数据预处理及相应的Rapidminer操作
2017-03-01 19:38
337 查看
数据预处理
数据挖掘中主要用于数据预处理的方法有以下几种:1. 聚集(Aggregation)
2. 抽样(Sampling)
3. 维归约(DimensionalityReduction)
4. 特征子集选择(Feature subset selection)
5. 特征创建(Feature creation)
6. 离散化(Discretization)和二元化(Binarization)
7. 属性变换
练习时测试用的测试数据集可以在【Repository>>Samples>>data】中获取示例数据集;
聚集(Aggregation)
聚集是指将两个或多个对象合并成单个对象;聚集的目的
– 减少数据
· 减少属性或数据对象的个数
· 节省数据挖掘算法的运行时间和空间
– 尺度提升
· 城市聚集成区域、省、国家,等等
· 产生新的模式
– 更“稳定”的数据
· 聚集的数据会有较小的变异性
· 突出数据的趋势和轨迹
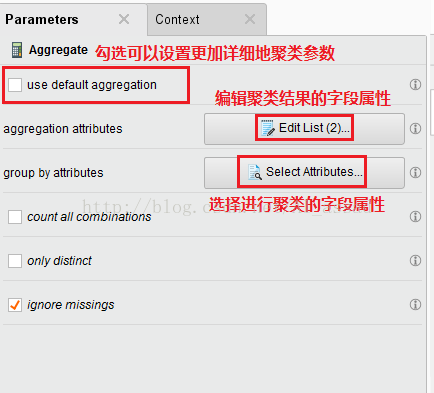
聚集方法在Rapidminer中的实现:
Rapidminer中聚集对应的算子是 【Aggregate】;
>>基本流程
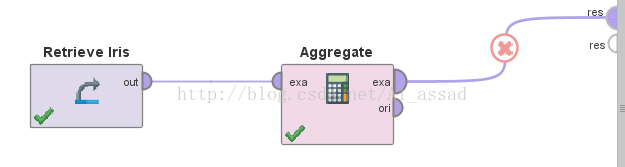
>>参数面板
抽样(Sampling)
抽样是指选择数据对象子集,抽取的对象称作样本;抽样的目的
降低数据处理的费用和时间;
随机抽样方式
· 无放回抽样:被选中的对象从待选对象集中删除;
· 有放回抽样:被选中的项不从待选对象集中删除,相同的对象可能被多次抽出;
随机抽样方法
· 简单随机抽样:选取任何对象的概率相等;
· 分层抽样:划分待选对象集为多个子集,分别从各个子集随机抽样(一般根据类标号划分子集),有以下2种方式:
- 每组大小不同,但从每组抽取的对象个数相同;
- 抽取的对象个数正比于组的大小;
抽样方法在Rapidminer中的实现
1)简单随机抽样(不放回) -> 【Sample】
>>基本流程
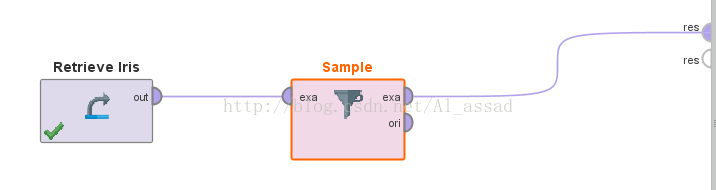
>>参数面板
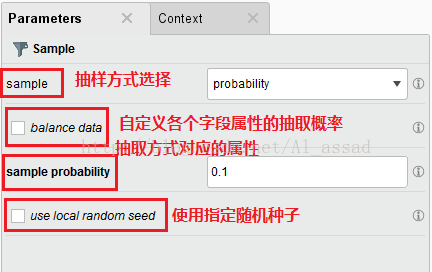
几个Sample可选的区别:
absolute:按照指定样本容量进行抽样;
relative:按照指定样本抽取的比例进行抽取;
probablity:按照指定抽取比例,抽取接近该比例的样本,可以通过更改随机种子来修改这个随机值;
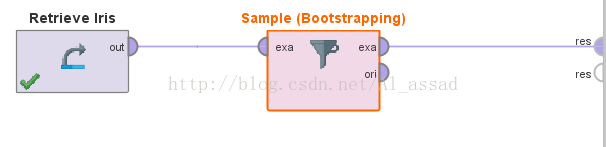
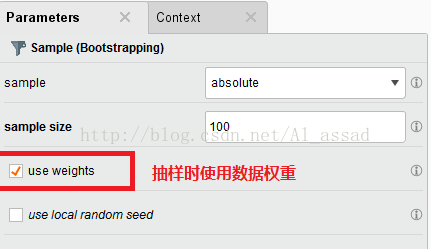
2)简单随机抽样(放回)-> 【Sample(Bootstrapping)】
这种抽样方法主要用于扩充样本容量,设置的抽取数量可以大于原数据集容量
>>基本流程
>>参数面板
3)随机分层抽样 -> 【Sample(Stratified)】
维归约(DimensionalityReduction)
维归约是指降低数据的维度,即减少数据属性的个数
维归约的目的
· 避免维灾难 (curse of dimensionality);
· 降低数据挖掘算法的时间和内存需求;
· 使数据更容易可视化;
· 可以删除不相关的属性并降低噪声;
维归约的常用方法——主成份分析(PCA)
目标是找出新的属性(主成分)
– 原属性的线性组合
– 相互正交
– 捕获数据的最大变差
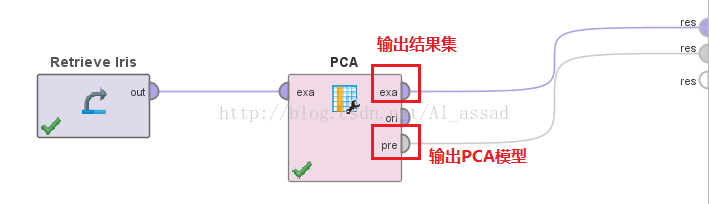
在Rapidminer中的实现
主成分分析PCA -> 【Principal Component Analysis】
>>基本流程
>>参数面板
dimensionality reduction 降维参数的几个可选值(主要用于删除异常点):
none:保持原来的数据集规模;
keep_variance:删除原数据集中积累方差大于指定的阈值的记录;
fixed_number:输出的结果集保持在指定的数据容量;
特征子集选择(Feature subset selection)
特征子集选择是指选择一部分属性实施数据挖掘任务;
特征子集选择的目的
消除冗余特征和不相关特征
· 冗余特征
– 重复了包含在一个或多个其他属性中的许多信息
– 例子:产品的购买价格和所支付的销售税额
· 不相关特征
– 仅含有对于当前数据挖掘任务几乎无用的信息
– 例子:学生的ID号码对于预测学生的总平均成绩是不相关的
特征选择的常见方式和方法
1)嵌入方式 – 特征选择作为数据挖掘算法的一部分自然地出现(如构造决策树的算法)
2)过滤方式 – 在数据挖掘算法运行前进行特征选择
3)包装方式
• 穷举方法 – 尝试所有可能的特征子集,然后选取产生最好结果的子集
• 前向/后向选择方法
– 前:从空集开始逐步添加特征,选取产生最好结果的子集
– 后:从全集开始逐步删除特征,选取产生最好结果的子集
※一般使用包装方法时,不会使用穷尽方法,而是使用向前/向后选择方法;
在Rapidminner中的实现
1)手动设置特征选择参数 -> 【Select Attributes】
>>基本流程
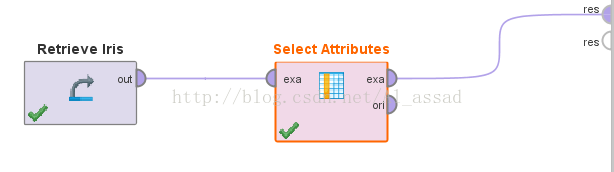
>>参数面板
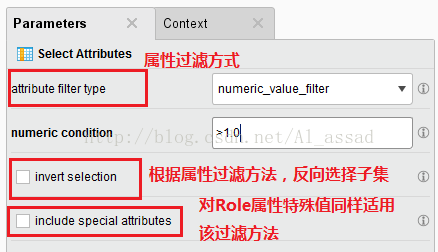
常用的attribute filter type:
subset:选择属性子集;
regular_expression:对所有属性使用正则表达式过滤(主要用于字符串特征处理);
numeric_value_filter:对所有numeric类型数据使用指定规则进行过滤(主要用于序数、区间、比率类型进行处理);
value_type:对所有子集进行数据类型过滤;
2)向前/向后选择方法 -> 【Optimize Select】
>>基本流程

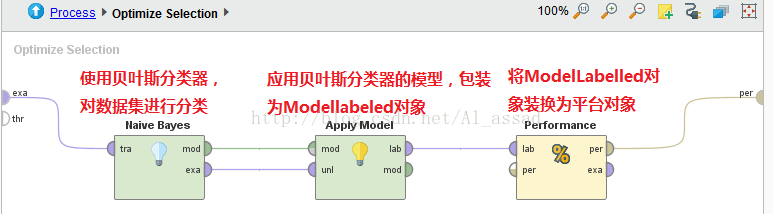
3)穷举方法 ->【Optimize Select(Brute Force)】
方式基本同向前/向后选择方法;
特征创建(Feature
creation)
特征创建是指由原来的属性创建新的属性集
特征创建的目的
– 更有效地捕获数据集中的重要信息
– 消除噪声的影响
– 新属性个数比原来的属性个数少,可以取得降维的所有好处
三种创建新属性的方法
– 特征提取:依赖于特定领域,比如人脸识别
– 映射数据到新空间:如傅立叶变换(Fourier transform)
– 特征构造:如密度=质量/体积
在Rapidminer中的实现
创建新的特征属性:【Generate Attribute】
傅里叶变换:【Fourier transition】
离散化(Discretization)和二元化(Binarization)
离散化是指将连续属性转变成离散属性
离散化目的
– 使数据能运用于不能处理连续属性的数据挖掘算法(主要目的)
– 降低离群点/异常点的影响
二元化
– 离散化的一种特例
– 将连续属性转变成二元属性
离散化方法
①监督(supervised)方法 ——使用类标
– 基于熵(entropy)的方法:找产生最小总熵的分界点
– 熵(物理):事物内部元素分布的均匀程度;元素分布越均匀,熵越高
– 熵(信息):数值区间内类分布的均匀程度;类分布越均匀,熵越高
– 总熵是分区熵的加权平均
②非监督(unsupervised)方法——不使用类标
等宽离散化
等频离散化 :在K均值离散化不起作用时使用;
K均值离散化 :一般使用;
在Rapidminer中的实现
离散化监督方法:【Discretive by Entropy】
等宽离散化:【DIscretive by Binning】
等频离散化:【Discretive by Frequency】
属性/变量变换
• 变量变换是指变换变量的所有取值
– 简单函数: xk, log(x), ex, |x|
– 标准化或规范化
• 例子:将一个变量标准化成一个具有均值0和标准差1的新变 x’=(x-mean(x))/std(x)
变量变换的目的
– 将数据转换成特定分布(如正态分布)的数据
– 压缩数据
– 相似度/相异度计算时统一属性的尺度
在Rapidminer中的实现
属性变换:【Normailze】
常用method参数列表:
z-transformation 标准化转换
range transformation 值域转化(常用于压缩属性);

相关文章推荐
- 【数据挖掘】数据预处理与Rapidminer相应的操作
- matlab 数据预处理及常用操作
- iOS中加载HTML数据,并点击图片或链接进行相应的操作
- 【炼数成金 RapidMiner 二 】数据导入、预处理、导出
- iOS中加载HTML数据,并点击图片或链接进行相应的操作
- Map排序,获取map的第一值,根据value取key等操作(数据预处理)
- 执行相应操作后,将表单及table中数据清空
- 配置文件操作(获取路径、及取得相应数据)
- 分析运维数据的一些预处理操作
- Python数据分析模块 | pandas做数据分析(二):常用预处理操作
- 以MyBatis+SpringMVC3.0实现的,借鉴了Hibernate设计思想,采用封装、抽象、继承的设计思想,做到了数据与相应的操作的高内聚低耦合的实现
- 常用的数据预处理操作
- php数据库操作--数据预处理、更新、删除
- pandas做数据分析(三):常用预处理操作
- .net下操作Excel数据的几种方法
- Oracle数据操作和控制语言详解 (一)
- lotus中操作excel--引入excel数据至notes中
- SQL数据的基本操作(时间和日期)
- 操作数据:SQL
- 使用ASP.NET页面创建可视的UI,在客户机上实例化MSXML分析器的页面从中间层组件取出XML数据、操作并显示 并有问题请高手解决