【总结】Kylin创建Cube,以及优化
2017-03-13 16:03
351 查看
根据上篇文章Kylin创建Model之后,创建Cube
第一步,Cube Info
填写Cube基本信息
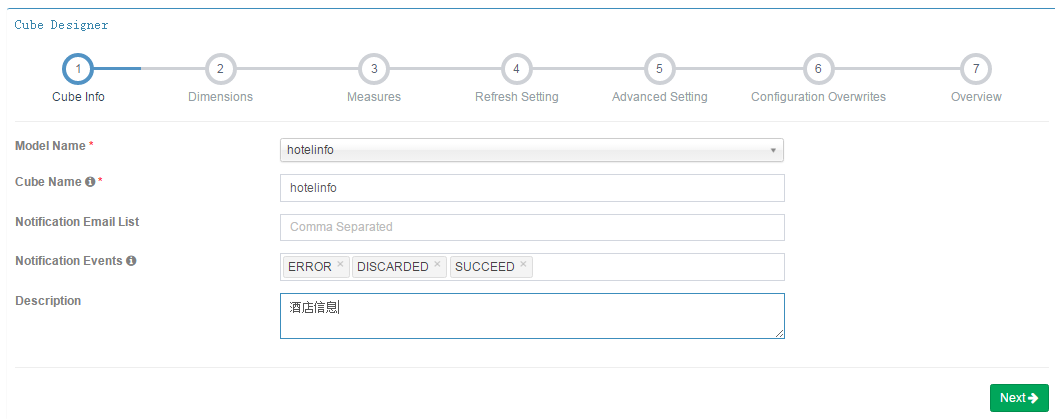
第二步,Dimensions

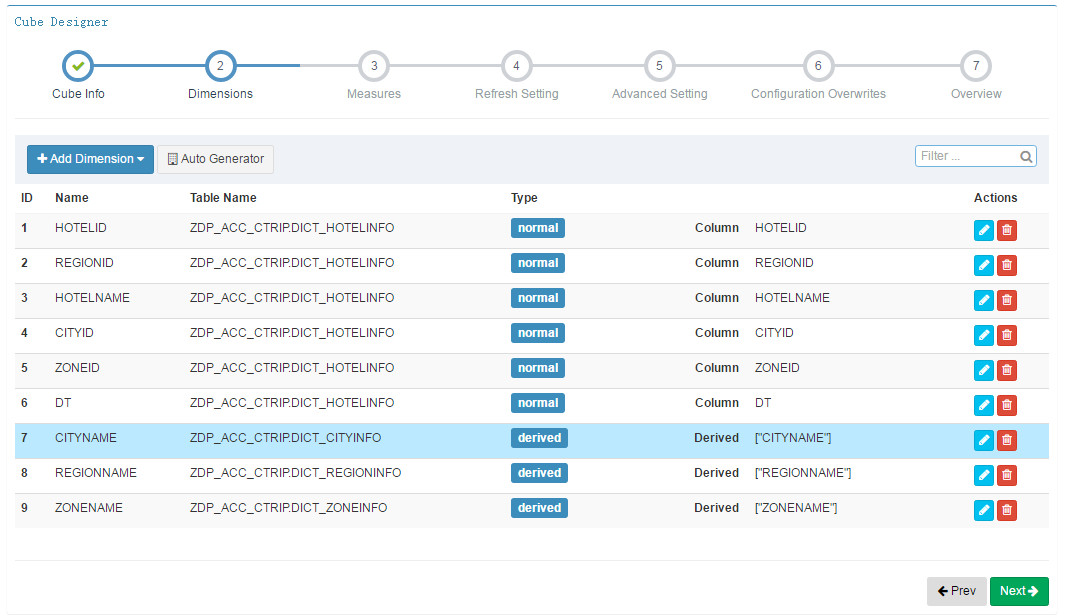
第三步,Measures
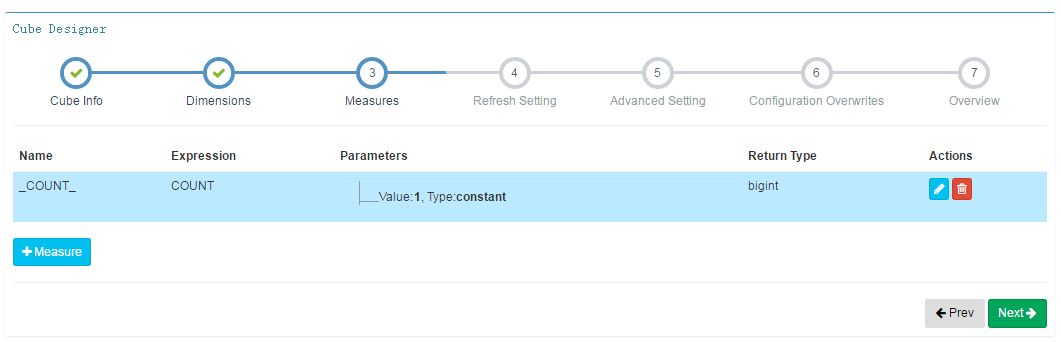
第四步,Refresh Setting
Auto Merge Thresholds :自动合并阈值,按天增加的segement,每7天合并一次;7天的segment每28天合并一次
Retention Threshold:默认为0,保留历史所有的segment(hotelinfo每个分区都是全量数据,所以此处只保留一天的数据)
Partition Start Date:分区开始时间
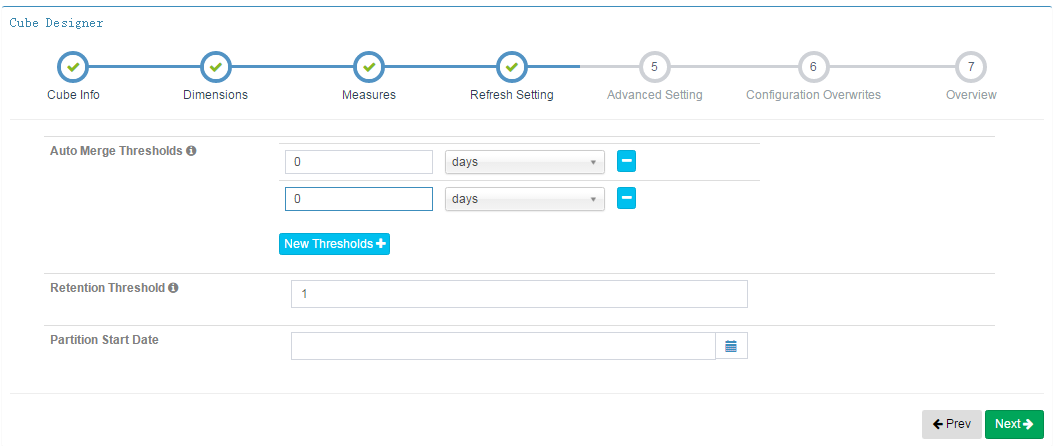
第五步,Advanced Setting
Mandatory Dimensions:强制维度,表示当前ID的Aggregation Group中的所有Cuboid的每一个Cuboid都包含该项配置的维度
Hierarchy Dimensions:层级维度,当有多个维度能够存在层级关系,可以在该配置项中,将这些维度配置为层级维度
例如,国家,省,城市三个维度
Joint Dimensions:联合维度,联合维度中的多个维度,在查询中,要么一起出现,要么都不出现。
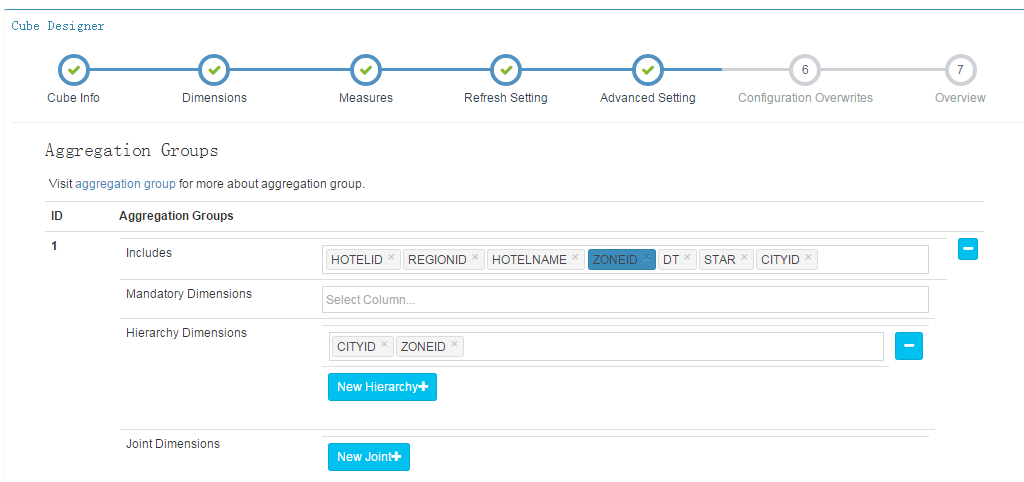
Encoding:编码,指定了该维度的值应该使用何种方式进行编码,选用合适的编码能够有效减少维度对空间是使用,在大数据量情况下效果明显。
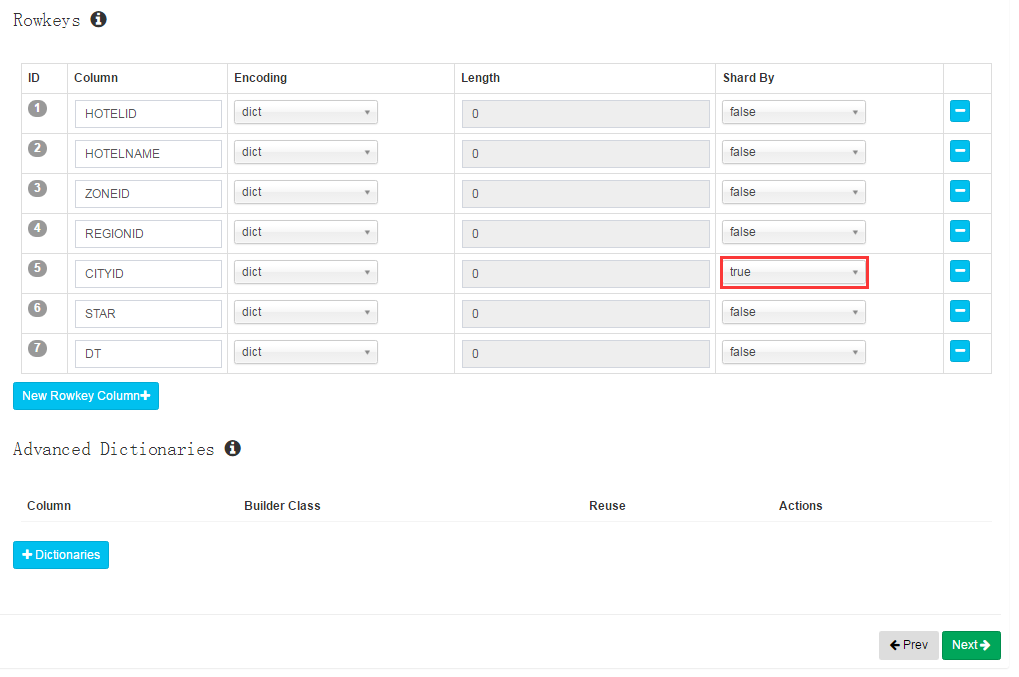
Shard By:按维度对数据进行分片,默认Cuboid的数据分片策略是随机的,并且只能设置一个维度为Share By。
如果Cuboid中的某些行的Shard By Dimension的值是相同的,那么这些行的数据最终将会分配到同一个分片中。
例如:好多酒店都在一个城市当中,如果将CITYID维度设置为Share By,则同一个城市的酒店数据将分配到同一个分片中。
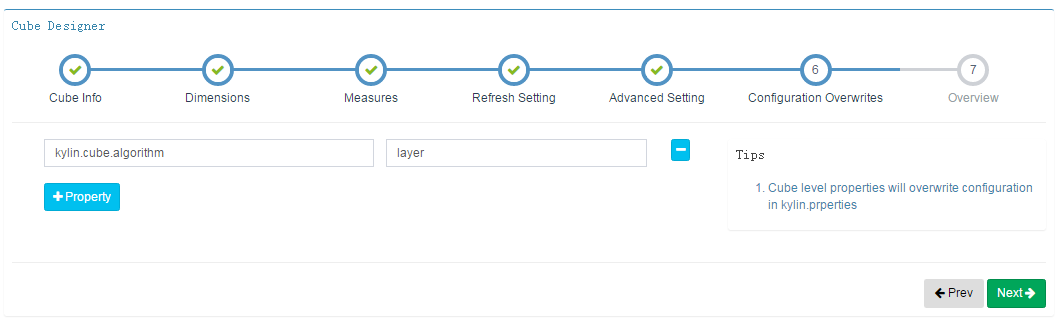
第六步,Configuration Overwrites
覆盖kylin.properties中的配置
第七步,Overivew
Cube概览,点击Save保存

第一步,Cube Info
填写Cube基本信息
第二步,Dimensions
第三步,Measures
第四步,Refresh Setting
Auto Merge Thresholds :自动合并阈值,按天增加的segement,每7天合并一次;7天的segment每28天合并一次
Retention Threshold:默认为0,保留历史所有的segment(hotelinfo每个分区都是全量数据,所以此处只保留一天的数据)
Partition Start Date:分区开始时间
第五步,Advanced Setting
Mandatory Dimensions:强制维度,表示当前ID的Aggregation Group中的所有Cuboid的每一个Cuboid都包含该项配置的维度
Hierarchy Dimensions:层级维度,当有多个维度能够存在层级关系,可以在该配置项中,将这些维度配置为层级维度
例如,国家,省,城市三个维度
Joint Dimensions:联合维度,联合维度中的多个维度,在查询中,要么一起出现,要么都不出现。
Encoding:编码,指定了该维度的值应该使用何种方式进行编码,选用合适的编码能够有效减少维度对空间是使用,在大数据量情况下效果明显。
Shard By:按维度对数据进行分片,默认Cuboid的数据分片策略是随机的,并且只能设置一个维度为Share By。
如果Cuboid中的某些行的Shard By Dimension的值是相同的,那么这些行的数据最终将会分配到同一个分片中。
例如:好多酒店都在一个城市当中,如果将CITYID维度设置为Share By,则同一个城市的酒店数据将分配到同一个分片中。
第六步,Configuration Overwrites
覆盖kylin.properties中的配置
第七步,Overivew
Cube概览,点击Save保存

相关文章推荐
- mysql索引总结----mysql 索引类型, 创建以及优化
- Kylin 的优化以及使用总结
- 在JavaScript中创建对象以及prototype的总结
- 性能优化总结:CPU和Load、NIO以及多线程
- mysql分解连接的总结(来自于高性能MySQL以及自己网站性能优化)
- mongoDB集合 文档创建修改删除以及查询命令总结
- 数据库索引的创建以及常见优化
- 创建字体以及文本控件显示的总结
- MySQL优化--创建索引,以及怎样索引才会生效 (03)
- 微软BI 之SSAS 系列 - 实现Cube 以及角色扮演维度,度量值格式化和计算成员的创建
- 性能优化总结:CPU和Load、NIO以及多线程
- 堆和栈的探讨以及从创建对象层面来优化程序的常识
- 国航OA项目技术总结(二)关于JVM虚拟机中对象的创建,手机端提速的重要优化
- 性能优化总结:CPU和Load、NIO以及多线程
- 数据库性能优化3——Oracle SEQUENCE的概念、作用以及创建(使得并发插入主键唯一)
- 类的加载、创建对象、静态变量static、构造函数、静态代码块、构造代码块、构造方法以及总结
- 性能优化总结:CPU和Load、NIO以及多线程
- hive的查询注意事项以及优化总结
- 详解mysql索引总结----mysql索引类型以及创建
- mysql索引总结----mysql 索引类型以及创建