分布式系统学习技术点一:kafka
2017-03-10 00:00
10 查看
摘要: 消息系统
2、提高系统的响应效率。
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
注意:
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。
Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2、发布/订阅:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列。
ActiveMQ:Apache下的一个子项,类似ZeroMQ,能够以代理人和点对点的技术实现队列 。
Redis:是一个key-Value的NOSql数据库,但也支持MQ功能,数据量较小,性能优于RabbitMQ,数据超过10K就慢的无法忍受
Kafka:是一个分布式的,可划分的,多订阅者,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如 ETL,以及实时应用程序。通过将数据持久化到硬盘以及 replication 防止数据丢失。
分布式系统,易于向外扩展。所有的 producer、broker 和 consumer 都会有多个,均为分布式的。无需停机即可扩展机器。
消息被处理的状态是在 consumer 端维护,而不是由 server 端维护。当失败时能自动平衡。(消息的状态不由broker维护)
Consumer:特指消息的消费者
Consumer Group:消费者组,可以并行消费Topic中partition的消息。可以这样理解。每个consumer group对应一个topic,每个consumer对应的是一个partition。
Broker:缓存代理,Kafa 集群中的一台或多台服务器统称为 broker。Message在Broker中通Log追加的方式进行持久化存储。并进行分区(patitions)。为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
broker无状态机制:
Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。消息有副本。
Broker不保存订阅者的状态,由订阅者自己保存。
无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息。
Topic:特指 Kafka 处理的消息源(feeds of messages)的不同分类。一个Topic可以认为是一类消息,每个topic将被分成多个partition(区)。
Partition:Topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。每个partition在存储层面是append log文件。
Message:消息,是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。
Producers:消息和数据生产者,向 Kafka 的一个 topic 发布消息的过程叫做 producers。Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等。Kafka producer的异步发送模式允许进行批量发送,先将消息缓存在内存中,然后一次请求批量发送出去。
Consumers:消息和数据消费者,订阅 topics 并处理其发布的消息的过程叫做 consumers。在 kafka中,我们 可以认为一个group是一个“订阅者”,一个Topic中的每个partions,只会被一个“订阅者”中的一个consumer消费,不过一个 consumer可以消费多个partitions中的消息(消费者数据小于Partions的数量时)。对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
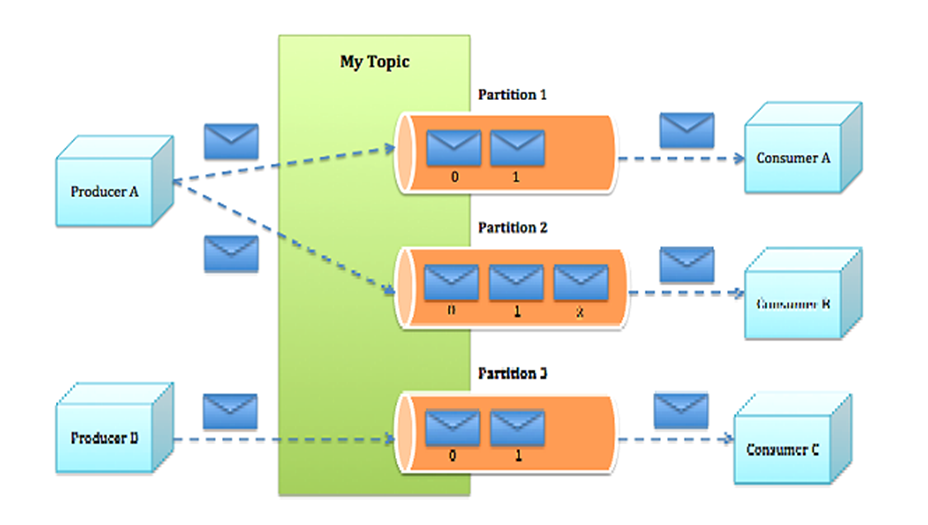
Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
partition中的每条Message包含了以下三个属性:
offset 对应类型:long
MessageSize 对应类型:int32
data 是message的具体内容
可以将一个topic切分多任意多个partitions,来消息保存/消费的效率,越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
由于是追加的方式,读操作不会阻塞写操作和其他操作,不用考虑同步的问题,同时线性地访问数据,数据大小不对性能产生影响;
一个Topic可以认为是一类消息,每个topic将被分成多partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),partition是以文件的形式存储在文件系统中。Logs文件根据broker中的配置要求,保留一定时间后删除来释放磁盘空间。
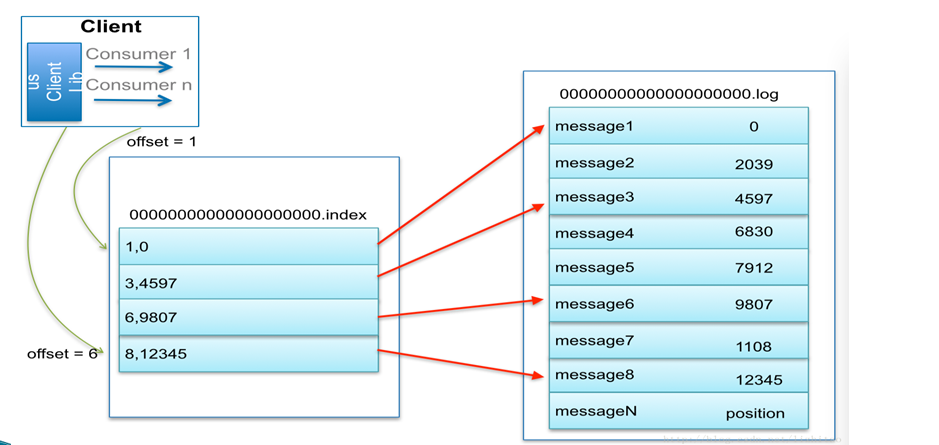
下图为一个partition的索引示意图:
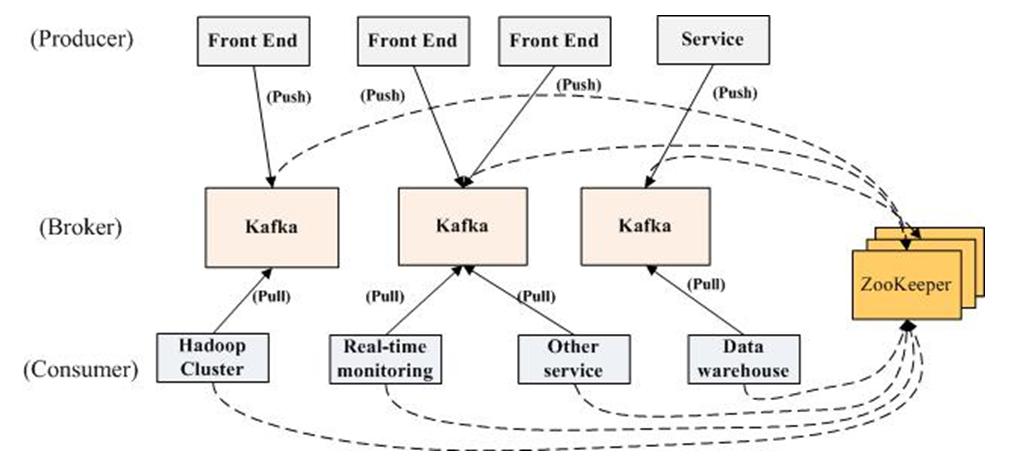
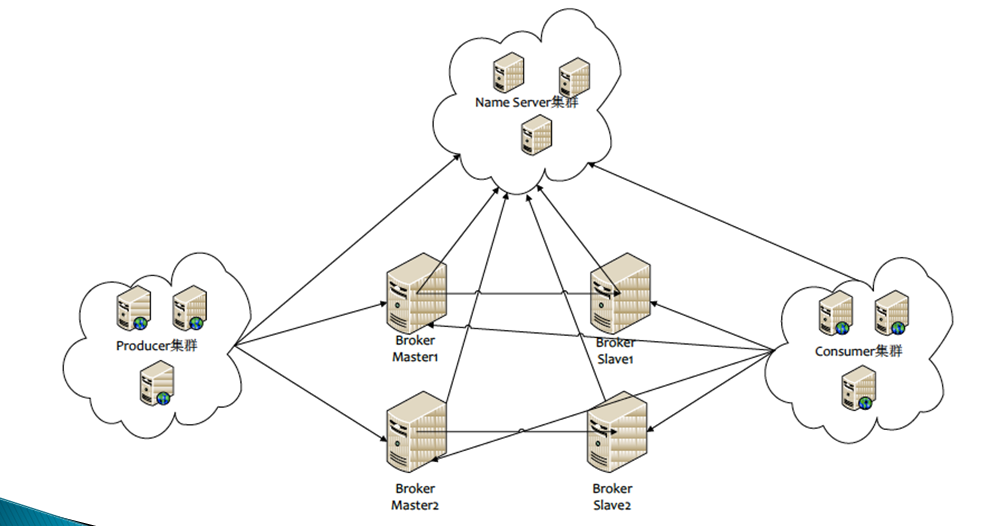
说明:Producer消息push到broker中,同时通知zookeeper,zookeeper告知Consumer消费消息,consumer自己去拉取消息,消费了消息也会通知zookeeper它消费了哪条消息。
at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者fetch消息,然后处理消息,然后保存offset。如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。
exactly once: 消息只会发送一次。kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的。
注:通常情况下"at-least-once"是我们首选。(相比at most once而言,重复接收数据总比丢失数据要好)。
http://kafka.apache.org/downloads
2、解压
tar -zxvf kafka_2.12-0.10.2.0
3、查看文件结构与相关配置文件
4、配置文件x相关说明。
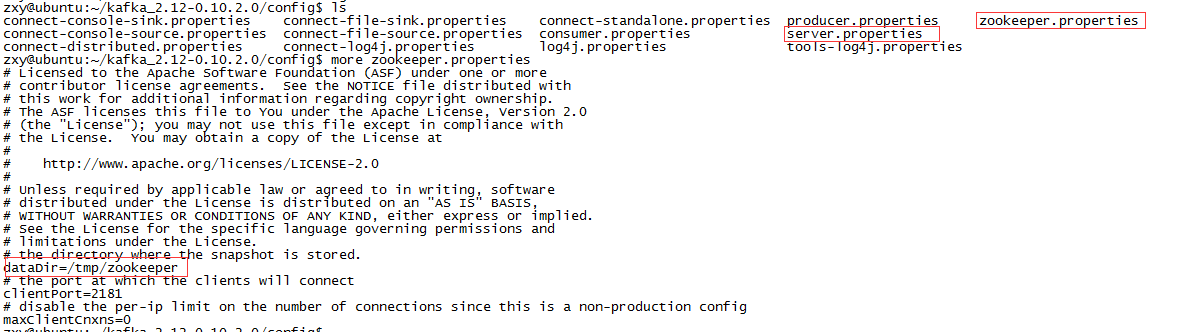
zookeeper.properties:
dataDir为数据存放的目录,最好修改为自己需要存放的目录。
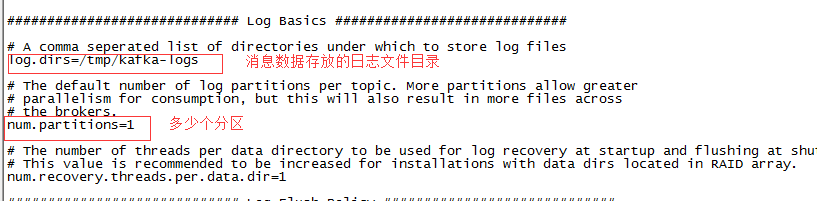
server.properties


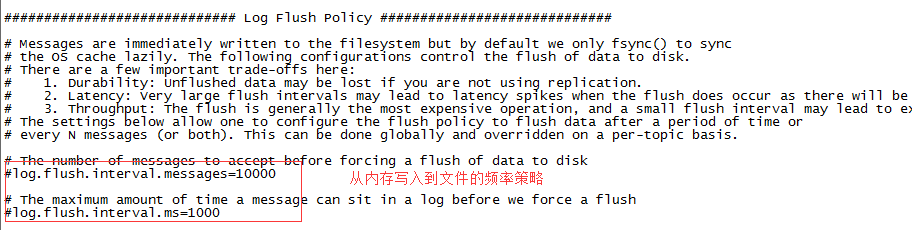

producer.properties
这个文件的相关配置一般是在程序中去设置。

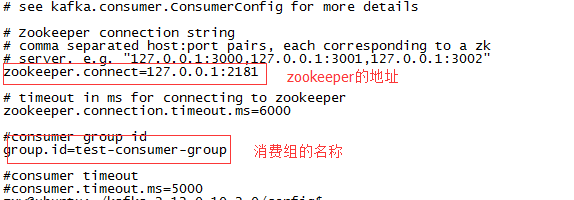
consumer.properties
这个文件的相关配置一般是在程序中去设置。
5、启动服务
先启动zookeeper:bin/zookeeper-server-start.sh config/zookeeper.properties
再启动kafka:bin/kafka-server-start.sh config/server.properties
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
2、查看所有的topic
kafka-topics.sh --list --zookeeper localhost:2181
3、查看topic详细信息。
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
4、删除topic
bin/kafka-run-class.sh kafka.admin.TopicCommand –delete --topic test --zookeeper 192.168.1.161:2181
5、创建生产者 producer:这里要指定写到哪个broker。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
6、创建消费者 consumer:--from-beginning表示从头开始。
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
这里kafka选用2.12版本,maven依赖:
生产者代码:
重要的类:
1、Producer:接口,生产消息的重要接口,根据它的实现KafkaProducer类实例化Producer。
注意使用的topic需要提前创建,当然也有java api创建方式,这里不做说明。关于具体生产消息到哪个分区,是可以指定的,因为这里创建的topic只有一个分区,没有指定。
2、ProducerRecord:封装要发送的消息。
消费者代码:
重要的类:
1、ConsumerConnector:消费者与broker的连接
2、KafkaStream:封装了一个topic所在某个分区的所有消息的key和value。
附:http://www.jasongj.com/2015/01/02/Kafka%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90/
一、认识消息队列

消息队列的作用:
1、解耦合。2、提高系统的响应效率。
消息队列的两种形式:
1、点对点:消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
注意:
消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的消息。
Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
2、发布/订阅:
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
常见的消息队列技术:
RabbitMQ:支持的协议多,非常重量级消息队列,对路由(Routing),负载均衡(Load balance)或者数据持久化都有很好的支持。ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列。
ActiveMQ:Apache下的一个子项,类似ZeroMQ,能够以代理人和点对点的技术实现队列 。
Redis:是一个key-Value的NOSql数据库,但也支持MQ功能,数据量较小,性能优于RabbitMQ,数据超过10K就慢的无法忍受
Kafka:是一个分布式的,可划分的,多订阅者,冗余备份的持久性的日志服务。它主要用于处理活跃的流式数据。
二、认识kafka
kafka的特点:
同时为发布和订阅提供高吞吐量。据了解,Kafka 每秒可以生产约 25 万消息(50 MB),每秒处理 55 万消息(110 MB)。可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如 ETL,以及实时应用程序。通过将数据持久化到硬盘以及 replication 防止数据丢失。
分布式系统,易于向外扩展。所有的 producer、broker 和 consumer 都会有多个,均为分布式的。无需停机即可扩展机器。
消息被处理的状态是在 consumer 端维护,而不是由 server 端维护。当失败时能自动平衡。(消息的状态不由broker维护)
核心概念理解:
Producer:特指消息的生产者Consumer:特指消息的消费者
Consumer Group:消费者组,可以并行消费Topic中partition的消息。可以这样理解。每个consumer group对应一个topic,每个consumer对应的是一个partition。
Broker:缓存代理,Kafa 集群中的一台或多台服务器统称为 broker。Message在Broker中通Log追加的方式进行持久化存储。并进行分区(patitions)。为了减少磁盘写入的次数,broker会将消息暂时buffer起来,当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样减少了磁盘IO调用的次数。
broker无状态机制:
Broker没有副本机制,一旦broker宕机,该broker的消息将都不可用。消息有副本。
Broker不保存订阅者的状态,由订阅者自己保存。
无状态导致消息的删除成为难题(可能删除的消息正在被订阅),kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常为7天)后会被删除。
消息订阅者可以rewind back到任意位置重新进行消费,当订阅者故障时,可以选择最小的offset(id)进行重新读取消费消息。
Topic:特指 Kafka 处理的消息源(feeds of messages)的不同分类。一个Topic可以认为是一类消息,每个topic将被分成多个partition(区)。
Partition:Topic 物理上的分组,一个 topic 可以分为多个 partition,每个 partition 是一个有序的队列。partition 中的每条消息都会被分配一个有序的 id(offset)。每个partition在存储层面是append log文件。
Message:消息,是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。
Producers:消息和数据生产者,向 Kafka 的一个 topic 发布消息的过程叫做 producers。Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等。Kafka producer的异步发送模式允许进行批量发送,先将消息缓存在内存中,然后一次请求批量发送出去。
Consumers:消息和数据消费者,订阅 topics 并处理其发布的消息的过程叫做 consumers。在 kafka中,我们 可以认为一个group是一个“订阅者”,一个Topic中的每个partions,只会被一个“订阅者”中的一个consumer消费,不过一个 consumer可以消费多个partitions中的消息(消费者数据小于Partions的数量时)。对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
kafka的逻辑结构
kafka的message组成
Message消息:是通信的基本单位,每个 producer 可以向一个 topic(主题)发布一些消息。Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相互独立的。每个topic又可以分成几个不同的partition(每个topic有几个partition是在创建topic时指定的),每个partition存储一部分Message。
partition中的每条Message包含了以下三个属性:
offset 对应类型:long
MessageSize 对应类型:int32
data 是message的具体内容
kafka分区的目的
kafka基于文件存储。通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率,越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力。
kafka持久化
Kafka直接将数据写入到日志文件中。由于是追加的方式,读操作不会阻塞写操作和其他操作,不用考虑同步的问题,同时线性地访问数据,数据大小不对性能产生影响;
一个Topic可以认为是一类消息,每个topic将被分成多partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),partition是以文件的形式存储在文件系统中。Logs文件根据broker中的配置要求,保留一定时间后删除来释放磁盘空间。
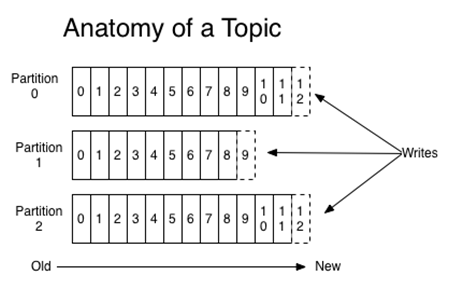
kafka的稀疏索引:
为数据文件建索引:稀疏存储,每隔一定字节的数据建立一条索引。下图为一个partition的索引示意图:
kafka的分布式实现:
说明:Producer消息push到broker中,同时通知zookeeper,zookeeper告知Consumer消费消息,consumer自己去拉取消息,消费了消息也会通知zookeeper它消费了哪条消息。
kafka的通讯协议
kafka数据传输的事务定义
at most once: 最多一次,这个和JMS中"非持久化"消息类似,发送一次,无论成败,将不会重发。消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理。那么此后"未处理"的消息将不能被fetch到,这就是"at most once"。at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者fetch消息,然后处理消息,然后保存offset。如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。
exactly once: 消息只会发送一次。kafka中并没有严格的去实现(基于2阶段提交,事务),我们认为这种策略在kafka中是没有必要的。
注:通常情况下"at-least-once"是我们首选。(相比at most once而言,重复接收数据总比丢失数据要好)。
三、kafka的安装与相关配置(Linux)
1、下载http://kafka.apache.org/downloads
2、解压
tar -zxvf kafka_2.12-0.10.2.0
3、查看文件结构与相关配置文件
4、配置文件x相关说明。
zookeeper.properties:
dataDir为数据存放的目录,最好修改为自己需要存放的目录。
server.properties
producer.properties
这个文件的相关配置一般是在程序中去设置。
consumer.properties
这个文件的相关配置一般是在程序中去设置。
5、启动服务
先启动zookeeper:bin/zookeeper-server-start.sh config/zookeeper.properties
再启动kafka:bin/kafka-server-start.sh config/server.properties
四、kafka相关命令
1、创建topic: 创建一个"test"的topic,--replication-factor 1:一个分区。--partitions 1:一个副本。bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
2、查看所有的topic
kafka-topics.sh --list --zookeeper localhost:2181
3、查看topic详细信息。
bin/kafka-topics.sh --describe --zookeeper localhost:2181 --topic test
4、删除topic
bin/kafka-run-class.sh kafka.admin.TopicCommand –delete --topic test --zookeeper 192.168.1.161:2181
5、创建生产者 producer:这里要指定写到哪个broker。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
6、创建消费者 consumer:--from-beginning表示从头开始。
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
五、java操作kafka
注意:尽量保证使用的kafka服务版本和java 操作kafka的sdk一致。这里kafka选用2.12版本,maven依赖:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka_2.12</artifactId> <version>0.10.2.0</version> </dependency>
生产者代码:
重要的类:
1、Producer:接口,生产消息的重要接口,根据它的实现KafkaProducer类实例化Producer。
注意使用的topic需要提前创建,当然也有java api创建方式,这里不做说明。关于具体生产消息到哪个分区,是可以指定的,因为这里创建的topic只有一个分区,没有指定。
2、ProducerRecord:封装要发送的消息。
Properties props = new Properties();
props.setProperty("bootstrap.servers","localhost:9092");//指定broker
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");//指定序列的方式,这里传递字符串即采用提供的字符串序列类
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer producer = new KafkaProducer(props);
ProducerRecord<String,String> pr = new ProducerRecord<String, String>("test3","value-1");//给topic为test3的消息队列,发送消息,内容为value-1
producer.send(pr);
producer.close();消费者代码:
重要的类:
1、ConsumerConnector:消费者与broker的连接
2、KafkaStream:封装了一个topic所在某个分区的所有消息的key和value。
Properties pro = new Properties();
pro.setProperty("zookeeper.connect","localhost:2181");//zookeeper的地址
pro.setProperty("key.deserializer","org.apache.kafka.common.serialization.StringDeserializer");//对应的反序列方式
pro.setProperty("value.deserializer","org.apache.kafka.common.serialization.StringDeserializer");
pro.setProperty("group.id","test-group-consumer");
ConsumerConfig config = new ConsumerConfig(pro);
ConsumerConnector connector = Consumer.createJavaConsumerConnector(config);//取得消费broker的连接
//指定需要取那些topic的值以及对应的从哪个分区去取,这里指定从第一个分区取
Map<String,Integer> topInfo = new HashMap<String,Integer>();
topInfo.put("test3",1);
//取消息
Map<String, List<KafkaStream<byte[], byte[]>>> message =connector.createMessageStreams(topInfo);
//取topic为test3的第一个分区的消息
KafkaStream<byte[], byte[]> stream = message.get("test3").get(0);
//便利出partiction为1,topic为test3的所有消息
ConsumerIterator<byte[], byte[]> it = stream.iterator();
while(it.hasNext()){
System.out.println(new String(it.next().message()));
}附:http://www.jasongj.com/2015/01/02/Kafka%E6%B7%B1%E5%BA%A6%E8%A7%A3%E6%9E%90/

相关文章推荐
- 分布式系统学习技术点三:zookeeper篇二(进阶)
- 分布式系统学习技术点二:Mycat篇一(使用入门)
- 分布式系统学习技术点二:Mycat篇二(进阶)
- 学习J2ME编程需要掌握的七种技术
- .NET技术学习笔记:
- [转载]计算机科学技术学习引论
- 我打算学习的一些JAVA技术
- unix并发技术的学习及在扫描器上的应用二
- 分布式开发技术 我的学习历程(二)
- [链接] Raid 技术学习, 红旗linux上的软raid
- STL技术文章不完全列表(STL学习使用指南)
- 分布式开发技术 我的学习历程(一)
- EJB学习之入门初探篇-EJB技术的发展史
- 反对中小学生学习黑客技术的十大理由
- 胡言乱语最近学习中发现的技术小问题!
- 学习Duwamish7的MSDN说明及相关技术策略
- jsp---学习笔记(五)核心技术-语法详解
- unix并发技术的学习及在扫描器上的应用二
- java技术要学习的内容
- 最新电脑网络技术学习资料汇总