Linux Filesystem
2017-03-25 00:00
393 查看
摘要: Linux 文件系统的简单理解
而IO更多的是怎样快速存储和读取(磁盘调度,缓冲,文件分配等)。

我们开机的时候首先要通过MBR (MASTER BOOT RECORD,512bytes,包含引导加载程序), 磁盘的第一个扇区去寻找其他所需程序的位置,而这个位置就是对硬盘进行分区来实现的(分区的最小单位为柱面cylinder),因为第一扇区的分区表只有(64bytes)只能存储四个分区的数据(起始位置)。另外分区也有助于数据的安全和性能(比如查询定位)。
扩展分区就是将一个分区来纪录分区信息(此时不可被格式化),然后将扩展分区的那个区用来进行逻辑分区。另外扩展分区最多只能有一个(操作系统限制)。
每种操作系统支持的文件权限和属性都不一样,所以需要格式化成操作系统需要的格式。
Linux 使用的Ext2,包括以下内容:
super block:纪录此文件系统的整体信息,总量,使用量等
block group:分组
inode: 纪录文件的属性以及数据的block号码。大量block号码使用(inodetable)
block:实际存放数据的内容或者叫记录,1k,2k,4k
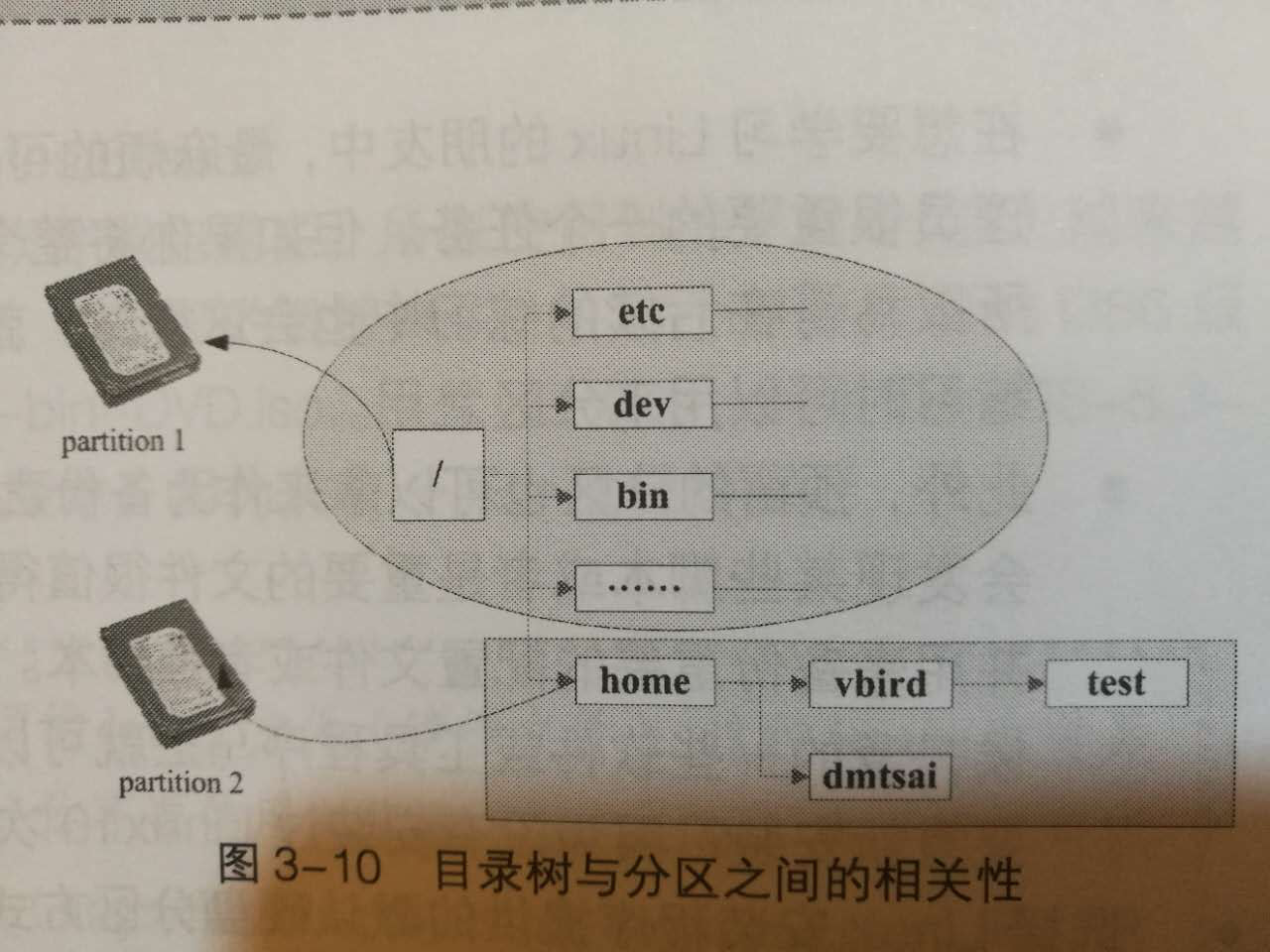
与目录树的关系?
每个目录至少包含一个inode(目录的权限和属性) 和 block(目录下文件名以及它的inode号码)。
所以访问数据的过程会先从 /开始,不断向下寻找。
LVM 提供更自由的文件系统管理与动态分区
LVM
RAID
数据出错可恢复性较高。
在关系型数据库中,我们需要存储记录 (account_number, branch_name, balance ), 一条数据一个记录。
第一种情况:记录是定长的,那么每一条记录大小固定,删除的位置可以由插入的位置填充 O(1)。
只需要多一个文件头来记录删除位置即可。
第二种:变长记录,通过分槽的页结构来记录。
第三种:大对象(超过一个块的记录),使用B+树组织文件结构
而关系型数据库中,关系就是记录的集合,我们通过文件来组织这些记录来实现数据库的需求。
顺序文件组织
按顺序存储。
多表聚类文件组织
将有关系的两个表存储至统一文件中,比如,外键的表。
这些组织方式都是为了减少磁盘访问次数(IO瓶颈)。
Hadoop HDFS
alibaba tfs
前言
我们知道操作系统有管理文件的功能,管理文件的过程就是,用户通过应用程序访问(适当的权限和不同的访问方法)目录和文件,文件会通过不同的结构存储在存储设备中(比如磁盘)。而IO更多的是怎样快速存储和读取(磁盘调度,缓冲,文件分配等)。
分区
为什么要分区?我们开机的时候首先要通过MBR (MASTER BOOT RECORD,512bytes,包含引导加载程序), 磁盘的第一个扇区去寻找其他所需程序的位置,而这个位置就是对硬盘进行分区来实现的(分区的最小单位为柱面cylinder),因为第一扇区的分区表只有(64bytes)只能存储四个分区的数据(起始位置)。另外分区也有助于数据的安全和性能(比如查询定位)。
扩展分区就是将一个分区来纪录分区信息(此时不可被格式化),然后将扩展分区的那个区用来进行逻辑分区。另外扩展分区最多只能有一个(操作系统限制)。
根目录
根目录的设计是为了唯一的定位一个文件。文件系统
磁盘分区完之后要进行格式化,为什么要进行格式化呢?每种操作系统支持的文件权限和属性都不一样,所以需要格式化成操作系统需要的格式。
Linux 使用的Ext2,包括以下内容:
super block:纪录此文件系统的整体信息,总量,使用量等
block group:分组
inode: 纪录文件的属性以及数据的block号码。大量block号码使用(inodetable)
block:实际存放数据的内容或者叫记录,1k,2k,4k
与目录树的关系?
每个目录至少包含一个inode(目录的权限和属性) 和 block(目录下文件名以及它的inode号码)。
所以访问数据的过程会先从 /开始,不断向下寻找。
挂载
将文件系统挂载至目录,然后就可以访问了。mount
VFS
Virtual Filesystem Switch,管理所有文件系统,提供统一调用接口。LVM
传统文件系统与分区的情况如上面所讲,一个分区格式化成制定的格式,然后挂载文件系统,所以基本上一个文件系统就对应一个分区。LVM 提供更自由的文件系统管理与动态分区
LVM
RAID
磁盘阵列(并行读取)RAID
数据出错可恢复性较高。
数据库文件系统
数据库文件系统也和我们上面看到的lLinux ext2 一样,需要将数据库的访问逻辑映射到磁盘上具体的一个块,我们这里以关系型数据库来描述。在关系型数据库中,我们需要存储记录 (account_number, branch_name, balance ), 一条数据一个记录。
第一种情况:记录是定长的,那么每一条记录大小固定,删除的位置可以由插入的位置填充 O(1)。
只需要多一个文件头来记录删除位置即可。
第二种:变长记录,通过分槽的页结构来记录。
第三种:大对象(超过一个块的记录),使用B+树组织文件结构
而关系型数据库中,关系就是记录的集合,我们通过文件来组织这些记录来实现数据库的需求。
顺序文件组织
按顺序存储。
多表聚类文件组织
将有关系的两个表存储至统一文件中,比如,外键的表。
这些组织方式都是为了减少磁盘访问次数(IO瓶颈)。
分布式文件系统
可以参考下面两个来理解Hadoop HDFS
alibaba tfs

相关文章推荐
- How Does The Linux File System Work?
- linux filesystem introduction
- Linux proc file system for module development
- Redhat Enterprise Linux securely mount remote Linux / UNIX directory or file system using SSHFS
- running 7 Linux Filesystem In-Depth
- The Linux filesystem explained
- Linux文件系统标准 Linux File System Standard
- linux repair filesystem
- linux的filesystem repaier
- Ceph: A Linux petabyte-scale distributed file system
- linux的filesystem repaier
- RH033 Unit16 The Linux Filesystem In-Depth
- Linux Filesystem Hierarchy Standard
- linux-mount: unknown filesystem type 'smbfs'解决方法记录
- 033-Unit 8 The Linux Filesystem In-Depth
- Manually and automatically mount windows file system on Linux
- [已解决]在VMware-server for linux 下装centos错误:an error has occurred. - no valid devices were found on which to create new file system
- rche 033----unit 8 the linux filesystem in-depth
- A note of porting yaffs2 file system to linux 2.6.18, part one.
- linux开机出现repaire filesystem