CNN+LSTM深度学习文字检测
2017-03-22 09:18
225 查看
最近看到论文Detecting Text in Natural Image with Connectionist Text Proposal Network
这是作者的主页
http://www.whuang.org/
论文的阅读可以看下这边博客:
http://www.cnblogs.com/lillylin/p/6277061.html
对文字的检测效果挺不错的,就把它移到了windows平台上。在我的笔记本上cpu模式下大概要10s,gpu模式大概800ms吧。先看下论文运行的效果。
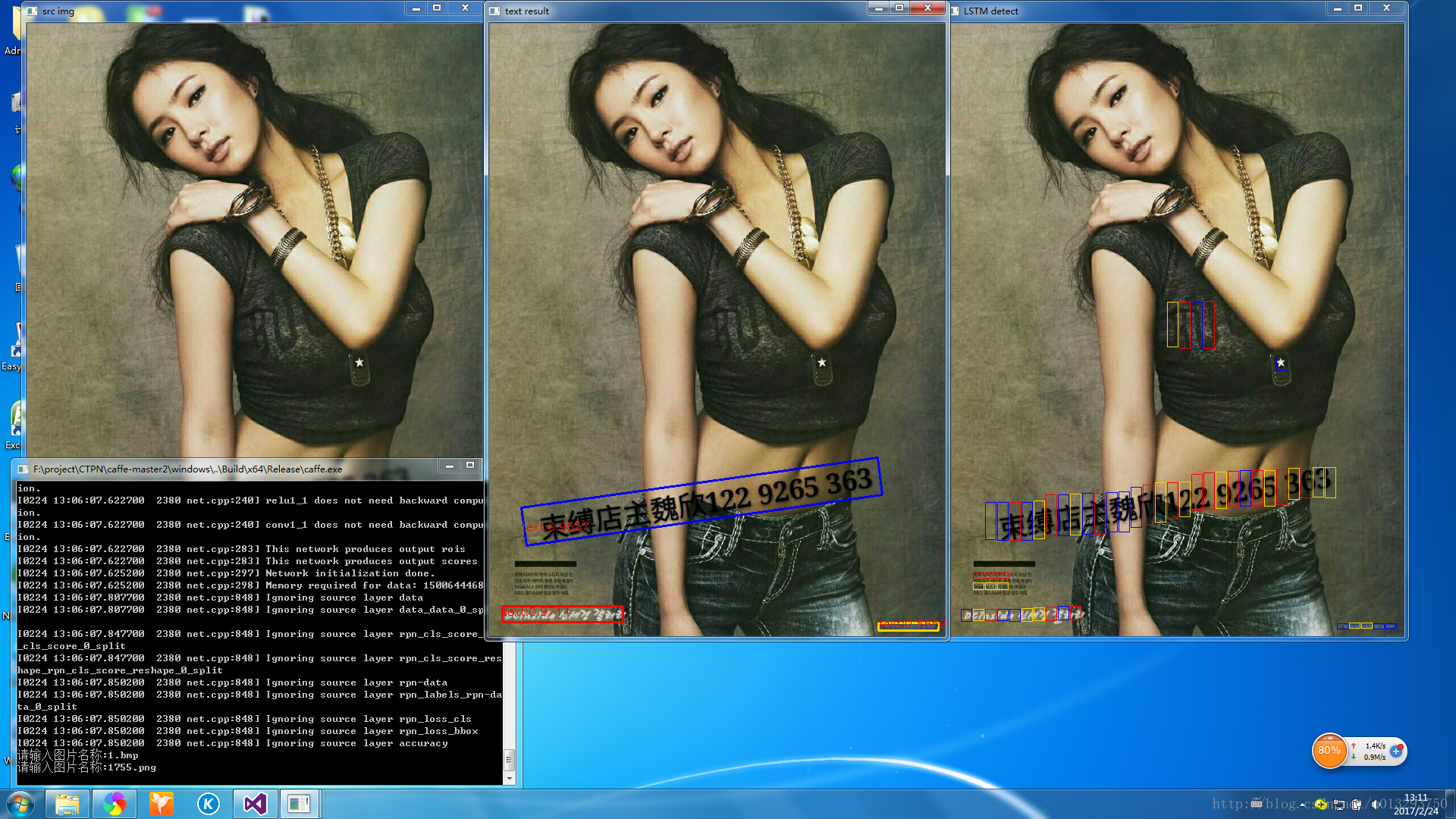

整体效果还是挺好的,作者提供的代码没有对倾斜进行处理,我对检测完的结果稍微做了倾斜角度判断。
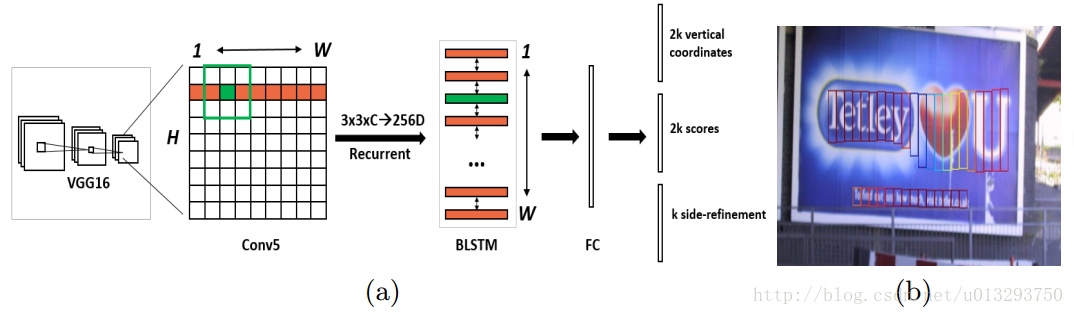
这是作者论文提供的图片。其中side-refinement并没有提供相应的代码,就不做分析了。
1: 输入为3*600(h)*900(w),首先vgg-16提取特征,到conv5-3时,大小为512*38*57。
2: im2col层 512*38*57 ->4608 * 38 * 57 其中4608为(512*9 (3*3卷积展开))
3 : 而后的lstm层 57*38*4608 ->57*38*128 reverse-lstm同样得到的是57*38*128。(双向lstm没有去研 究,但我个人理解应该是左边的结果对右边会产生影响,同样右边也会对左边产生影响,有空再去看)
merge后得到了最终lstm_output的结果 256* 38 * 57
4: fc层 得到512*38*57 fc不再展开,就是一个256*512的矩阵参数
5:rpn_cls_score层得到置信度 512*38*57 ->20*38*57
其中20 = 10 * 2 其中10为10个尺度 同样为512*20的参数,kernel_size为1的卷积层
6:rpn_bbox_pre层 得到偏移 512*38*57 ->20*38*57。同样是十个尺度 2 * 10 * 38 * 57
因为38*57每个点每个scale的固定位置我们是知道的。而它与真实位置的偏移只需两个值便可以得到。
假设固定位置中点( Cx,Cy) 。 高度Ch。实际位置中点(x,y) 高度h
则log(h/Ch)作为一个值
(y-Cy) / Ch作为一个值
20 * 38 * 57 便是10个尺度下得到的这两个值。有了这两个值,我们便能知道真实的文本框位置了。

对得到的矩形框进行nms处理

按照作者提供的条件规则,对小矩形框进行连接,得到文本行

这是作者的主页
http://www.whuang.org/
论文的阅读可以看下这边博客:
http://www.cnblogs.com/lillylin/p/6277061.html
对文字的检测效果挺不错的,就把它移到了windows平台上。在我的笔记本上cpu模式下大概要10s,gpu模式大概800ms吧。先看下论文运行的效果。
—-
整体效果还是挺好的,作者提供的代码没有对倾斜进行处理,我对检测完的结果稍微做了倾斜角度判断。
网络结构
这是作者论文提供的图片。其中side-refinement并没有提供相应的代码,就不做分析了。
1: 输入为3*600(h)*900(w),首先vgg-16提取特征,到conv5-3时,大小为512*38*57。
2: im2col层 512*38*57 ->4608 * 38 * 57 其中4608为(512*9 (3*3卷积展开))
3 : 而后的lstm层 57*38*4608 ->57*38*128 reverse-lstm同样得到的是57*38*128。(双向lstm没有去研 究,但我个人理解应该是左边的结果对右边会产生影响,同样右边也会对左边产生影响,有空再去看)
merge后得到了最终lstm_output的结果 256* 38 * 57
4: fc层 得到512*38*57 fc不再展开,就是一个256*512的矩阵参数
5:rpn_cls_score层得到置信度 512*38*57 ->20*38*57
其中20 = 10 * 2 其中10为10个尺度 同样为512*20的参数,kernel_size为1的卷积层
6:rpn_bbox_pre层 得到偏移 512*38*57 ->20*38*57。同样是十个尺度 2 * 10 * 38 * 57
因为38*57每个点每个scale的固定位置我们是知道的。而它与真实位置的偏移只需两个值便可以得到。
假设固定位置中点( Cx,Cy) 。 高度Ch。实际位置中点(x,y) 高度h
则log(h/Ch)作为一个值
(y-Cy) / Ch作为一个值
20 * 38 * 57 便是10个尺度下得到的这两个值。有了这两个值,我们便能知道真实的文本框位置了。
对检测结果的处理
检测完得到很多个宽度固定(16)的矩形框 conf>0.7对得到的矩形框进行nms处理
按照作者提供的条件规则,对小矩形框进行连接,得到文本行

相关文章推荐
- 深度学习CNN用于目标检测的方法总结
- 【深度学习:目标检测】RCNN学习笔记(4):fast rcnn
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- 深度学习算法之CNN、RNN、LSTM公式推导
- 深度学习算法之CNN、RNN、LSTM公式推导
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- 深度学习目标检测:RCNN,Fast,Faster,YOLO,SSD比较
- 【神经网络与深度学习】【计算机视觉】RCNN- 将CNN引入目标检测的开山之作
- 深度学习实践经验:用Faster R-CNN训练Caltech数据集——训练检测
- 深度学习算法之CNN、RNN、LSTM公式推导
- 【深度学习:目标检测】深度学习检测方法梳理:R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列
- 深度学习检测方法梳理:R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列
- 深度学习(主要是CNN)用于图片的分类和检测总结
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
- [caffe]深度学习之CNN检测object detection方法摘要介绍
- 【深度学习:目标检测】RCNN学习笔记(3):From RCNN to SPP-net
- 【深度学习:目标检测】 Face Detection with the Faster R-CNN(数据集标注对比研究报告 )
- 【深度学习:目标检测】 faster rcnn RPN之anchor(generate_anchors)源码解析
- 深度学习算法之CNN、RNN、LSTM公式推导
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理