R语言 时间序列ARIMA模型方法
2017-02-17 14:17
1096 查看
原理什么的百度一搜一堆,看不明白,先学会用这个工具吧!
ARIMA:全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),是由博克思(Box)和詹金斯(Jenkins)于70年代初提出一著名时间序列预测方法 ,所以又称为box-jenkins模型、博克思-詹金斯法。其中ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。所谓ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。(这是我从百度百科挖过来的-_-)
步骤总结如下:
时间序列预测,ARIMA的模型小结到此为止,到现在为止,关于AR和MA的系数还有季节参数里面的系数选择都没有一点头绪,只能用这种穷举法来一个个找了,费时费力,不过auto.arima貌似很强大,就是给出的系数和网上看来的经验得出的系数有出入,明明是acf拖尾,q应该为0,即AR模型,偏偏就使用了MA,不懂,也没时间仔细研究它的理论,就这样吧。
ARIMA:全称为自回归积分滑动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA),是由博克思(Box)和詹金斯(Jenkins)于70年代初提出一著名时间序列预测方法 ,所以又称为box-jenkins模型、博克思-詹金斯法。其中ARIMA(p,d,q)称为差分自回归移动平均模型,AR是自回归, p为自回归项; MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。所谓ARIMA模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。ARIMA模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA)、自回归过程(AR)、自回归移动平均过程(ARMA)以及ARIMA过程。(这是我从百度百科挖过来的-_-)
步骤总结如下:
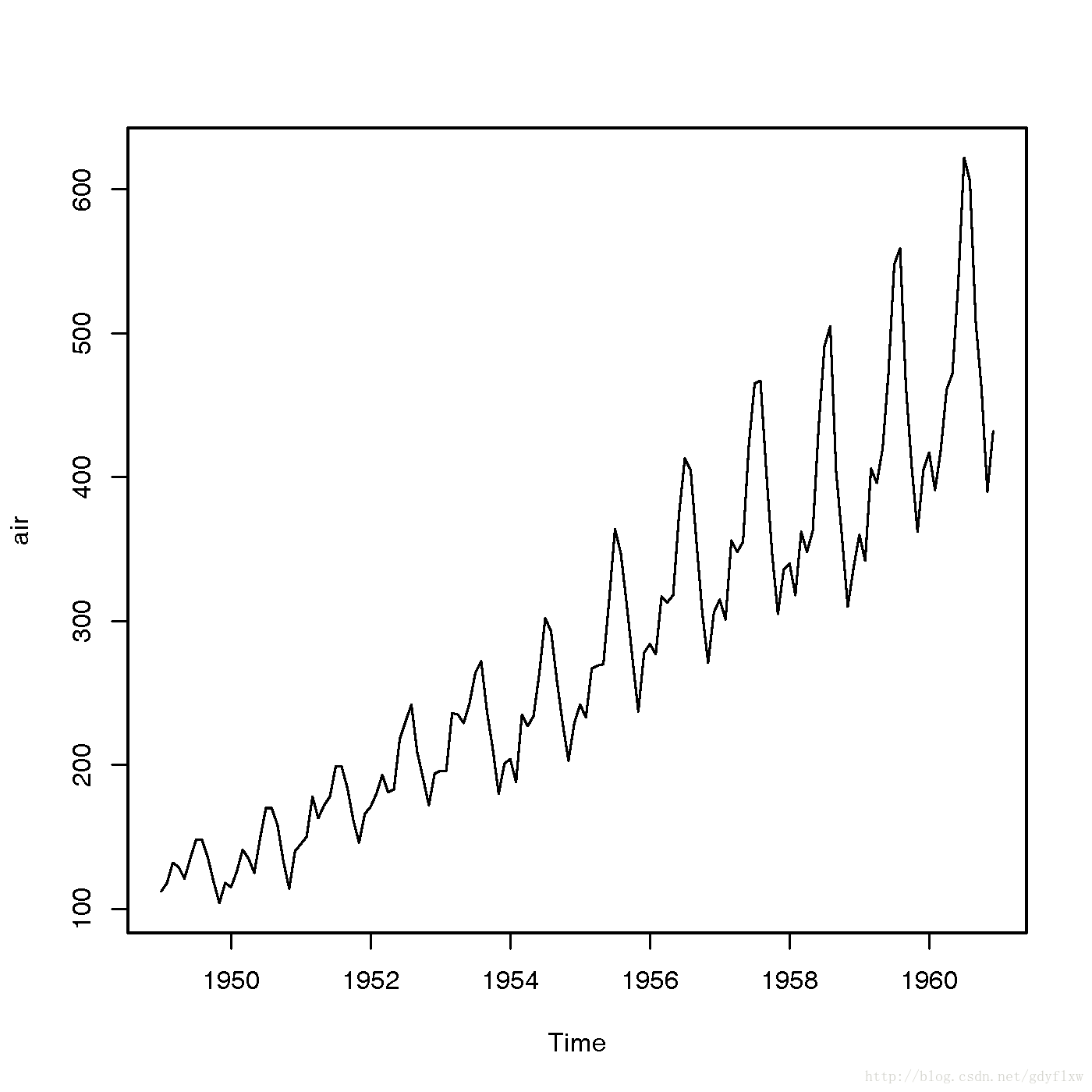
#加载时间序列程序包 library(tseries) library(forecast) #使用该包自带的程序,是指航空乘客的分布 air <- AirPassengers #作这个时间序列的图,通过图作一个直观判断 plot(air)
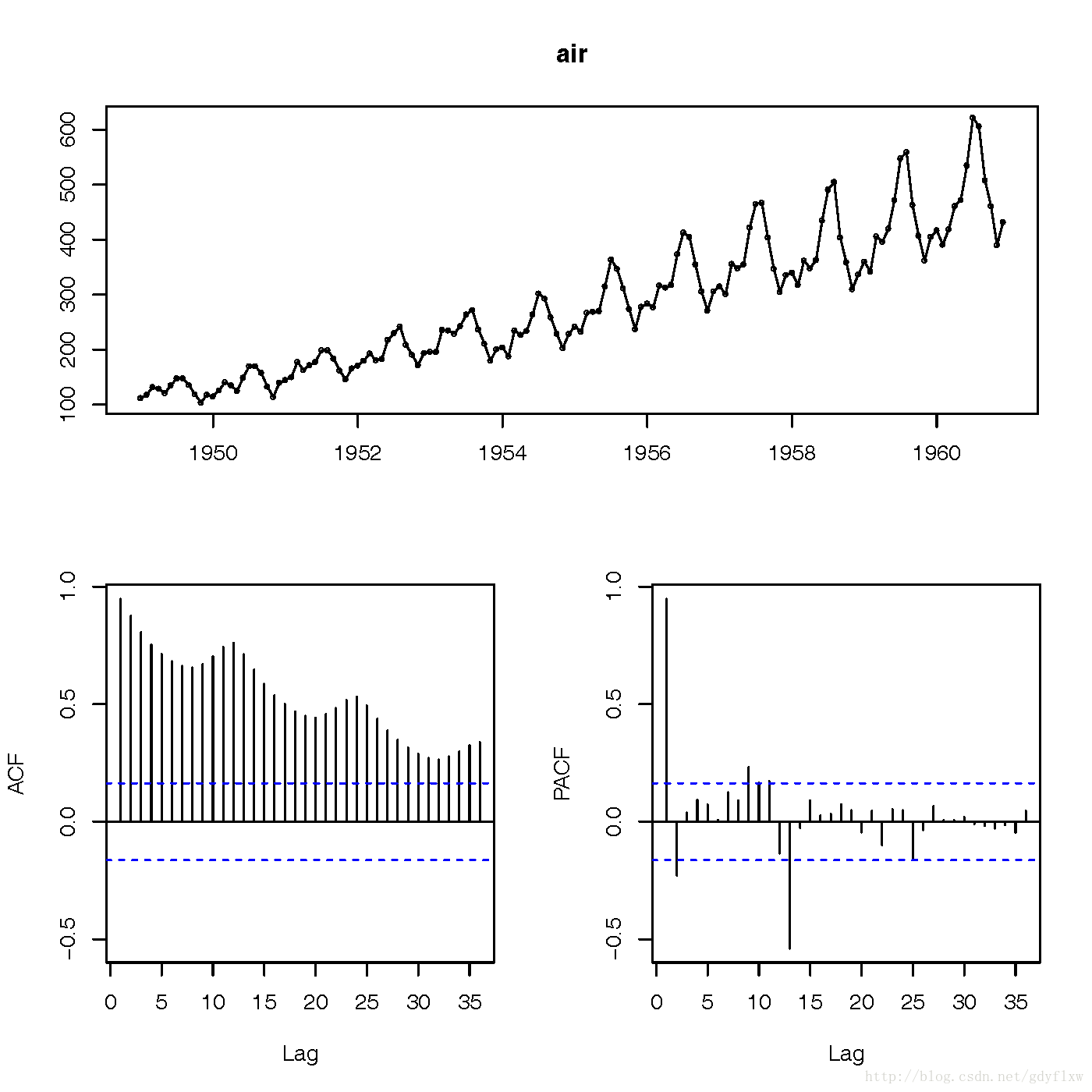
#也可以直接使用tsdisplay来观察,它包含了时序图,以及acf、pacf两个相关图 tsdisplay(air)
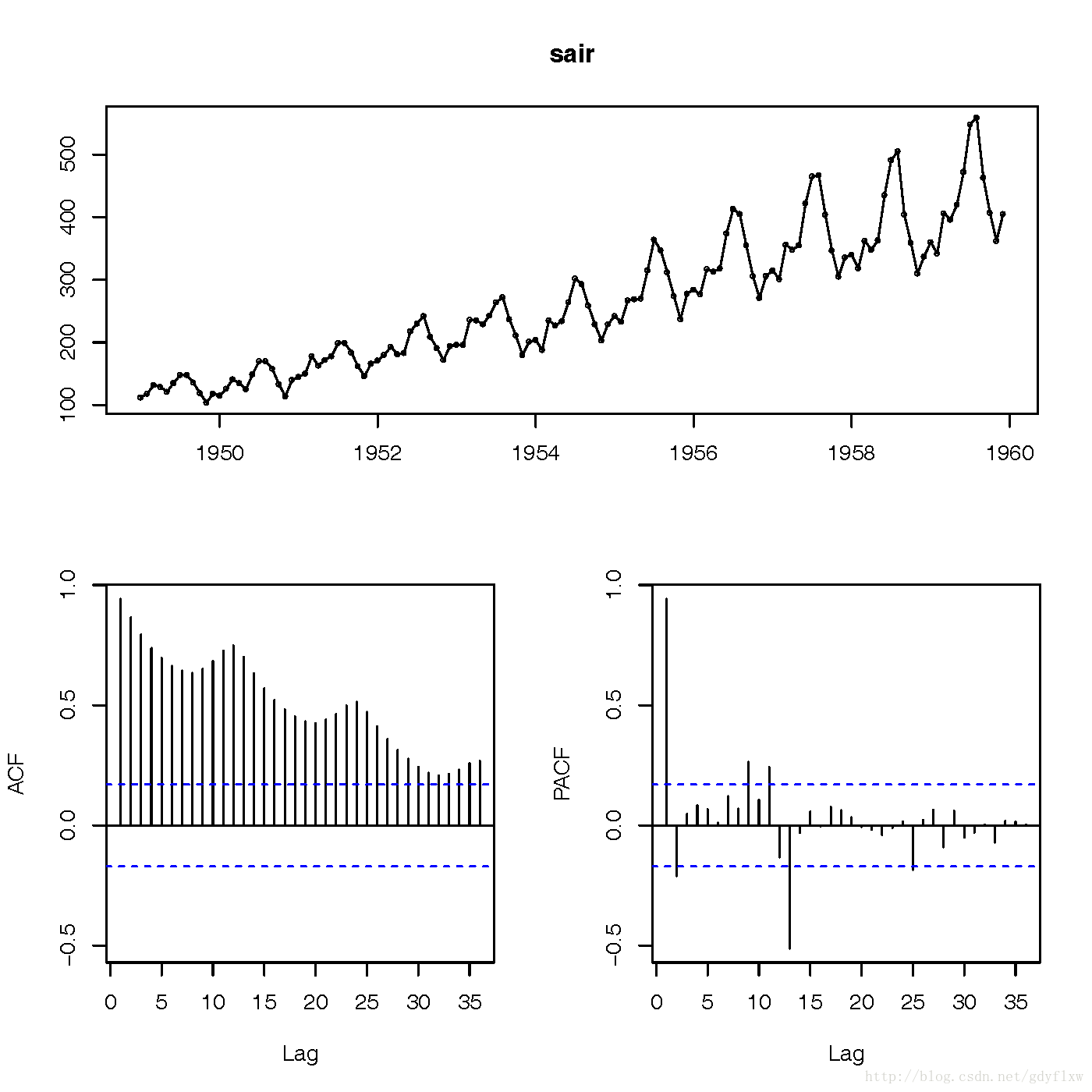
#可以拆掉最后一年来做样本的训练集,再将最后一年做样本的测试集 sair<-ts(as.vector(air[1:132]),frequency=12,start=c(1949,1)) #同样可以看一下拆掉之后的训练集图形 tsdisplay(sair)
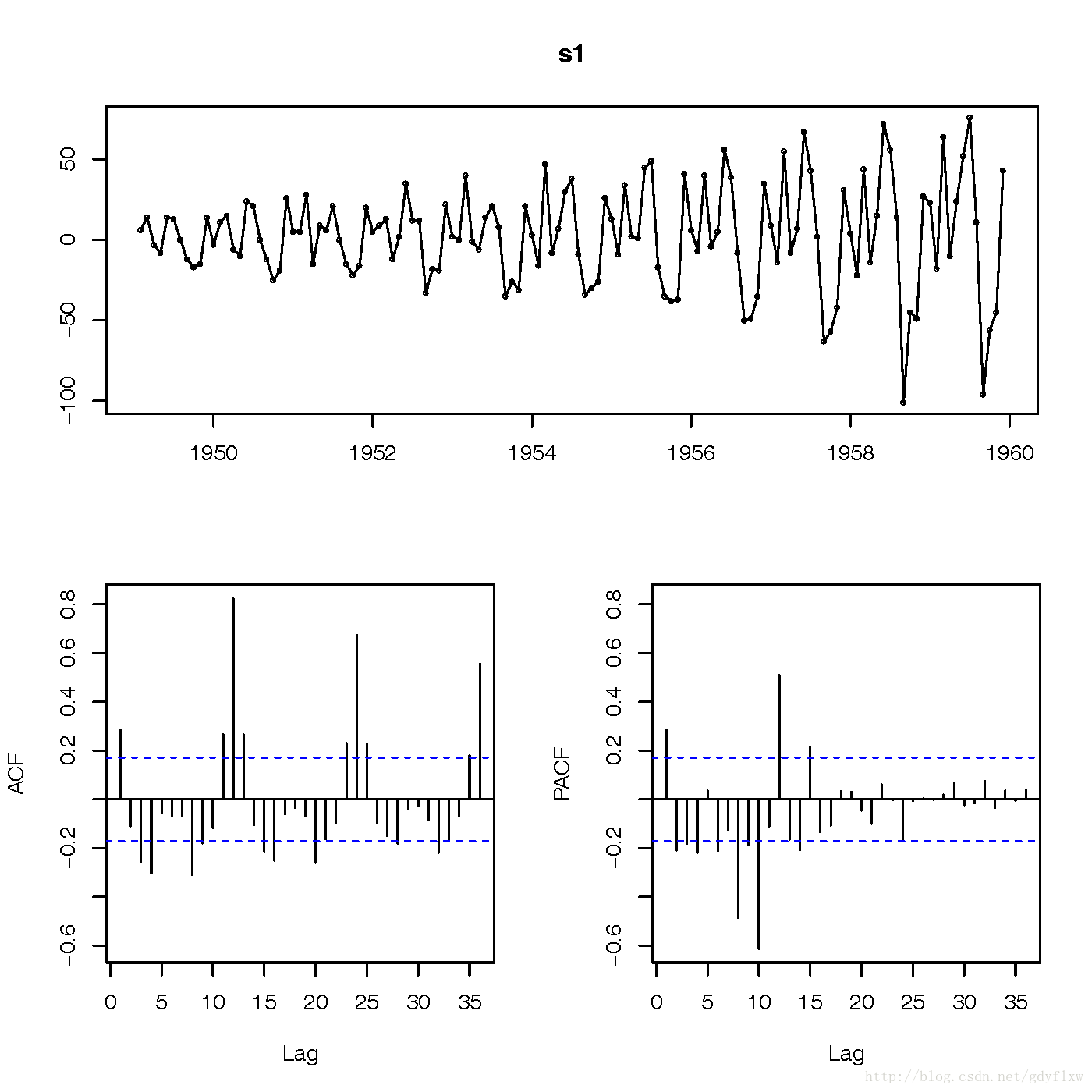
#sair的明显存在一个向上的趋势,用差分方法干掉,先看滞后1次的图形 s1<-diff(sair,1) #从图上看,基本围绕了0在振动,基本平稳,进一步使用adf检验,看一下是否存在单位根(验证平稳性,若存在则不平稳) adf.test(s1) #单位根检验通过(p<0.05,显著拒绝存在单位根),再看一下差分之后的图形。 tsdisplay(s1)
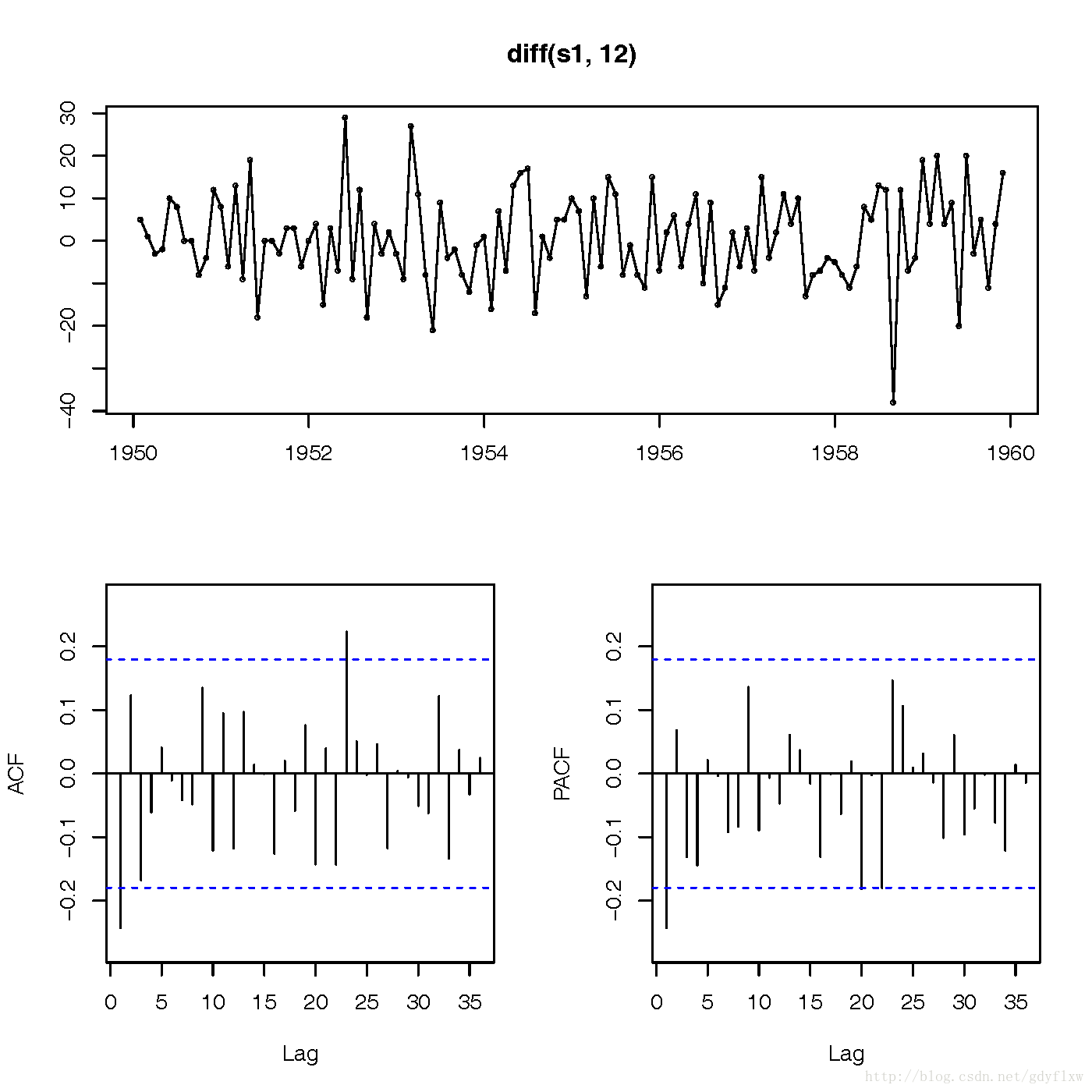
#图形显示acf图存在拖尾,q=0,pacf图超出虚线较多,但从整体上看,从16阶之后截断,而上面的线可以大概看到(1,8,10,12,16)这五个数超出虚线甚多,所以,可以每个都测试一下。形成(1,1,0)(8,1,0),10,1,0),(12,1,0),(16,1,0),然后判断一下各自的AIC值,取最小值即可。 #且acf图存在一个12阶的季节性影响因素,然后通过作滞后12阶的图看一下是否消除 tsdisplay(diff(s1,12))
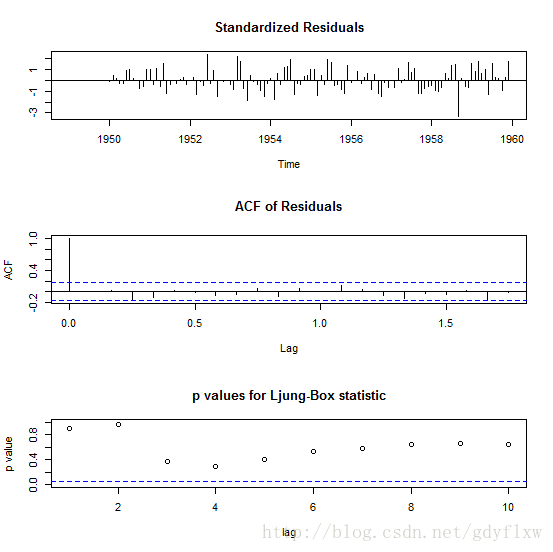
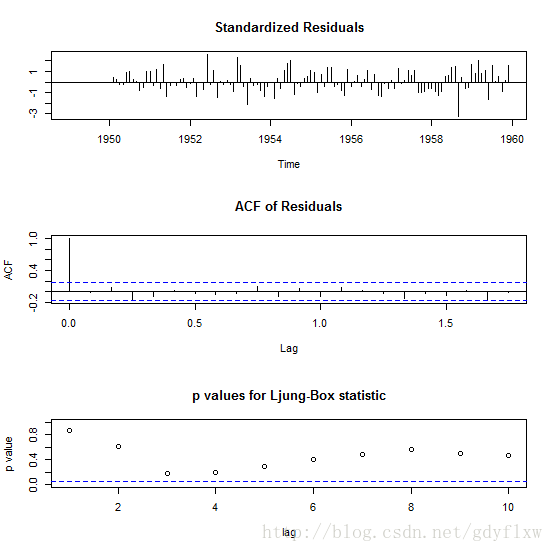
#图形可以看出,已经消除了季节性的影响,所以ARIMA季节参数中周期应该为12,由于季节性图的acf图和pacf上看到最后一个超出虚线的阶数均为1,季度参数可以这么设置(1,1,1)[12] #拟合模型,看一下哪个模型最好,注意,拟合模型使用的data是原始数据,并不是差分之后的数据! arima(sair,order=c(1,1,0),seasonal=list(order=c(1,1,1),period=12))#AIC=899.95 arima(sair,order=c(8,1,0),seasonal=list(order=c(1,1,1),period=12))#AIC=907.17 arima(sair,order=c(10,1,0),seasonal=list(order=c(1,1,1),period=12))#AIC=909 arima(sair,order=c(12,1,0),seasonal=list(order=c(1,1,1),period=12))#AIC=905.38 arima(sair,order=c(16,1,0),seasonal=list(order=c(1,1,1),period=12))#NaNs #从上面的拟合可以看出,选择(1,1,0)(1,1,1)[12]的模型AIC值最小,也可以使用auto.arima函数来自动确定这些参数: auto.arima(sair) #Series: sair #ARIMA(0,1,1)(0,1,0)[12] #Coefficients: # ma1 # -0.2263 #s.e. 0.0900 #sigma^2 estimated as 110.5: log likelihood=-448.34 AIC=900.69 AICc=900.79 BIC=906.24 #auto.arima给出的建议是(0,1,1)(0,1,0)[12],其AIC是900.69,相差不大,可以使用两个方案都看一下预测的结果。 #先进行拟合 fit1<-arima(sair,order=c(1,1,0),seasonal=list(order=c(1,1,1),period=12)) fit2<-arima(sair,order=c(0,1,1),seasonal=list(order=c(0,1,0),period=12)) #然后使用tsdiag看一下各自的结果,图中表明残差标准差基本都在[-1,1]之间,残差的自回归都为0(两虚线内),Ljung-Box检验的p值都在0.05之上,结果不错。 tsdiag(fit1)
tsdiag(fit2)
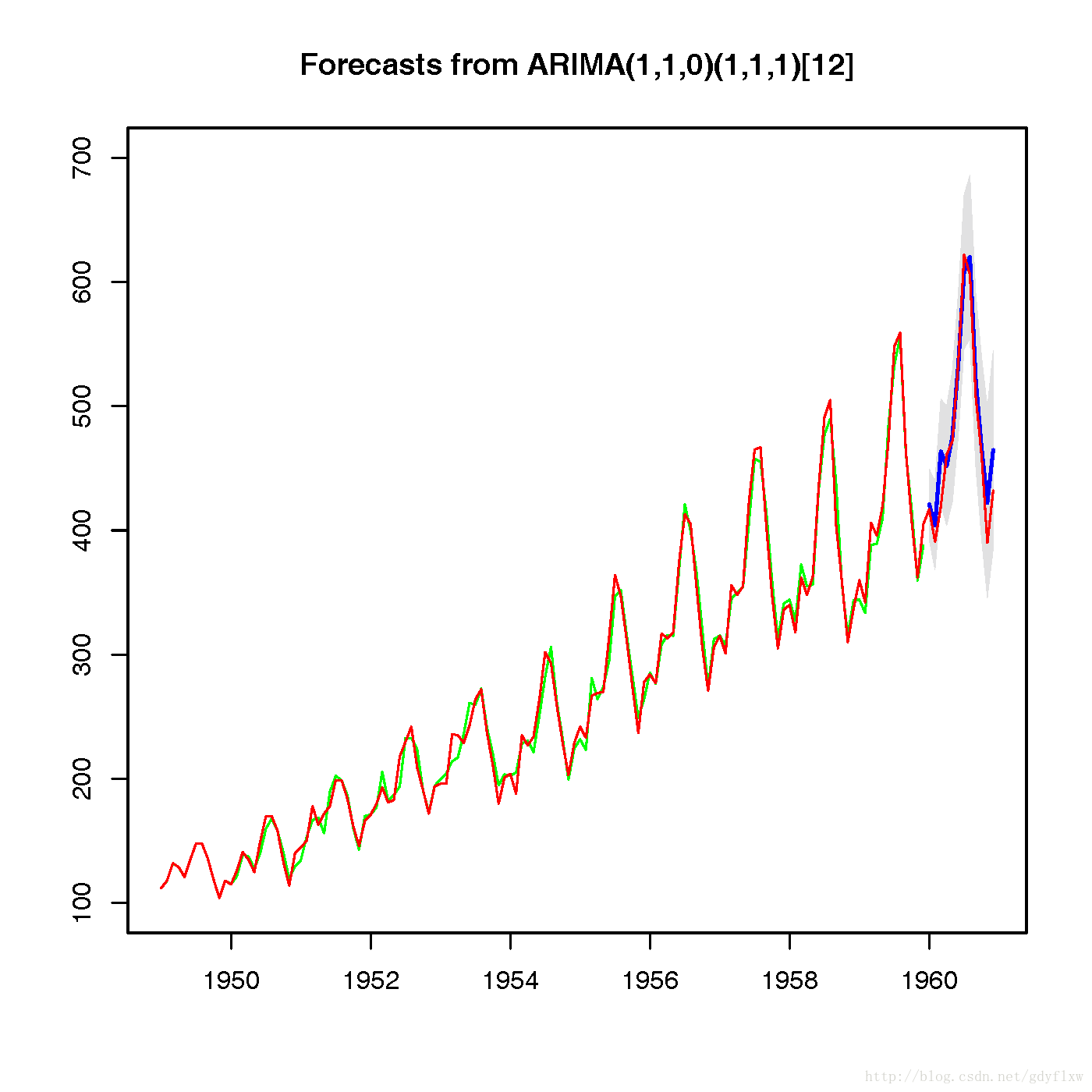
#预测 f.p1<-forecast(fit1,h=12,level=c(99.5)) f.p2<-forecast(fit2,h=12,level=c(99.5)) #先看一下fit1【即(1,1,0)(1,1,1)[12]】的效果 plot(f.p1,ylim=c(100,700)) lines(f.p1$fitted,col="green") lines(air,col="red")
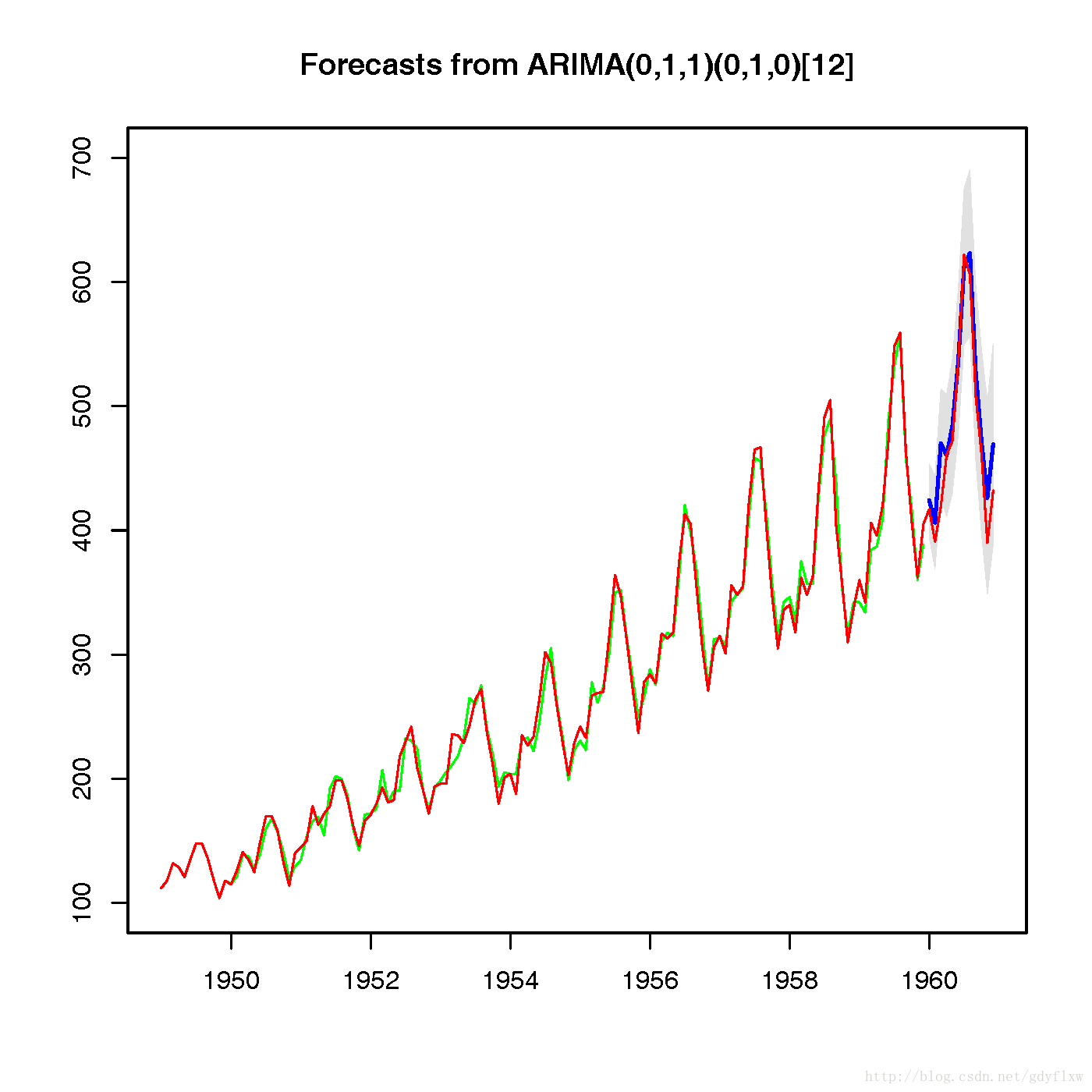
#再看一下fit2【即(0,1,1)(0,1,0)[12]】的效果 plot(f.p2,ylim=c(100,700)) lines(f.p2$fitted,col="green") lines(air,col="red")
#从上面两个图(红色为air数据,绿色为利用sair计算出来的原始数据拟合值,蓝色段为预测值),可以看出,几乎没有区别,而且预测效果也非常好。
时间序列预测,ARIMA的模型小结到此为止,到现在为止,关于AR和MA的系数还有季节参数里面的系数选择都没有一点头绪,只能用这种穷举法来一个个找了,费时费力,不过auto.arima貌似很强大,就是给出的系数和网上看来的经验得出的系数有出入,明明是acf拖尾,q应该为0,即AR模型,偏偏就使用了MA,不懂,也没时间仔细研究它的理论,就这样吧。

相关文章推荐
- R语言与数据分析之九:时间内序列--HoltWinters指数平滑法
- 时间序列处理方法
- C#语言之“string格式的日期时间字符串转为DateTime类型”的方法
- 时间序列常用方法
- (转载)C#语言之“string格式的日期时间字符串转为DateTime类型”的方法
- C#语言之“string格式的日期时间字符串转为DateTime类型”的方法
- C#语言之“string格式的日期时间字符串转为DateTime类型”的方法
- 浅析时间序列用户生命周期的聚类方法
- C语言中时间戳转换成时间字符串的方法
- R(语言)做时间序列(ARIMA)
- matlab对时间序列进行频谱分析时,频率轴的确定方法
- oracle connect by及函数及生成等间隔的时间序列的方法
- 时间序列的归一化方法
- go语言计算两个时间的时间差方法
- SVM分类时间序列问题方法
- R(语言)做时间序列(ARIMA)的案例
- 数学建模高级方法(十):时间序列模型
- C#语言之“string格式的日期时间字符串转为DateTime类型”的方法
- C#语言之“string格式的日期时间字符串转为DateTime类型”的方法
- go语言中时间戳格式化的方法