text()').extract()[0].encode("utf-8").replace(",", ",").replace("\"","“").replace("\'","‘")
item['name_GZH'] = weixin.xpath('.//div[@class =\"s-p\"]/a/text()').extract()[0].encode("utf-8")
item['classifyKind'] = pageKind
item['publishTime'] = "-"
item['scrapyCrawl_Time'] = time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
SQL_StmtFile.write("INSERT INTO weixin_Text(id,classifyKind,scrapyCrawl_Time,title,name_GZH,publishTime,summary) "+\
" VALUE(\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\",\"%s\");\n"
%("NULL", item['classifyKind'],item['scrapyCrawl_Time'],item['title'],item['name_GZH'],item['publishTime'],item['summary']))
yield item
else:
outputfile.write("###[LOG] 当前页面没有匹配到内容 pageKind=%d,pageNum=%d \n"%(pageKind,pageNum))
pageNum = crawlNum
except Exception as e:
print e
outputfile.write("###[LOG] 异常 e=%s\n\n"%e)
pageNum = crawlNum
else:
outputfile.write("正常")
finally:
if pageKind < crawlNum :
if pageNum < crawlNum:
pageNum +=1
url_next= 'http://weixin.sogou.com/pcindex/pc/pc_%d/%d.html' %(pageKind,(pageNum))
else:
#一个分类栏的 第 0 页
pageKind +=1
pageNum = 0
url_next ='http://weixin.sogou.com/pcindex/pc/pc_%d/pc_%d.html'%(pageKind,pageKind)
outputfile.write("--下一个链接 pageKind=%d url=%s \n"%(pageKind,url_next))
else:
outputfile.write("爬取结束 pageKind=%d" %pageKind)
outputfile.close()
SQL_StmtFile.close()
next_url = url_next
if next_url:
yield Request(next_url, headers=self.headers)爬虫运行了十几次,每次爬一遍‘搜狗微信 http://weixin.sogou.com/’,只能得到5k左右的文章,而且每隔两小时文章更新数量只有几百篇;所以我在三天的时间里共运行十几次,获取文章 89990篇文章;去重后剩下15667篇
基于这15k篇原始数据开始分析;
数据库建表如下:
四个视图:
第一个视图弃用;
第二个视图:从 t_splitwords,和 weixin_text 两个表中按weixinText分类板块分组,并按frequency大小排序;可以查看每个分类板块 最多重复出现的词
第三个视图:weixin_Text 去重后的视图,去重条件如下:weixin_text.classifyKind, weixin_text.title, weixin_text.name_GZH, weixin_text.summary 根据这四个字段选出 不重复独一无二的 weixinText
第四个视图:表 t_splitwords(100w 条数据) 去重 并统计重复次数 以t_splitwords.value, t_splitwords.titleOrSummary, t_splitwords.partOfSpeech三个字段分组
其中 t_splitwords表数据量达到 100w ,一条简单的查询语句要运行几十秒,第一次接触这个量级,不得不开始注意数据库的查询优化
第二步调用jieba分词分析并存入mysql数据库
中文分词知乎的讨论:https://www.zhihu.com/question/19578687
我选用jieba分词
例子
#encoding=utf-8
import jieba
seg_list = jieba.cut("我来到北京清华大学",cut_all=True)
print "Full Mode:", "/ ".join(seg_list) #全模式
seg_list = jieba.cut("我来到北京清华大学",cut_all=False)
print "Default Mode:", "/ ".join(seg_list) #精确模式
seg_list = jieba.cut("他来到了网易杭研大厦") #默认是精确模式
print ", ".join(seg_list)
seg_list = jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造") #搜索引擎模式
print ", ".join(seg_list)输出
【全模式】: 我/ 来到/ 北京/ 清华/ 清华大学/ 华大/ 大学 【精确模式】: 我/ 来到/ 北京/ 清华大学 【新词识别】:他, 来到, 了, 网易, 杭研, 大厦 (此处,“杭研”并没有在词典中,但是也被Viterbi算法识别出来了) 【搜索引擎模式】: 小明, 硕士, 毕业, 于, 中国, 科学, 学院, 科学院, 中国科学院, 计算, 计算所, 后, 在, 日本, 京都, 大学, 日本京都大学, 深造
部分代码:utils_parseString.py 解析从mysql获取的微信文本并再次存入mysql
# -*- coding: utf-8 -*-
# @Time : 2017/03/22 15:54
# @Author : RenjiaLu
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import jieba
import jieba.posseg
from utils_mysql import *
def parseAndSaveString(string,titleOrSummary,stringId,db):
"""parse"""
try:
seg_list = jieba.cut(string,cut_all=True)
except Exception as e:
myException("###1全模式分词","stringId:%d titleOrSummary:%s string:%s"%(stringId,titleOrSummary,string),e)
return
else:
"""第一次分词成功"""
for a_seg in seg_list:
if '' == a_seg:
continue
try:
# posseg_list = jieba.posseg.cut(a_seg)
posseg_list = a_seg
except Exception as e:
myException("###2词性分词","stringId:%d titleOrSummary:%s string:%s a_seg:%s"%(stringId,titleOrSummary,string,a_seg),e)
continue
else:
"""第二次分词成功"""
for posseg_word in posseg_list:
if '' == posseg_word:
continue
# print posseg_word.word,posseg_word.flag
print posseg_word
try:
# indexOfString = string.find(posseg_word.word)
# partOfSpeech = posseg_word.flag
indexOfString = string.find(posseg_word)
partOfSpeech = "-"
"""save"""
# SQLsttmnt = "INSERT INTO t_splitwords VALUE (\'%s\',\'%s\',%d,%d,\'%s\',\'%s\') ;" \
# %("NULL",posseg_word.word,stringId,indexOfString,titleOrSummary,partOfSpeech)
SQLsttmnt = "INSERT INTO t_splitwords VALUE (\'%s\',\'%s\',%d,%d,\'%s\',\'%s\') ;" \
%("NULL",posseg_word,stringId,indexOfString,titleOrSummary,partOfSpeech)
cursor = executeMysqlSttmnt(db,SQLsttmnt)
except Exception as e:
myException("###构造数据并储存","stringId:%d titleOrSummary:%s string:%s posseg_word" \
":%s"%(stringId,titleOrSummary,string,posseg_word),e)
continue
else:
pass
finally:
pass部分代码:utils_mysql.py 连接数据库工具函数集合
# -*- coding: utf-8 -*-
# @Time : 2017/03/22 16:54
# @Author : RenjiaLu
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import MySQLdb
str = time.strftime('%Y_%m_%d__%H_%M_%S',time.localtime(time.time()))
outputfile = open("log/log_%s.txt"%str, "a+")
def cnnctMysql(pHost="localhost",pUser="root",pPasswd="",pDb="db_weixin",pPort=3306,pCharset='utf8'):
"""连接 mysql 数据库"""
try:
db = MySQLdb.connect(host=pHost,user= pUser,passwd=pPasswd,db=pDb,port=pPort,charset=pCharset)
db.autocommit(1)
return db
except Exception as e:
myException("###连接数据库","",e)
else:
print '操作成功'
finally:
pass
def executeMysqlSttmnt(db,sqlSttmnt):
"""执行 mysql 语句
返回 cursor
"""
try:
cursor = db.cursor()
cursor.execute(sqlSttmnt)
return cursor
except Exception as e:
myException("###执行Mysql语句",sqlSttmnt,e)
db.rollback() # 回滚事件
else:
print '操作成功'
finally:
pass
def closeMysql(db):
"""关闭数据库"""
try:
db.close()
except Exception as e:
myException("###关闭数据库","",e)
else:
print '操作成功'
finally:
pass
def myException(whichStep,log,e):
str = "###myException whichstep:%s log:%s e:%s\n"%(whichStep,log,e)
print str
try:
outputfile.write(str)
except Exception as e:
print e使用很简单,我先全模式分词再对其做词性分析,这里有重复分词的问题,这也是数据量这么大的原因,重复次数最多的都是单字,所以后面的可视化操作我略去了单字词条,只分析两个字符及以上的词
第三步: 数据可视化,
plotly数据可视化效果真不错,虽然看了官网也没有找到详细的属性介绍,目前只使用了其中bar类图
# -*- coding: utf-8 -*- # @Time : 2017/03/26 08:54 # @Author : RenjiaLu import plotly.plotly as py import plotly.graph_objs as go import plotly.offline from plotly.graph_objs import * # Generate the figure import plotly.plotly as py import plotly.graph_objs as go list_articalClssfy= ['热门', '推荐', '段子手','养身堂','私房话',\ '八卦精','爱生活','财经迷','汽车迷','科技咖',\ '潮人帮','辣妈帮','点赞党','旅行家','职场人',\ '美食家','古今通','学霸族','星座控','体育迷'] list_articalNum = [904,854,842,907,639,\ 1041,676,966,773,1011,\ 1005,850,720,624,540,\ 720,729,586,377,903] # frequency >= 5 list_articalWordsNum=[1584,1645,1182,1810,1006,\ 1877,1241,1983,1525,1957,\ 1708,1477,1180,1169,1086,\ 1358,1347,1261,627,1751] trace_articalNum = go.Bar( x=list_articalClssfy, y=list_articalNum, name='爬取文章数' ) trace__articalWordsNum = go.Bar( x=list_articalClssfy, y=list_articalWordsNum, name='文章分词数' ) data = [trace_articalNum, trace__articalWordsNum] layout = go.Layout( barmode='stack', title="data_to_view_1 爬取文章数量与分词数量(frequency>=5)" ) fig = go.Figure(data=data, layout=layout) plotly.offline.plot(fig, filename = 'view_html/data_to_view_1.html') #py.iplot(fig, filename='grouped-bar')
生成:https://plot.ly/~RenjiaLu/2/
然后抽取这二十个分类板块中频度前十的词分析
这里取其中的三个分类,如图
代码已上传 github,见文章开头
词云 wordcloud 模块 genWordCloud.py
# -*- coding: utf-8 -*-
# @Time : 2017/03/25 19:54
# @Author : RenjiaLu
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import os
import matplotlib.pyplot as plt
from os import path
from scipy.misc import imread
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import locale
def genWordCloud(dict_data,rootPath = path.dirname(__file__),imgName="ico1.jpg",saveFileName="wordcloud_init.png"):
#设置语言
locale.setlocale(locale.LC_ALL, 'chs')
#字体文件路径
fontPath = "H:/Python27/python_workplace/dataToview/font/msyh.ttc"
#当前工程文件目录
d = rootPath
# 设置背景图片
alice_coloring = imread(path.join(d, imgName))
#构建词云框架 并载入数据
wc = WordCloud(font_path = fontPath,#字体
background_color="white", #背景颜色
max_words=10000,# 词云显示的最大词数
mask=alice_coloring,#设置背景图片
#stopwords=STOPWORDS.add("said"),
width=900,
height=600,
scale=4.0,
max_font_size=200, #字体最大值
random_state=42).fit_words(dict_data)
#载入 DICT 数据
#wc.generate_from_frequencies(dict_data)
#从背景图片生成颜色值
image_colors = ImageColorGenerator(alice_coloring)
# 以下代码显示图片
plt.imshow(wc)
plt.axis("off")
plt.show()
#保存图片
wc.to_file(path.join(d,saveFileName))
pass这里遇到的词云中文乱码的问题,我记录到了另一篇文章中http://blog.csdn.net/renjialu9527/article/details/65937731
贴上生成的词云
效果还可以
最后
熟悉了一遍流程:爬虫找数据-mysql建表建视图优化存取数据-python分析数据可视化操作
20170329 11:39
end

相关文章推荐
- 数据可视化 三步走(一):数据采集与存储,利用python爬虫框架scrapy爬取网络数据并存储
- python爬虫+R数据可视化 实例
- 基于scrapy爬虫的天气数据采集(python)
- python中文分词jieba总结
- Python爬虫实现数据可视化,为你做一个城市旅游数据分析
- python爬虫(4)——统计并可视化数据
- 第三百四十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫数据保存
- python爬虫webdriver.Chrome 数据可视化简单案例matplotlib
- 第三百五十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—数据收集(Stats Collection)
- Python实现数据可视化看如何监控你的爬虫状态【推荐】
- Python爬虫库Scrapy入门1--爬取当当网商品数据
- python3 [爬虫入门实战]scrapy爬取盘多多五百万数据并存mongoDB
- Python网络爬虫阶段总结
- 数据挖掘干货总结(二)--NLP进阶-详解Jieba分词工具
- 使用python scrapy爬虫框架 爬取科学网自然科学基金数据
- Python3 大型网络爬虫实战 004 — scrapy 大型静态商城网站爬虫项目编写及数据写入数据库实战 — 实战:爬取淘宝
- [置顶] 新闻分类系统(Python):爬虫(bs+rq)+数据处理(jieba分词)+分类器(贝叶斯)
- [置顶] 谣言识别系统(Python):爬虫(bs+rq)+数据处理(jieba分词)+分类器(贝叶斯)
- python爬虫框架scrapy思路总结
- python虎扑社区论坛数据爬虫分析报告