Spark算子执行流程详解之八
2017-03-02 12:18
579 查看
36.zip
将2个rdd相同位置的元素组成KV对/**
* Zips this RDD with another one, returning key-value pairs with the first element in each RDD,
* second element in each RDD, etc. Assumes that the two RDDs have the *same number of
* partitions* and the *same number of elements in each partition* (e.g. one was made through
* a map on the other).
*/
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)] = withScope {
zipPartitions(other, preservesPartitioning = false) {//如果2个迭代器都有值,则输出,如果没值,则不输出,并且两个迭代器的长度必须保持一致 (thisIter, otherIter) =>
new Iterator[(T, U)] {
def hasNext: Boolean = (thisIter.hasNext, otherIter.hasNext) match {
case (true, true) => true
case (false, false) => false
case _ => throw new SparkException("Can only zip RDDs with " +
"same number of elements in each partition")
}
def next(): (T, U) = (thisIter.next(), otherIter.next())
}
}} |
def zipPartitions[B: ClassTag, V: ClassTag]
(rdd2: RDD, preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B]) => Iterator[V]): RDD[V] = withScope {
[b]new ZippedPartitionsRDD2(sc, sc.clean(f), this, rdd2, preservesPartitioning)} private[spark] class ZippedPartitionsRDD2[A: ClassTag, B: ClassTag, V: ClassTag](
sc: SparkContext,
var f: (Iterator[A], Iterator) => Iterator[V],
[b]var rdd1: RDD[A],
var rdd2: RDD,
preservesPartitioning: Boolean = [b]false)
extends ZippedPartitionsBaseRDD[V](sc, List(rdd1, rdd2), preservesPartitioning) {
//compute就是利用zip时候生成的迭代器,重写其hasNext和next方法来返回数据
override def compute(s: Partition, context: TaskContext): Iterator[V] = {
val partitions = s.asInstanceOf[ZippedPartitionsPartition].partitions
f(rdd1.iterator(partitions(0), context), rdd2.iterator(partitions(1), context))
}
override def clearDependencies() {
super.clearDependencies()
rdd1 = null
rdd2 = null
f = null
}
} |
private[spark] abstract class ZippedPartitionsBaseRDD[V: ClassTag](
sc: SparkContext,
var rdds: Seq[RDD[_]],
preservesPartitioning: Boolean = false)
extends RDD[V](sc, rdds.map(x => new OneToOneDependency(x))) {
//由于zip默认的preservesPartitioning为false,则zip之后partitioner为None
override val partitioner =
if (preservesPartitioning) firstParent[Any].partitioner else None
override def getPartitions: Array[Partition] = {
val numParts = rdds.head.partitions.length//zip的左右两RDD的分区个数必须保持一致
if (!rdds.forall(rdd => rdd.partitions.length == numParts)) {
throw new IllegalArgumentException("Can't zip RDDs with unequal numbers of partitions")
}
Array.tabulate[Partition](numParts) { i =>//获取每个分区的loc信息 val prefs = rdds.map(rdd => rdd.preferredLocations(rdd.partitions(i))) // Check whether there are any hosts that match all RDDs; otherwise return the union //求loc的交集 val exactMatchLocations = prefs.reduce((x, y) => x.intersect(y)) //如果交集非空,则其交集为zip之后的loc,如果交集为空,则取两者的非重合的loc
val locs = if (!exactMatchLocations.isEmpty) exactMatchLocations else prefs.flatten.distinct
new ZippedPartitionsPartition(i, rdds, locs)
}
}
override def getPreferredLocations(s: Partition): Seq[String] = {
s.asInstanceOf[ZippedPartitionsPartition].preferredLocations
}
override def clearDependencies() {
super.clearDependencies()
rdds = null
}} |

37.zipPartitions
zipPartition有多个变种,列举如下:def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag]
(rdd2: RDD, rdd3: RDD[C], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] = withScope {
[b]new ZippedPartitionsRDD3(sc, sc.clean(f), this, rdd2, rdd3, preservesPartitioning)
}
def zipPartitions[B: ClassTag, C: ClassTag, V: ClassTag]
(rdd2: RDD, rdd3: RDD[C])
(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V]): RDD[V] = withScope {
zipPartitions(rdd2, rdd3, preservesPartitioning = [b]false)(f)
}
def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag]
(rdd2: RDD, rdd3: RDD[C], rdd4: RDD[D], preservesPartitioning: Boolean)
(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V] = withScope {
[b]new ZippedPartitionsRDD4(sc, sc.clean(f), this, rdd2, rdd3, rdd4, preservesPartitioning)
}
def zipPartitions[B: ClassTag, C: ClassTag, D: ClassTag, V: ClassTag]
(rdd2: RDD, rdd3: RDD[C], rdd4: RDD[D])
(f: (Iterator[T], Iterator[B], Iterator[C], Iterator[D]) => Iterator[V]): RDD[V] = withScope {
zipPartitions(rdd2, rdd3, rdd4, preservesPartitioning = [b]false)(f)
} |
38.zipWithIndex
该函数将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对。def zipWithIndex(): RDD[(T, Long)] = withScope {
new ZippedWithIndexRDD(this)} |
class ZippedWithIndexRDD[T: ClassTag](@transient prev: RDD[T]) extends RDD[(T, Long)](prev) {
/** The start index of each partition. */
@transient private val startIndices: Array[Long] = {
val n = prev.partitions.length
if (n == 0) {
Array[Long]()
} else if (n == 1) {
Array(0L)
} else {//先计算出每个分区的起始偏移量,例如假设有4个分区,每个分区依次包含3,4,3个元素,则startIndices为:[0,3,7]
prev.context.runJob(
prev,
Utils.getIteratorSize _,
0 until n - 1, // do not need to count the last partition
allowLocal = false
).scanLeft(0L)(_ + _)
}
}
override def getPartitions: Array[Partition] = {//组装分区的配置信息,即该分区的对应起始偏移量为startIndices(x.index)
firstParent[T].partitions.map(x => new ZippedWithIndexRDDPartition(x, startIndices(x.index)))
}
override def getPreferredLocations(split: Partition): Seq[String] =
firstParent[T].preferredLocations(split.asInstanceOf[ZippedWithIndexRDDPartition].prev)
override def compute(splitIn: Partition, context: TaskContext): Iterator[(T, Long)] = {
val split = splitIn.asInstanceOf[ZippedWithIndexRDDPartition]//通过zipWithIndex计算每个元素在自己分区内的相对偏移量,然后叠加split.startIndex计算在整个RDD中的绝对偏移量
firstParent[T].iterator(split.prev, context).zipWithIndex.map { x =>
(x._1, split.startIndex + x._2)
}
}
} |
scala> var rdd2 = sc.makeRDD(Seq("A","B","R","D","F"),2)rdd2: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[34] at makeRDD at :21 scala> rdd2.zipWithIndex().collect res27: Array[(String, Long)] = Array((A,0), (B,1), (R,2), (D,3), (F,4)) |

39.zipWithUniqueId
该函数将RDD中元素和一个唯一ID组合成键/值对,该唯一ID生成算法如下:每个分区中第一个元素的唯一ID值为:该分区索引号,
每个分区中第N个元素的唯一ID值为:(前一个元素的唯一ID值) + (该RDD总的分区数)
/**
* Zips this RDD with generated unique Long ids. Items in the kth partition will get ids k, n+k,
* 2*n+k, ..., where n is the number of partitions. So there may exist gaps, but this method
* won't trigger a spark job, which is different from [[org.apache.spark.rdd.RDD#zipWithIndex]].
*
* Note that some RDDs, such as those returned by groupBy(), do not guarantee order of
* elements in a partition. The unique ID assigned to each element is therefore not guaranteed,
* and may even change if the RDD is reevaluated. If a fixed ordering is required to guarantee
* the same index assignments, you should sort the RDD with sortByKey() or save it to a file.
*/
def zipWithUniqueId(): RDD[(T, Long)] = withScope {
val n = this.partitions.length.toLong//k为分区索引
this.mapPartitionsWithIndex { case (k, iter) =>//i为每个分区元素在自己分区的索引
iter.zipWithIndex.map { case (item, i) =>//i*n+k:基准值为该分区的索引,每次增加分区数目*每个分区元素在自己分区的索引的距离 (item, i * n + k) } } } |
scala> var rdd1 = sc.makeRDD(Seq("A","B","C","D","E","F"),2)rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[44] at makeRDD at :21 //rdd1有两个分区, scala> rdd1.zipWithUniqueId().collect res32: Array[(String, Long)] = Array((A,0), (B,2), (C,4), (D,1), (E,3), (F,5)) |

40.foreach
针对rdd的每个元素利用f进行处理/**
* Applies a function f to all elements of this RDD.
*/
def foreach(f: T => Unit): Unit = withScope {
val cleanF = sc.clean(f)
sc.runJob(this, (iter: Iterator[T]) => iter.foreach(cleanF))
} |
其次要注意,如果对RDD执行foreach,只会在Executor端有效,而并不是Driver端。
比如:rdd.foreach(println),只会在Executor的stdout中打印出来,Driver端是看不到的。
通过accumulator共享变量与foreach结合,可以统计rdd里面的数值
| scala> var cnt = sc.accumulator(0) cnt: org.apache.spark.Accumulator[Int] = 0 scala> var rdd1 = sc.makeRDD(1 to 10,2) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at makeRDD at :21 scala> rdd1.foreach(x => cnt += x) scala> cnt.value res51: Int = 55 |
41.foreachPartition
foreachPartition和foreach一样,针对每个分区,它们的区别类似于map和mappartitions操作| /* * Applies a function f to each partition of this RDD. */ def foreachPartition(f: Iterator[T] => Unit): Unit = withScope { val cleanF = sc.clean(f) sc.runJob(this, (iter: Iterator[T]) => cleanF(iter)) } |
42.subtract
将存在于本RDD中的记录从other RDD中抹去,返回本RDD中剩余的记录
/*
* Return an RDD with the elements from `this` that are not in `other`.
*
* Uses `this` partitioner/partition size, because even if `other` is huge, the resulting
* RDD will be <= us.
*/
def subtract(other: RDD[T]): RDD[T] = withScope {//既然要相减,那么就必须知道this rdd的分布情况,即其分区函数 subtract(other, partitioner.getOrElse(new HashPartitioner(partitions.length))) } |
继续往下看:
/**
* Return an RDD with the elements from `this` that are not in `other`.
*/
def subtract(
other: RDD[T],
p: Partitioner)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
if (partitioner == Some(p)) {//结果RDD的分区函数和本rdd相同,则重新生成一个p2,由于这个p2没有定义equals函数,则意味着任何与其比较其实就是比较类地址,这样就会导致接下去两个rdd都会存在shuffle的动作,至于为什么这样设计,没怎么想明白
// Our partitioner knows how to handle T (which, since we have a partitioner, is
// really (K, V)) so make a new Partitioner that will de-tuple our fake tuples
val p2 = new Partitioner() {
override def numPartitions: Int = p.numPartitions
override def getPartition(k: Any): Int = p.getPartition(k.asInstanceOf[(Any, _)]._1)
}
// Unfortunately, since we're making a new p2, we'll get ShuffleDependencies
// anyway, and when calling .keys, will not have a partitioner set, even though
// the SubtractedRDD will, thanks to p2's de-tupled partitioning, already be
// partitioned by the right/real keys (e.g. p).
this.map(x => (x, null)).subtractByKey(other.map((_, null)), p2).keys
} else {//如果不相等,则采用默认的hash分区 this.map(x => (x, null)).subtractByKey(other.map((_, null)), p).keys } } |
主要是将本RDD和other rdd转化为KV对,其中V为null,然后调用subtractByKey函数,且看subtractByKey的实现:
/** Return an RDD with the pairs from `this` whose keys are not in `other`. */
def subtractByKey[W: ClassTag](other: RDD[(K, W)], p: Partitioner): RDD[(K, V)] = self.withScope {
new SubtractedRDD[K, V, W](self, other, p)} |
返回一个SubtractedRDD,继续往下看:
private[spark] class SubtractedRDD[K: ClassTag, V: ClassTag, W: ClassTag](
@transient var rdd1: RDD[_ <: Product2[K, V]],
@transient var rdd2: RDD[_ <: Product2[K, W]],
part: Partitioner)
extends RDD[(K, V)](rdd1.context, Nil) {
private var serializer: Option[Serializer] = None
/** Set a serializer for this RDD's shuffle, or null to use the default (spark.serializer) */
def setSerializer(serializer: Serializer): SubtractedRDD[K, V, W] = {
this.serializer = Option(serializer)
this
}
override def getDependencies: Seq[Dependency[_]] = {//根据分区函数获取结果RDD和rdd1,rdd2的依赖关系
Seq(rdd1, rdd2).map { rdd =>
if (rdd.partitioner == Some(part)) {
logDebug("Adding one-to-one dependency with " + rdd)
new OneToOneDependency(rdd)
} else {
logDebug("Adding shuffle dependency with " + rdd)
new ShuffleDependency(rdd, part, serializer)
}
}
}
override def getPartitions: Array[Partition] = {
val array = new Array[Partition](part.numPartitions)
for (i <- 0 until array.length) {
// Each CoGroupPartition will depend on rdd1 and rdd2
array(i) = new CoGroupPartition(i, Seq(rdd1, rdd2).zipWithIndex.map { case (rdd, j) =>
dependencies(j) match {
case s: ShuffleDependency[_, _, _] =>
None
case _ =>
Some(new NarrowCoGroupSplitDep(rdd, i, rdd.partitions(i)))
}
}.toArray)
}
array
}
override val partitioner = Some(part)
override def compute(p: Partition, context: TaskContext): Iterator[(K, V)] = {
val partition = p.asInstanceOf[CoGroupPartition]//保存相同的KEY的VALUE
val map = new JHashMap[K, ArrayBuffer[V]]
def getSeq(k: K): ArrayBuffer[V] = {
val seq = map.get(k)
if (seq != null) {
seq
} else {
val seq = new ArrayBuffer[V]()
map.put(k, seq)
seq
}
}
def integrate(depNum: Int, op: Product2[K, V] => Unit) = {
dependencies(depNum) match {//如果是窄依赖,则直接读取父RDD的数据 case oneToOneDependency: OneToOneDependency[_] => val dependencyPartition = partition.narrowDeps(depNum).get.split oneToOneDependency.rdd.iterator(dependencyPartition, context) .asInstanceOf[Iterator[Product2[K, V]]].foreach(op) //如果是宽依赖,则直接其对应的shuffle中间数据 case shuffleDependency: ShuffleDependency[_, _, _] => val iter = SparkEnv.get.shuffleManager .getReader( shuffleDependency.shuffleHandle, partition.index, partition.index + 1, context) .read() iter.foreach(op) } } // the first dep is rdd1; add all values to the map //先将本RDD的KV对缓存至内存 integrate(0, t => getSeq(t._1) += t._2) // the second dep is rdd2; remove all of its keys //然后遍历other Rdd的对应shuffle分区数据,去除掉相同的key的值
integrate(1, t => map.remove(t._1))
//将(k,Seq(v))转化成(k,v)列表
map.iterator.map { t => t._2.iterator.map { (t._1, _) } }.flatten
}} |
从实现可以看出subtractByKey用于rdd1比rdd2少很多的情况,因为rdd1是存在内存,rdd2只要遍历stream即可。如果rdd1很大,且reduce数较少的情况可能发生OOM。如果rdd1很大可以考虑使用cogroup来实现。Subtract的具体执行流程如下:
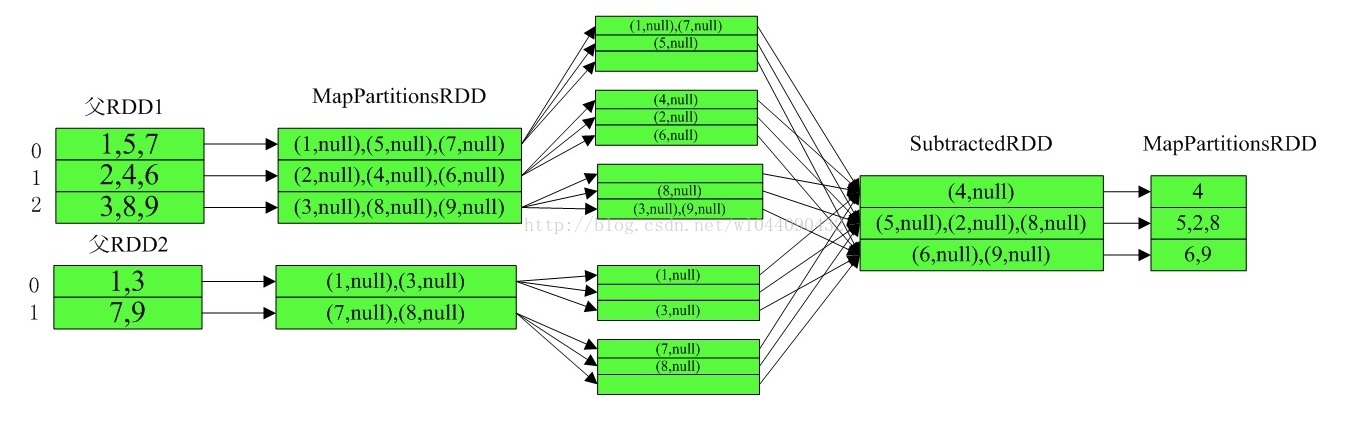
43.keyBy
利用函数f生成KV对
/**
* Creates tuples of the elements in this RDD by applying `f`.
*/
def keyBy[K](f: T => K): RDD[(K, T)] = withScope {
val cleanedF = sc.clean(f)//利用map操作生成KV对 map(x => (cleanedF(x), x)) } |
实例如下:
List<Integer> data = Arrays.asList(1,4,3,2,5,6);
JavaRDD<Integer> JavaRDD = jsc.parallelize(data, 2);
JavaPairRDD<Integer,Integer> pairRDD = JavaRDD.keyBy(new Function<Integer, Integer>() {
@Override
public Integer call(Integer v1) throws Exception {
return v1;
}
});
for(Tuple2<Integer,Integer> tuple2:pairRDD.collect()){
System.out.println(tuple2._1()+" "+tuple2._2());
}打印如下: 1 1 4 4 3 3 2 2 5 5 6 6 |
其执行流程如下:
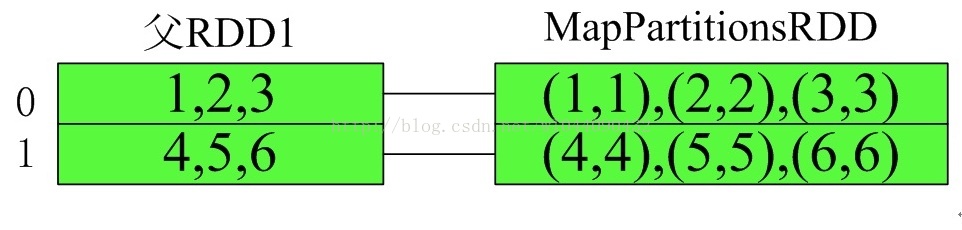

相关文章推荐
- Spark算子执行流程详解之二
- Spark算子执行流程详解之四
- Spark算子执行流程详解之一
- Spark算子执行流程详解之三
- Spark算子执行流程详解之六
- Spark算子执行流程详解之五
- Spark算子执行流程详解之七
- MapReduce执行流程详解
- 转 alsa录音放音执行流程详解
- 详解Magento执行流程
- 【Spark】RDD操作详解4——Action算子
- Android编译系统详解(二)——命令执行流程
- Spark SQL深度理解篇:模块实现、代码结构及执行流程总览
- .net/c#中栈和堆的区别及代码在栈和堆中的执行流程详解
- Spark学习之15:Spark Streaming执行流程(1)
- Spark学习之16:Spark Streaming执行流程(2)
- Spark Streaming 执行流程
- 转 alsa录音放音执行流程详解
- Java try catch finally 虚拟机执行流程详解
- .net/c#中栈和堆的区别及代码在栈和堆中的执行流程详解之一