python爬虫之2017政府工作报告词频统计
2017-03-15 19:12
375 查看
python爬虫之2017政府工作报告词频统计
工作报告获取中文编码
数据清洗
字符分割统计
python编码中文显示问题
图表显示
文章内容
本文从网络抓取了2017年政府工作报告,并统计了各词语的出现频率,用图表分别显示了被提到超过30次和40次的词语。这里只是做了简单的分词,并没有对专业词汇、人名、数字、成语进行统计。所统计的词组全为两字词语。说到网络爬虫,很多人都觉得是很炫的事,可以把自己关注的东西从海量数据中提取出来,海量数据扯得有点远。我们先来点现实的,本文所述爬虫是完全由我自己写的第一个爬虫程序,经历了很多痛苦。写下来的目的有两个,一是保存起来,为自己爬虫的第一次做个纪念,二是把其中的一些问题与大家交流,以免再次犯错。
废话不多说,先上代码。
@requires_authorization
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
from collections import OrderedDict
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import mlab
from matplotlib import rcParams
def cleanInput(input):
input = re.sub('\n+'," ",input) #去除换行符
input = re.sub('\[[0-9]*\]',"",input) #去除带中括号的数字
input = re.sub('[0-9]',"",input) #去除数字
input = re.sub('[,。.、!:%;”“\[\]]',"",input) #去除中文标点符号
input = re.sub(' +', " ",input) #去除空格
input.strip(string.punctuation) #去除英文标点符号
return input
def getngrams(input, n):
input = cleanInput(input)
output = dict()
for i in range(len(input)-n+1):
newNGram = "".join(input[i:i+n]) #以指定字符串连接生成新的字符串
if newNGram in output:
output[newNGram] += 1 #如果字符出现过则加1
else:
output[newNGram] = 1 #没出现过则设置为1
return output
html = urlopen("http://news.ifeng.com/a/20170305/50754278_0.shtml")
bsObj = BeautifulSoup(html,"lxml")
content = bsObj.find("div",{"id":"main_content"}).get_text()
ngrams = getngrams(content,2)
ngrams = OrderedDict(sorted(ngrams.items(), key=lambda t: t[1], reverse=True))
datafile = open("2017report.txt",'w+')
count = []
count_label = []
for k in ngrams:
print("(%s,%d)" % (k,ngrams[k]))
datafile.write("(%s,%d)\n" % (k,ngrams[k]))
if(ngrams[k]> 30):
count.append(ngrams[k])
count_label.append(k)
x = np.arange(len(count))+1
fig1 = plt.figure(1)
rects =plt.bar(x,count,width = 0.5,align="center",yerr=0.001)
plt.title('2017政府工作报告词频统计')
def autolabel(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x(), 1.03*height, '%s' % int(height))
autolabel(rects)
plt.xticks(x,count_label,rotation=90)
#plt.xticks(x,count_label)
plt.show()部分代码给出了注释,如果有感兴趣的可以阅读《python网络数据采集》这本书,里面的爬虫代码参考自此书。
字符编码问题
从代码中可以看出,整个过程我并没有进行任何的编解码,那为什么我要提这个问题呢?我用的Visual studio Code编辑器写的代码。通过配置编辑器可以直接在里面运行,写完代码之后我确实也是这么干的。接下来的事情困扰了我两天。一开始我爬取的网页是gbk编码,这是中文页面常用的编码。当我输出页面内容时果然出问题了,一团乱码,然后我不断地尝试各种编码,解码。 后来我重新找了一个utf-8编码的网页,也是一样的问题,试了各种办法输出还是乱码,然后去加的一个python学习微信群里找答案,问了不少人,大家给出了各种答案,结果就是都不行。这已经超出编码的常理了。后来我一想会不会是编辑器本身的编码问题呢?然后我就在控制台运行了程序,果然是这样,一切都是那么完美,全部输出了中文,并且没有在代码里做任何的编码处理,正如你在上面代码中看到的一样。好了,问题终于解决了,就是编辑器的编码问题。这里附上一篇vs code编码问题的解决方案。http://jingyan.baidu.com/article/ab0b563080d1a5c15afa7da1.html结果显示
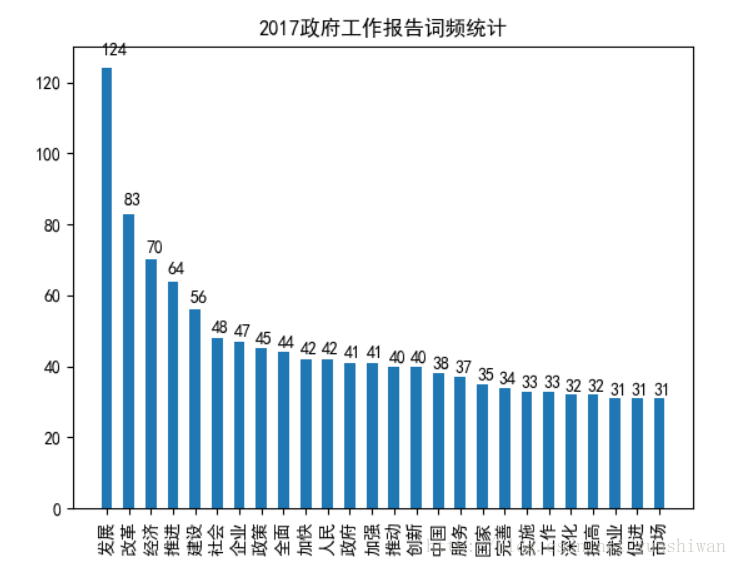
图片显示是政府工作报告中被提到超过30次的词语
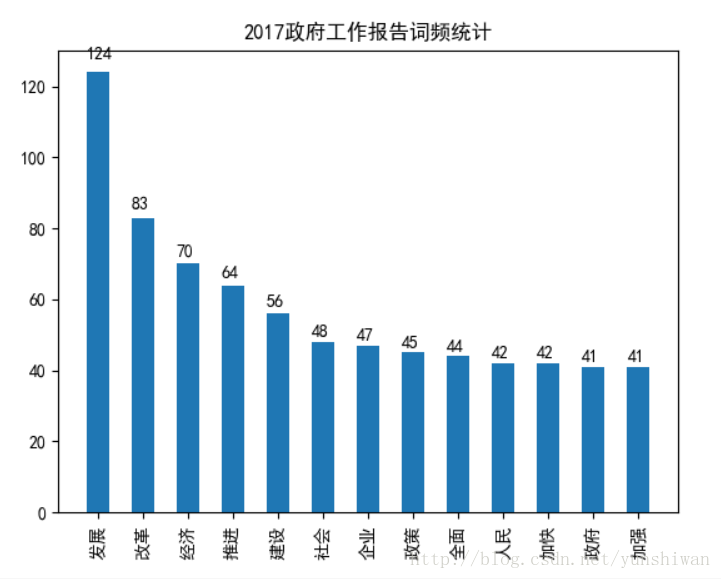
图片显示是政府工作报告中被提到超过40次的词语
可以看出,“发展”和“改革”始终是主题,“推进经济建设”是我们持续不变的目标。“人民”“国家”“就业”“创新”等词也是政府关注的重点。
代码中并没有对一些明显不是词语词组和意思相近的词组做删除和合并,这涉及到更宽广的内容,暂时不做处理。

相关文章推荐
- Python爬虫网易云歌词及词频统计--(周杰伦top50)
- 【python 编程】网页中文过滤分词及词频统计
- WordsCount(词频统计)-Python语言编写!
- python实现爬虫统计学校BBS男女比例之多线程爬虫(二)
- python统计文档词频
- python 统计词频
- python:百度贴吧,统计ID回复数的爬虫,附源码
- Python进行文本预处理(文本分词,过滤停用词,词频统计,特征选择,文本表示)
- python实现爬虫统计学校BBS男女比例(三)数据处理
- python实现爬虫统计学校BBS男女比例(二)多线程爬虫
- python如何将字典中的值转化为list结构,以词频统计为例
- Python实现中文小说词频统计
- python--10行代码搞定词频统计
- python实现爬虫统计学校BBS男女比例(三)数据处理
- python实现爬虫统计学校BBS男女比例(一)
- 词频统计---python与C++的执行效率分析
- python 中自然语言处理(中文)——统计词频
- python实现爬虫统计学校BBS男女比例(二)多线程爬虫
- python实现爬虫统计学校BBS男女比例之数据处理(三)
- python 文本单词提取和词频统计