Hbase总结(二)--Hbase查询过滤器简介
2017-03-09 00:00
176 查看
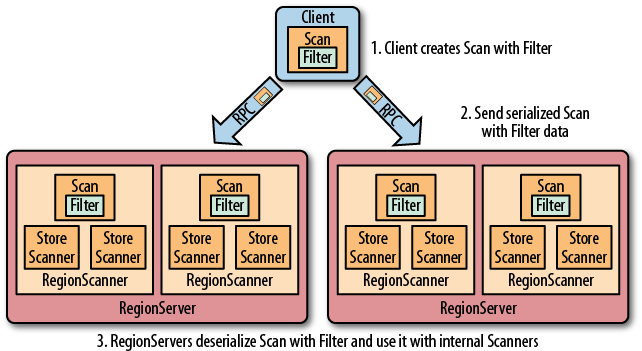
Hbase过滤器提供了非常强大的特性来帮助用户提高处理表中的数据的效率,Hbase过滤器的作用是在查询中添加更多的限制条件来减少查询得到的数据量。值得注意是的是Hbase的所有过滤器都是在服务器段生效的,这样可以保证被过滤掉的数据不会被传送到客户端,所以过滤器只能用来筛选掉无用的数据,不能用来查询用户指定用户需要哪些信息。我们自己在Hbase客户端实现的过滤功能,不会减小服务端传送到客户端的数据量(可能会影响系统性能)。Hbase的Filter执行过程,入下图
1. hbase的过滤器分类如下:
2.hbase是的行键值具有索引的,所以使用和行键进行过滤时,性能会比较高。常用的行键过滤器有RowFileter(单个行键的查询),PreFixFilter(多行键的查询)
3.hbase的查询框架推荐使用spring-data-hadoop hbase框架,该框架已经对hbase的查询操作做了一些很好的封装,配置也比较方便。详细的使用方法将会在Hbase的过滤器(三)--spring-data-hadoop hbase框架中介绍使用方法
1. hbase的过滤器分类如下:
| 行过滤器 | 查询速度 | 使用场景 | 过滤器的实现 |
|---|---|---|---|
| 行过滤器 | 最好 | 基于行键来过滤数据的场景 | 单个条件过滤行 |
| 列族过滤器 | -- | 通过比较列族来返回结果,需要组合使用 | 只对单个列族起作用 |
| 值过滤器 | -- | 筛选某个特定值的单元格 | 可以使用功能强大的表达式来筛选 |
| 参考列过滤器 | -- | 不仅可以通过指定的信息筛选数据,还能通过指定一个参考列或者引用列,并通过参考列来控制其他列的过滤 | 多行多列 |
| 专用过滤器 | -- | 特定场景下使用 | -- |
3.hbase的查询框架推荐使用spring-data-hadoop hbase框架,该框架已经对hbase的查询操作做了一些很好的封装,配置也比较方便。详细的使用方法将会在Hbase的过滤器(三)--spring-data-hadoop hbase框架中介绍使用方法

相关文章推荐
- HBase查询(1)---Comparision Filters比较过滤器
- HBase查询(3)---Decorating Filters装饰性过滤器
- hbase常用查询总结
- HBase内置过滤器的一些总结
- Hbase(四) 过滤器查询
- Oracle 11g 第一章知识点总结——数据库简介 简单查询
- 009-elasticsearch【三】示例数据导入、URI查询方式简介、Query DSL简介、查询简述【_source、match、must、should等】、过滤器、聚合
- C#通过Thrift连接查询HBase主要方法总结
- HBase总结(8)--附加过滤器、FilterList
- 使用filter(过滤器)按照条件查询hbase
- HBase Client API使用(二)---查询及过滤器
- Hbase过滤器的一些总结
- HBase内置过滤器的一些总结
- HBase内置过滤器的一些总结
- HBase总结(5)--过滤器介绍
- HBase查询(2)---Dedicated Filters专用过滤器
- HBase内置过滤器的一些总结
- HBase-7.hbase查询多版本数据&过滤器原则&批量导入Hbase&hbase预分区
- HBase内置过滤器的一些总结
- 【十八掌●武功篇】第八掌:HBase之过滤器总结