5亿整数的大文件,怎么排?
2017-02-17 16:19
134 查看
原文出处: foreach_break
给你1个文件
现在要对这个文件进行排序,怎么搞?
先尝试内排,选2种排序方式:
数据太多,递归太深 ->栈溢出?加大Xss?
数据太多,数组太长 -> OOM?加大Xmx?
耐心不足,没跑出来.而且要将这么大的文件读入内存,在堆中维护这么大个数据量,还有内排中不断的拷贝,对栈和堆都是很大的压力,不具备通用性。
跑了多久呢?24分钟.
为什么这么慢?
粗略的看下我们的资源:
内存
jvm-heap/stack,native-heap/stack,page-cache,block-buffer
外存
swap + 磁盘
数据量很大,函数调用很多,系统调用很多,内核/用户缓冲区拷贝很多,脏页回写很多,io-wait很高,io很繁忙,堆栈数据不断交换至swap,线程切换很多,每个环节的锁也很多.
总之,内存吃紧,问磁盘要空间,脏数据持久化过多导致cache频繁失效,引发大量回写,回写线程高,导致cpu大量时间用于上下文切换,一切,都很糟糕,所以24分钟不细看了,无法忍受.
nice!跑了190秒,3分来钟.
以核心内存
问题是,如果这个时候突然内存条坏了1、2根,或者只有极少的内存空间怎么搞?
该外部排序上场了.
外部排序干嘛的?
内存极少的情况下,利用分治策略,利用外存保存中间结果,再用多路归并来排序;
map-reduce的嫡系.
内存中维护一个极小的核心缓冲区
循环利用
现在有了n个有序的小文件,怎么合并成1个有序的大文件?
把所有小文件读入内存,然后内排?
(⊙o⊙)…
no!
利用如下原理进行归并排序:

我们举个简单的例子:
文件1:3,6,9
文件2:2,4,8
文件3:1,5,7
第一回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:1,排在文件3的第1行
那么,这3个文件中的最小值是:min(1,2,3) = 1
也就是说,最终大文件的当前最小值,是文件1、2、3的当前最小值的最小值,绕么?
上面拿出了最小值1,写入大文件.
第二回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:5,排在文件3的第2行
那么,这3个文件中的最小值是:min(5,2,3) = 2
将2写入大文件.
也就是说,最小值属于哪个文件,那么就从哪个文件当中取下一行数据.(因为小文件内部有序,下一行数据代表了它当前的最小值)
最终的时间,跑了771秒,13分钟左右.
问题
给你1个文件bigdata,大小4663M,5亿个数,文件中的数据随机,如下一行一个整数:
内部排序
先尝试内排,选2种排序方式:
3路快排:
归并排序:
数据太多,数组太长 -> OOM?加大Xmx?
耐心不足,没跑出来.而且要将这么大的文件读入内存,在堆中维护这么大个数据量,还有内排中不断的拷贝,对栈和堆都是很大的压力,不具备通用性。
sort命令来跑
为什么这么慢?
粗略的看下我们的资源:
内存
jvm-heap/stack,native-heap/stack,page-cache,block-buffer
外存
swap + 磁盘
数据量很大,函数调用很多,系统调用很多,内核/用户缓冲区拷贝很多,脏页回写很多,io-wait很高,io很繁忙,堆栈数据不断交换至swap,线程切换很多,每个环节的锁也很多.
总之,内存吃紧,问磁盘要空间,脏数据持久化过多导致cache频繁失效,引发大量回写,回写线程高,导致cpu大量时间用于上下文切换,一切,都很糟糕,所以24分钟不细看了,无法忍受.
位图法
以核心内存
4663M/32大小的空间跑出这么个结果,而且大量时间在用于I/O,不错.
问题是,如果这个时候突然内存条坏了1、2根,或者只有极少的内存空间怎么搞?
外部排序
该外部排序上场了.外部排序干嘛的?
内存极少的情况下,利用分治策略,利用外存保存中间结果,再用多路归并来排序;
map-reduce的嫡系.
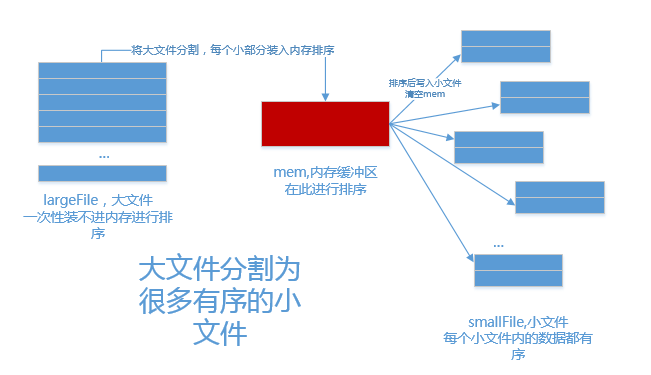
1.分
内存中维护一个极小的核心缓冲区memBuffer,将大文件
bigdata按行读入,搜集到
memBuffer满或者大文件读完时,对
memBuffer中的数据调用内排进行排序,排序后将有序结果写入磁盘文件
bigdata.xxx.part.sorted.
循环利用
memBuffer直到大文件处理完毕,得到n个有序的磁盘文件:
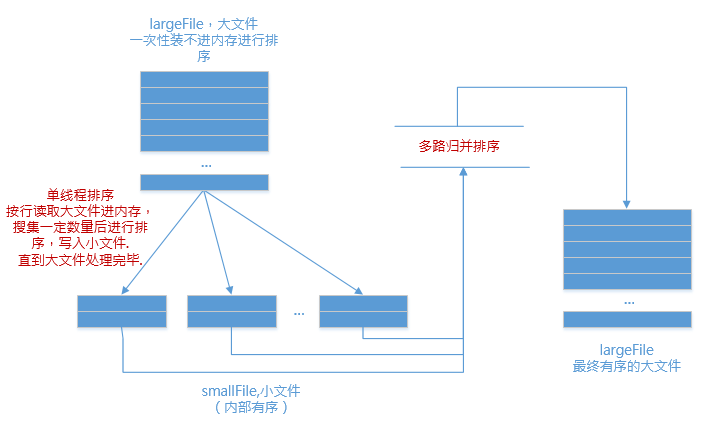
2.合
现在有了n个有序的小文件,怎么合并成1个有序的大文件?把所有小文件读入内存,然后内排?
(⊙o⊙)…
no!
利用如下原理进行归并排序:
我们举个简单的例子:
文件1:3,6,9
文件2:2,4,8
文件3:1,5,7
第一回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:1,排在文件3的第1行
那么,这3个文件中的最小值是:min(1,2,3) = 1
也就是说,最终大文件的当前最小值,是文件1、2、3的当前最小值的最小值,绕么?
上面拿出了最小值1,写入大文件.
第二回合:
文件1的最小值:3 , 排在文件1的第1行
文件2的最小值:2,排在文件2的第1行
文件3的最小值:5,排在文件3的第2行
那么,这3个文件中的最小值是:min(5,2,3) = 2
将2写入大文件.
也就是说,最小值属于哪个文件,那么就从哪个文件当中取下一行数据.(因为小文件内部有序,下一行数据代表了它当前的最小值)
最终的时间,跑了771秒,13分钟左右.

相关文章推荐
- 大文件,5亿整数,怎么排?
- 5亿整数的大文件,怎么排?
- 5亿整数的大文件,怎么排?
- 5亿整数的大文件,怎么排?
- 大文件,5亿整数,怎么排?
- 5亿整数的大文件,怎么排?
- 大文件,5亿整数,怎么排?
- 5亿整数的大文件,怎么排序?
- 5 亿整数的大文件,怎么排
- FAQ200412:怎么在一个静态Picture控件中显示JPG文件
- 怎么取得DLL文件中的函数名列表?
- 打开程序时提示缺少某个库文件是怎么办?grep给你简便方法!!!
- 包含DataSet类的XML架构怎么不自动生成CS文件了?(Fix一个小问题)
- 2.0配置文件中的<connectionStrings>怎么用?
- 怎么给这个xml文件建立对象,以便使对象和xml文件序列化和反序列化
- 用commons-net ftpclient 怎么判断服务器是否存在文件A??
- SQL数据库日志文件已满,怎么删除
- 词霸怎么在pdf 文件里取词?
- 怎么在html中include一个文件内容
- 新手求助2---怎么在cnblogs里插入下载文件 的链接?如何 插入自动播放的 flash 或者 背景音乐?