hashMap表面源码分析
2017-03-06 11:33
190 查看
hashMap底层主要使用了数组+单向链表的数据接口(jdk1.8当链表过长的时候使用了树的结构)
初始化:赋值数组的长度16,和加载因子值0.75f,并没有生成数组。
get操作
put
1,初始化时都做了什么事,什么时候才创建数组?
初始化时默认设置了threshold为16和loadFactor为0.75f。
在第一次put的时候才真正的创建数组长度16,并赋值threshold为12。当实际存储的链表个数超过12时开始扩容。
2,加载因子的作用?
加载因子是hashMap时间和空间的比值。加载因子越大,扩容越慢,链表长度越长,查询慢。
加载因子越小,扩容越快,链表越短,查询快。
所以没有特殊要求还是使用默认值0.75较好。
2,为什么数组大小和扩容时要控制在2的整数倍?
可以发现在初始化时必须要求是2的整数倍,扩容时也是扩容2倍,而不像ArrayList扩容时为1.5倍。
其原因在于数组长度为2的倍数时,散列会平均,效率变高 h & (length -1)会比去模效率高,length为奇数时,
length - 1末尾为0,h & 末尾为0的数时,最后一位永远是0,hash只能散列到偶数的位置,浪费空间。
3,hashMap插入时,是头插还是尾插?
头插。在插入的时候,新建了entry,把next结点指向头结点,如果是尾插的话,需要循环到尾位置,多操作。
同理可知,在扩容的时候会导致链表反转。
4,hashMap多线程使用时发生死循环,为什么?
可通过源码分析。
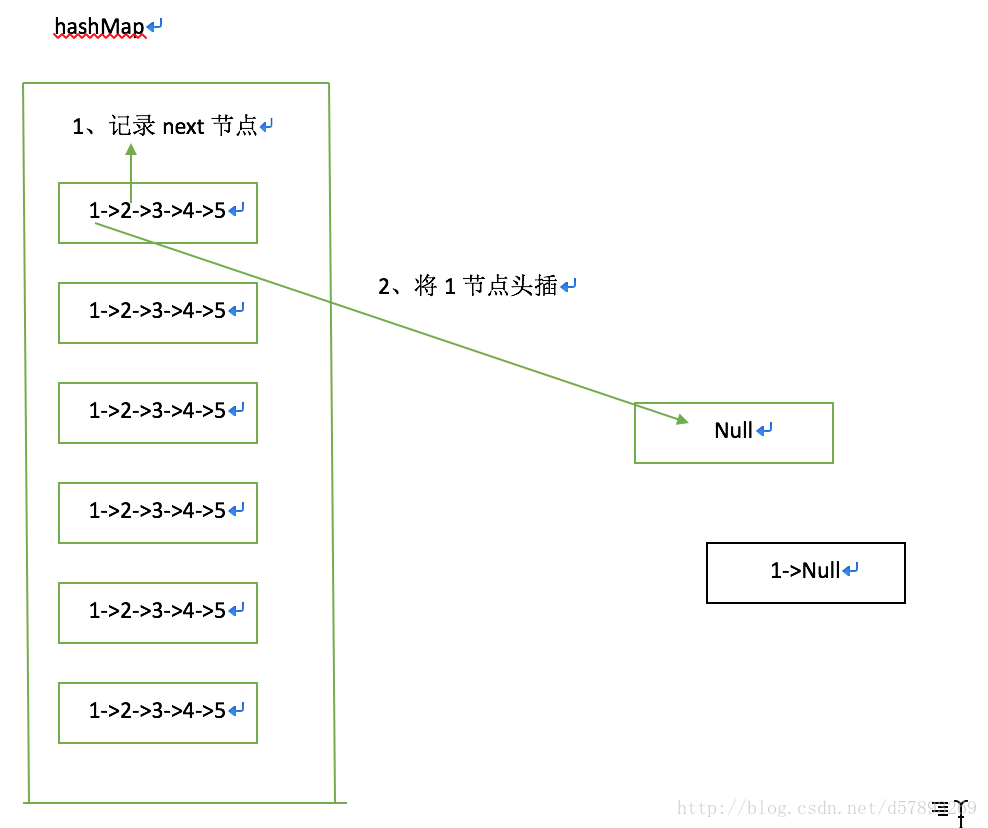
正常扩容过程
1、记录next节点
2、将当前节点头插进新数组
3、将老数组向下遍历
并发行程死循环:当一个线程1已经完成扩容,线程2扩容到2节点时
正常扩容步骤:1、线程2记录2的next。因为线程1已完成扩容,把链表倒置,2的next节点为1。
2、将2节点头插。新数组 2->1
3、将1赋值给当前节点。由此形成死循环
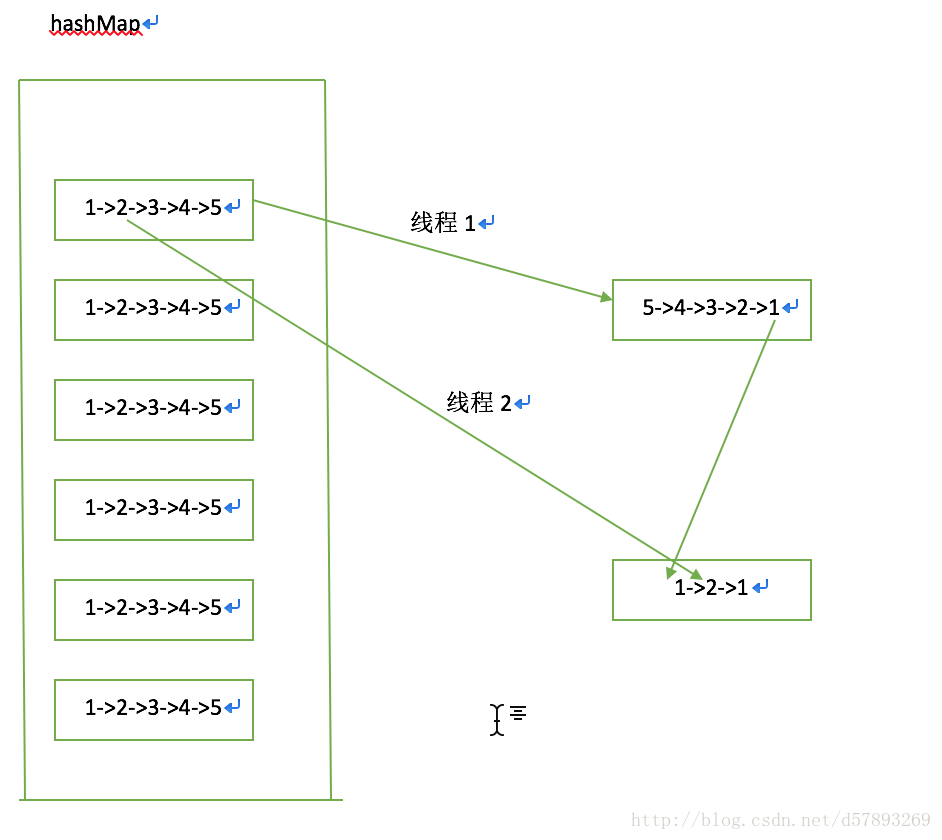
参考来自:http://ifeve.com/hashmap-infinite-loop/
初始化:赋值数组的长度16,和加载因子值0.75f,并没有生成数组。
// 提供四个初始化方法
public HashMap(int initialCapacity, float loadFactor)
public HashMap(int initialCapacity)
public HashMap()
public HashMap(Map map)
static final Entry<,>[] EMPTY_TABLE = {};
transient Entry<,>[] table = (Entry<,V>[]) EMPTY_TABLE; // 内部数组,初始化在第一次put时
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 静态数组长度
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 静态加载因子
int threshold; // 数组长度默认为16,在第一次put后变为12
final float loadFactor; // 加载因子0.75f
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
// 默认:initialCapacity=16 loadFactor=0.75
public HashMap(int initialCapacity, float loadFactor) {
// 是否小于0
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 是否大于最大值 1<<30 = 2^30
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor)
this.loadFactor = loadFactor;
threshold = initialCapacity;
// 模板方法,实际为null,留给子类实现空间
init();
}
// put操作数组为null时初始化 toSize 16
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
// 选取一个2的整数幂次数。 例如:15 —》16 17 —》32
int capacity = roundUpToPowerOf2(toSize);
// threshold = 12
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}get操作
public V get(Object key) {
// 取table[0]链表,对key==null的时候进行特殊处理,把entry放在0处
if (key == null)
return getForNullKey();
// key非空时
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
private V getForNullKey() {
// 边界控制,当数组长度为0时,返回null
if (size == 0) {
return null;
}
// 取出链表,循环取
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
// 计算hash值
int hash = (key == null) ? 0 : hash(key);
// 根据hash值和表长度与运算求出表位置
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
final int hash(Object k) {
int h = hashSeed;
// 对String类,进行特殊处理
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}put
public V put(K key, V value) {
// 数组初始化
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// key为null放在table[0]位置
if (key == null)
return putForNullKey(value);
// 计算key的hash值
int hash = hash(key);
// 通过与运算计算在表中的位置
int i = indexFor(hash, table.length);
// 判断在链表中是否存在,并不是添加到链表中。如果存在替换并返回老值
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// 1先比较hash值,2比较key值
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
// 模板模式,子类扩展
e.recordAccess(this);
return oldValue;
}
}
// modCount值加1,不能在迭代器中使用list.remove方法,会导致modCount值不一致,抛出异常
modCount++;
// 添加entry。1.链表存在,添加在头处 2.链表不存在,新建节点
addEntry(hash, key, value, i);
return null;
}
void addEntry(int hash, K key, V value, int bucketIndex) {
// 超出负载因子乘积就扩容2倍
if ((size >= threshold) && (null != table[bucketIndex])) {
// 重hash赋值
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 创建新entry
createEntry(hash, key, value, bucketIndex);
}1,初始化时都做了什么事,什么时候才创建数组?
初始化时默认设置了threshold为16和loadFactor为0.75f。
在第一次put的时候才真正的创建数组长度16,并赋值threshold为12。当实际存储的链表个数超过12时开始扩容。
2,加载因子的作用?
加载因子是hashMap时间和空间的比值。加载因子越大,扩容越慢,链表长度越长,查询慢。
加载因子越小,扩容越快,链表越短,查询快。
所以没有特殊要求还是使用默认值0.75较好。
2,为什么数组大小和扩容时要控制在2的整数倍?
// Find a power of 2 >= toSize 初始化时
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
// 扩容时
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
// 寻找在表中的位置
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}可以发现在初始化时必须要求是2的整数倍,扩容时也是扩容2倍,而不像ArrayList扩容时为1.5倍。
其原因在于数组长度为2的倍数时,散列会平均,效率变高 h & (length -1)会比去模效率高,length为奇数时,
length - 1末尾为0,h & 末尾为0的数时,最后一位永远是0,hash只能散列到偶数的位置,浪费空间。
3,hashMap插入时,是头插还是尾插?
头插。在插入的时候,新建了entry,把next结点指向头结点,如果是尾插的话,需要循环到尾位置,多操作。
同理可知,在扩容的时候会导致链表反转。
public V put(K key, V value) {
..
int hash = hash(key);
int i = indexFor(hash, table.length);
..
modCount++;
addEntry(hash, key, value, i);
return null;
}
void createEntry(int hash, K key, V value, int bucketIndex) {
// i位置的链表head
Entry<K,V> e = table[bucketIndex];
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
// hash key value e(i位置的链表head)
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n; // 把链表头结点赋给当前的next
key = k;
hash = h;
}4,hashMap多线程使用时发生死循环,为什么?
可通过源码分析。
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
// 1、记录next节点
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 2、当前节点头插到新数组
e.next = newTable[i];
newTable[i] = e;
// 3、将老数组向下遍历
e = next;
}
}
}正常扩容过程
1、记录next节点
2、将当前节点头插进新数组
3、将老数组向下遍历
并发行程死循环:当一个线程1已经完成扩容,线程2扩容到2节点时
正常扩容步骤:1、线程2记录2的next。因为线程1已完成扩容,把链表倒置,2的next节点为1。
2、将2节点头插。新数组 2->1
3、将1赋值给当前节点。由此形成死循环
参考来自:http://ifeve.com/hashmap-infinite-loop/

相关文章推荐
- HashMap源码分析
- HashMap源码分析
- Hash算法以及java hashmap的源码分析
- Java HashMap 源码分析
- HashMap源码分析(基于JDK1.6)
- java util包学习(9)HashMap源码分析
- 源码分析:HashMap
- Java concurrent Framework并发容器之ConcurrentHashMap(JDK1.5)源码分析
- 源码分析:HashMap
- Java Collections Framework之HashMap源码分析(基于JDK1.6)
- Thinking in Java之HashMap源码分析
- HashSet和HashMap源码实现分析
- 【转载】HashSet与HashMap关系之源码分析
- HashMap 源码分析
- HashMap源码分析
- HashMap源码分析
- 集合框架源码分析三(实现类篇ArrayList,LinkedList,HashMap)
- java源码分析之LinkedHashMap
- Java HashMap源码分析
- Java concurrent Framework并发容器之ConcurrentHashMap(Doug Lea 非JDK版)源码分析